Infrastructure
Explore the world of modern IT infrastructure: cloud services, server solutions, networking technologies, DevOps workflows, and cybersecurity. Articles, guides, and case studies for IT professionals and engineers — level up your skills with IThub.uno
15 articles in this category
-
С чего начинается тюнинг Nginx в дефолтной конфигурации — это как спортивный автомобиль с заводскими настройками для езды по бездорожью: едет, но не так быстро, как мог бы. Хорошая новость: большинство важных оптимизаций достигается правкой конфига, а не покупкой более мощного железа. Плохая новость: многие "гайды по тюнингу" в интернете — копипаста десятилетней давности, без понимания что и зачем. Параметры для Nginx 1.8 на 2-ядерном сервере копируют на 32-ядерный продакшен под highload — и уди
-
Введение: PostgreSQL в продакшене — другой зверь Поднять PostgreSQL локально — просто. Запустить его в продакшене под реальной нагрузкой так, чтобы он не падал, не тормозил и не раздувался до потери диска — это уже инженерия. PostgreSQL 16, 17 и 18 принесли серьёзные улучшения производительности: логическая репликация стала намного мощнее, параллельные запросы умнее, планировщик научился большему. Но дефолтная конфигурация по-прежнему рассчитана на «запустить на ноутбуке с 256 МБ RAM», а не на p
-
Зачем специализированная БД для временных рядов Технологические данные — это всегда временной ряд: температура каждую секунду, давление каждые 100 мс, состояние оборудования каждые 10 мс. PostgreSQL или MySQL могут хранить такие данные. Но при миллионах записей в день начинаются проблемы. Почему реляционные БД плохо справляются: Индексы B-Tree неэффективны для временных запросов ("за последний час") Запись строк в таблицу с индексами — медленно при высоком темпе GROUP BY time_interval требует
-
Introduction: Why SysVinit Died and What Systemd Fixed Imagine a chef cooking dinner for 10 guests but making each dish completely from scratch, one at a time — starting the salad only after the soup is fully served. That's essentially how SysVinit worked: it started services one by one, in a fixed order, regardless of whether they were actually dependent on each other. As Linux systems grew more complex, this became a serious bottleneck: Slow boot times. Service A waits for Service B to finish,
-
Введение: Почему SysVinit умер, и при чём тут Systemd Представьте себе повара, который готовит ужин на 10 человек, но строго по одному блюду за раз — сначала суп, потом только начинает нарезать салат. Именно так работала старая система инициализации SysVinit: запускала службы строго по одной, в заранее заданном порядке. Независимо от того, зависят ли они друг от друга. С усложнением Linux-систем это стало болью: Медленная загрузка. Служба A ждёт завершения службы B, даже если между ними нет ника
-
Введение Корректный запуск процессов внутри контейнера — одна из ключевых тем при разработке Docker-образов. Формально всё описано в документации Docker, однако на практике регулярно возникают неоднозначные ситуации: контейнер не останавливается корректно; сигналы не доходят до приложения; появляются zombie-процессы; PID 1 ведёт себя неожиданно. В этой статье разберём: Разницу между ENTRYPOINT и CMD. Отличие exec и shell форм. Почему критически важно, какой процесс имеет PID 1. Как правил
-
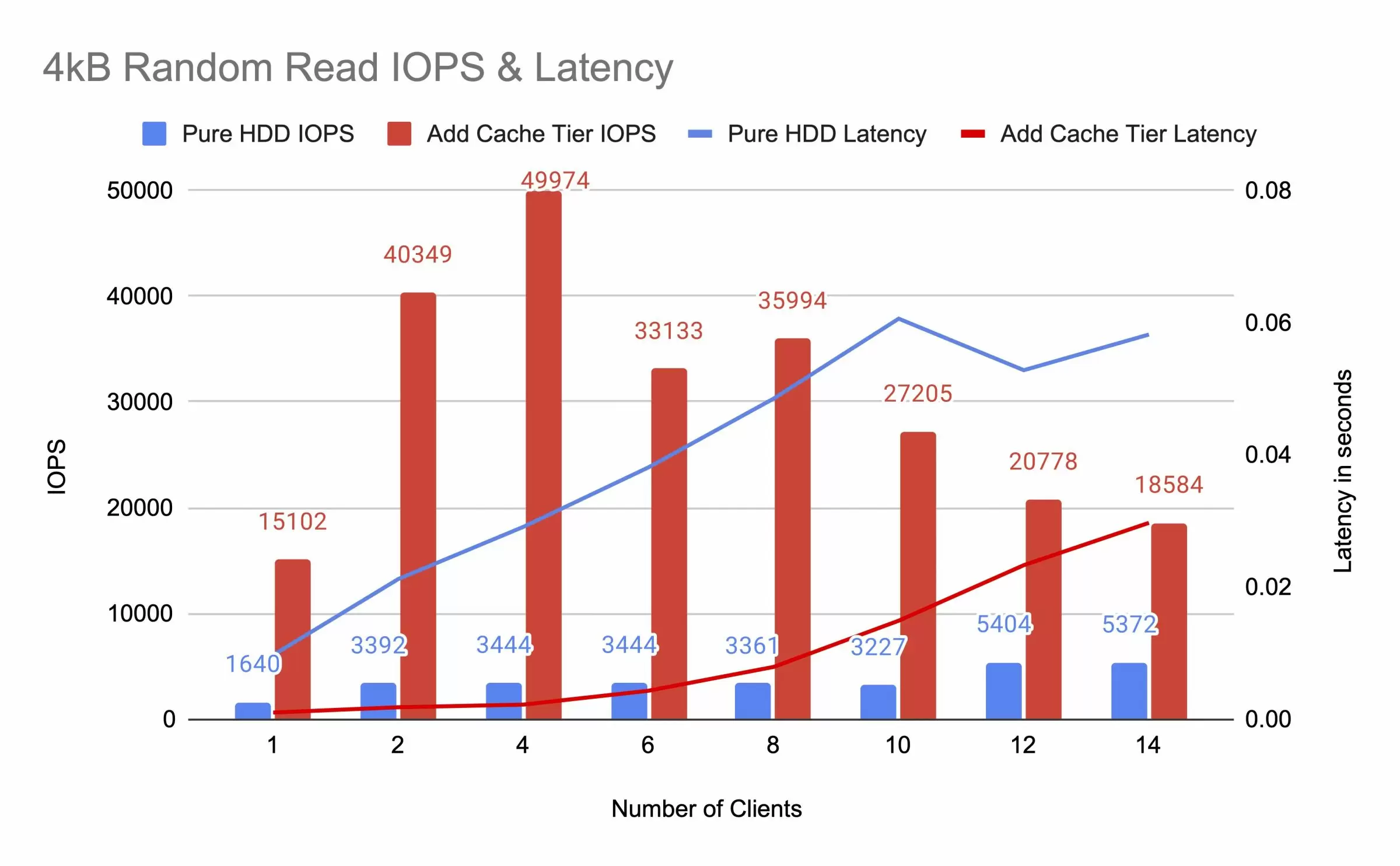
Кластер работает. Теперь начинается настоящая работа: выжать из него максимум производительности, не потерять данные при апгрейде и знать, что делать когда (не «если») что-то сломается. Часть 1: Планирование железа — правильный старт Перед тем как тюнить — убедитесь что железо подобрано правильно. Никакой тюнинг не исправит плохую архитектуру. Сети: разделяйте публичную и кластерную Худшее что можно сделать — смешать пользовательский трафик и репликацию в одну сеть. Публичная сеть (client networ
-
В прошлой статье мы разобрались с теорией — теперь руки в землю. Будем разворачивать минимальный продакшн-кластер Ceph Tentacle (20.2.x) через cephadm — официальный инструмент оркестровки, который умеет всё: установку, конфигурирование, обновление, добавление узлов. Что мы будем строить Минимальная продакшн-конфигурация: ┌─────────────────────────────────────────────────────┐ │ ceph-node1 │ ceph-node2 │ ceph-node3 │ │ │ │ │ │ MON +
-
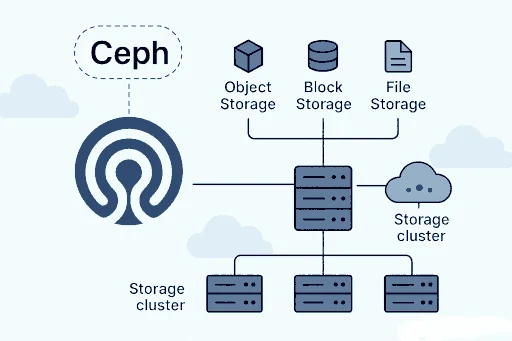
Почему Ceph, а не просто NAS или SAN? Представьте ситуацию: у вас 50 серверов, каждый с несколькими терабайтами данных, виртуальные машины, S3-хранилище для бэкапов, общий файловый ресурс для кластера Kubernetes — и всё это нужно хранить надёжно, быстро и так, чтобы смерть одного (или нескольких) серверов не привела к потере данных и даунтайму. Традиционные решения здесь ломаются. NAS — единая точка отказа. SAN — дорого, сложно, проприетарно. RAID — не масштабируется за пределы одной машины. Cep
-
Резервное копирование в Linux: стратегии и инструменты Правило 3-2-1 Любая стратегия резервного копирования должна начинаться с правила 3-2-1: 3 копии данных 2 разных типа носителей 1 копия вне офиса Rsync: умное инкрементальное копирование #!/usr/bin/env bash # Скрипт резервного копирования с ротацией BACKUP_SOURCE="/var/www" BACKUP_DEST="/mnt/backup" RETAIN_DAYS=30 DATE=$(date +%Y%m%d_%H%M%S) # Создаём снэпшот через hard links (не дублируем неизменённые файлы) rsync -avz --delete \ --
-
«Как вы узнали о проблеме?» — «Пожаловались пользователи» — так работать нельзя. Правильный мониторинг означает, что вы знаете о проблеме раньше, чем её заметят пользователи. Эта статья о построении полноценного стека мониторинга для Linux-инфраструктуры: от сбора метрик до умных алертов. Архитектура: что и зачем Серверы Мониторинг Визуализация [node_exporter] ──────► [Prometheus] ──────► [Grafana] [php-fpm_exporter] │ │ [mysql_exporter]
-
Введение Перенос базы данных PostgreSQL — задача непростая, особенно для больших проектов. Часто это один из самых крупных и ответственных процессов для разработчиков и администраторов. Основные сценарии переноса включают: обновление до новой версии PostgreSQL; перенос базы на другой сервер или хостинг; миграция с минимальным временем простоя. В зависимости от размера базы и ограничений инфраструктуры есть три основных подхода. 1. Перенос с помощью pg_dump и pg_restore pg_dump позволяет созда
-
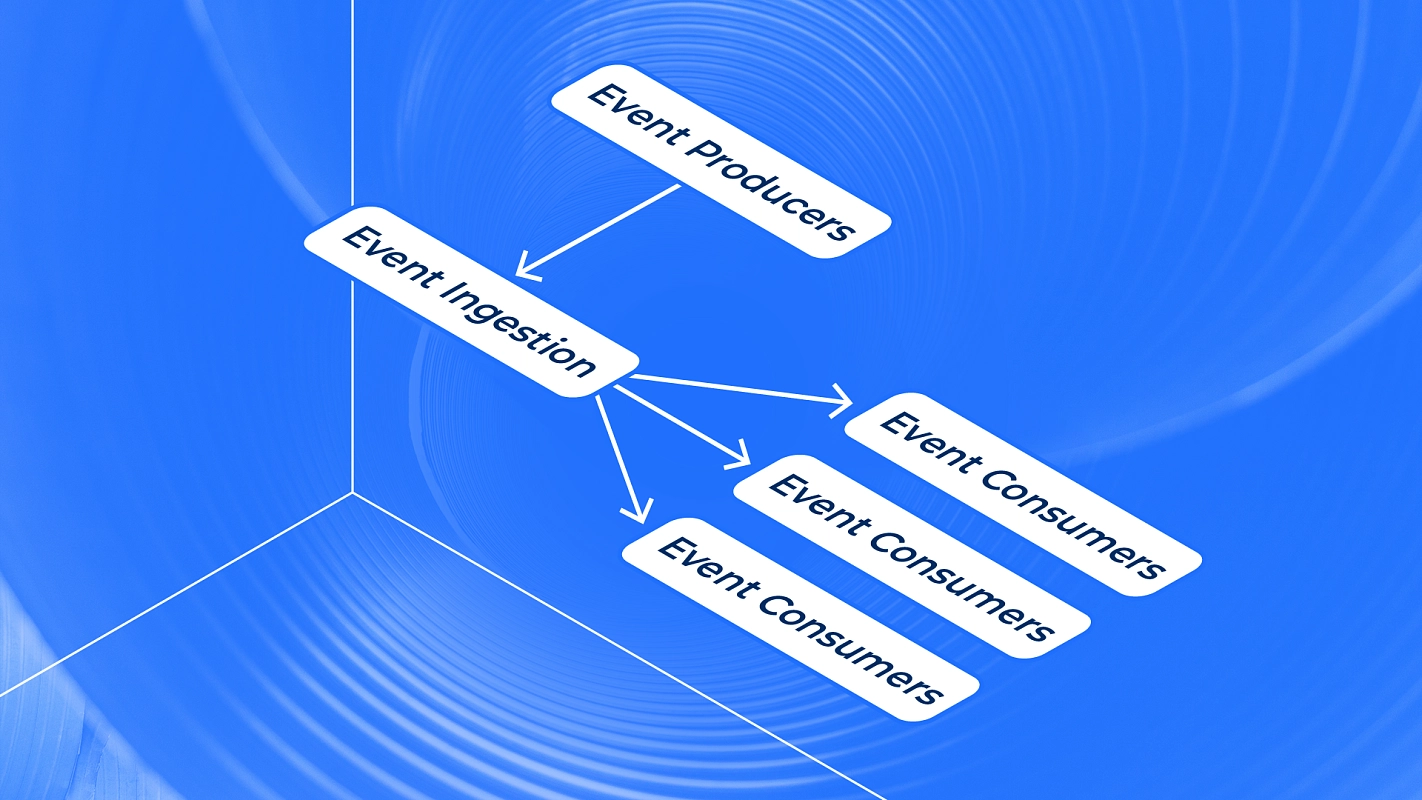
Введение Событийно-ориентированные архитектуры (EDA) на бумаге выглядят идеальными: продюсеры и консюмеры отделены друг от друга, потоки асинхронны, а система легко масштабируется. Но реальность часто оказывается сложнее. Представьте распродажу на «Чёрную пятницу»: ваша система обработки платежей получает в 5 раз больше трафика. В этот момент серверлесс-функции запускаются «холодно», очереди SQS переполняются, а DynamoDB начинает троттлить. Результат: сбои заказов клиентов. И это не гипотетическ
-
Ошибки в сетевой инфраструктуре: от планирования до эксплуатации Ошибки, которые могут допустить IT-специалисты, практически неисчерпаемы. Некоторые из них незаметны обычным пользователям — например, отсутствие настроенного журналирования событий. Даже взлом, произошедший из-за этого, может остаться незамеченным, пока об этом не напишут в новостях. Другие ошибки становятся очевидными сразу: проблемы в работе сети замечает каждый сотрудник. В этой статье разберём наиболее частые ошибки при проект
-
1. Сколько соединений может обработать один воркер В NGINX каждый воркер‑процесс способен обслуживать определённое число одновременных соединений. Это задаётся директивой: worker_connections 1024; Здесь учитываются все дескрипторы, включая клиентские соединения и прокси‑сессии к бэкендам. По умолчанию NGINX использует 768 соединений, но для серьёзных нагрузок лучше поднять до 1024+, не забывая про лимит открытых файлов в ОС (ulimit -n). Расчёт максимального числа клиентов: max_clients=worker_p