
IThub
Administrators
-
Joined
-
Last visited
Everything posted by IThub
-
 Коллеги, всем привет! iLO 2 Activation Key: 372CG-JCDSP-ZXKL9-WVBZ9-SJHHM iLo2/iLO4 Advanced License Keys: 35DPH-SVSXJ-HGBJN-C7N5R-2SS4W 35SCR-RYLML-CBK7N-TD3B9-GGBW2Делюсь ключиками для iLo, чтоб вам былы доступны все функции вашего сервера HP
Коллеги, всем привет! iLO 2 Activation Key: 372CG-JCDSP-ZXKL9-WVBZ9-SJHHM iLo2/iLO4 Advanced License Keys: 35DPH-SVSXJ-HGBJN-C7N5R-2SS4W 35SCR-RYLML-CBK7N-TD3B9-GGBW2Делюсь ключиками для iLo, чтоб вам былы доступны все функции вашего сервера HP -
В общем в очередной раз лазил в сети в поисках образа для обновления платформы HP Gen9 и нашел таки! Вот список, чего там есть: P52574_001_spp-Gen9.1-Gen9SPPGen91.2022_0822.4.iso - сам основной образ для пакетного обновления платформы P69223_001_Gen9.4HotfixBundle-Gen9PPHotFixBundleGen9.4.2.7z - самый свежий на сегодня фикс Ну и по мелочи, прошивки... Делюсь ссылкой на все файлы с вами ССЫлка на скачивание
-
Поймал программист золотую рыбку: — Загадывай желание! — Хочу, чтобы Python никогда не падал в продакшне! — Слушай, лучше мир во всём мире — оно реальнее. Построили полностью роботизированный завод. Экскурсия по цехам: — Здесь роботы на Unix. Работают как часы уже 15 лет. — Здесь на MS-DOS. Немного устарело, но стабильно. — А вот здесь — на Windows 98. Прошу всех надеть скафандры и не делать резких движений. Новый карманный компас на Windows CE. На экране: «Север не найден. Повторить поиск? Да / Позже» Звонок на радио: — Поставьте, пожалуйста, ту песню Пугачёвой — про зависший Windows! — Хм... не припомню такой. Можете напеть? — Ну там припев: «Кликну — а в ответ тишина, снова я осталась одна. Сильная женщина плачет у Окна» Пресс-конференция NASA по поводу сбоя компьютера на МКС: — Скажите, МКС работает под Windows? — А вы вообще видели, чтобы под Windows хоть что-то летало? Умер Билл Гейтс. Архангел Пётр: — Что скажешь в своё оправдание? — Я осчастливил всё человечество! — Это каким же образом? — Ну... умер же. Установка Windows. Приветственный экран: «Добро пожаловать. Откиньтесь в кресле, расслабьтесь, закройте глаза — и молитесь»
-
У меня есть примерно 450 000 шуток про BGP 📡 Шутки про RAID почти всегда избыточны 💾 Шутку про 127.0.0.1 каждый может пошутить себе сам 🖥️ Я знаю отличную шутку про UDP, но не факт, что она до вас дойдёт 📦 Жаль, что шутка про Fault Tolerance не может состоять больше чем из одного слова ⚙️ Шутки про IPv6 плохи тем, что их мало кому можно рассказать 🌍 А вы слышали шутку про ICMP? 📢 Самое клёвое в шутках про rsync — её рассказывают только если вы не слышали её до этого 🔁 Шутки про RFC 1918 можно рассказывать только своим 🏠 Я бы рассказал отличную шутку про Token Ring, но сейчас не моя очередь 🎟️ Про DWDM шутят сразу несколькими голосами 🎙️ DHCP шутки смешны, только если их рассказывает один человек 🧾 Подождите все, я расскажу шутку о сети типа «шина» 🚌 Шутки про SSH-1 и SSH-2 несовместимы между собой 🔐 Из-за одного, кто зевнул, придётся заново рассказывать шутку про frame relay в топологии point-to-multipoint 🔄 Я знаю отличную шутку про TCP, но если она не дойдёт — повторю 📬 IGMP шутка; пожалуйста, передай дальше 📡 Шутки про IPv4 уже закончились? 🤔 Шутки про MAC-адрес могут не дойти до тёзок 🏷️ Я сейчас расскажу отличную шутку про VPN, но её поймёт только один 🔒 PPP шутки всегда рассказываются только между двумя людьми 🤝 Про Schema Master шутит только один в этом лесу 🌲 Лучшее в шутках про проприетарные протоколы — это УДАЛЕНО 🚫 Фрагментированные шутки… ✂️ …всегда рассказываются… 📦 …по кусочкам. 🧩 У кого есть кабель? Есть смешная шутка про RS-232 и полусмешная про RS-485 🔌 DNS-сервер не понял шутку про DDoS и ему её стали пересказывать сто тысяч раз в секунду 🌪️ Я подожду Антона и расскажу классную шутку про QoS ⏳ Самое лучшее в шутках про BitTorrent — они могут идти в любом порядке 🧲 К шутке про SCTP вначале должны все подготовиться 📋 Я бы рассказал шутку про CSRF, если бы ты САМ только что этого не сделал 🕵️ Нет ничего забавного в шутках про определение MTU… 📏 Шутки про 10/100/1000BASE-T вряд ли услышат с расстояния больше 100 📶 Жаль, никто не помнит шутки про IPX 🗂️ А кто знает отличную шутку про ARP? 🧠 Шутки про HDLC обычно не понимают те, кто знает другие шутки про HDLC 🔄 Только что специально для сообщества пришла шутка про мультикаст 📣 И ГОСТ, и ISO согласны, что есть 7 уровней рассказывания шуток 📚 Министерство обороны США понимает только четыре уровня шуток 🪖 Вы уже слышали шутку про Jumbo фреймы? Она о-о-очень длинная 📏 Шутки про MitM любят все. Ну кроме Алисы и Боба 😏 А шутки про STP вам кто-нибудь рассказывал? 🌳 Я сейчас всем расскажу шутку про бродкаст 📢 Настало время рассказать шутку про NTP ⏰ Помню времена, когда шутка про модем пшшшшшш… 📞 Про MTU тоже есть классная 📐 <шутка><смешная/><про>XML</про></шутка> 🧾 Шутки про шутки про шутки часто звучат в туннелях 🚇 У кого есть пароли — приходите за шутками про RADIUS 🔑 Шутки про IPSec надо говорить, кому их рассказываешь 🛡️ Шутка про Е3 — это 30 одинаковых шуток про Е1 и ещё две для тех, кто в теме 📊 Шутки про FSMO роли могут шутить не более пяти человек 👑 Единственная проблема в шутках про Token Ring — если кто-то начнёт говорить одновременно с вами, обе шутки обрываются 🎙️
-
 1. Зачем нужна PSRAM в ESP32Микроконтроллеры семейства ESP32 имеют сотни килобайт встроенной SRAM, размещённой на том же кристалле, что и CPU, периферия и контроллеры. Для задач вроде: обработки графики (LVGL, дисплеи), буферизации аудио, работы с большими JSON, сетевых стеков, ML-моделей, этого объёма часто недостаточно. Поэтому архитектура предусматривает подключение внешней PSRAM (Pseudo-Static RAM) — псевдо-статической оперативной памяти, которая расширяет доступный heap. 2. Что такое PSRAM2.1 ТерминологияВ документации Espressif используются как взаимозаменяемые: PSRAM SPI RAM SPIRAM Во всех случаях речь идёт об одном типе внешней памяти. 2.2 Почему «Pseudo-Static»PSRAM сочетает в себе: Внутренняя структура: DRAMЯчейки динамические (как в DRAM) Требуется refresh Внешний интерфейс: как у SRAMВстроенная логика регенерации CPU работает с ней как с обычной RAM Внешний контроллер refresh не нужен Именно поэтому — Pseudo-Static. 3. Аппаратная архитектура доступа к PSRAM3.1 ПодключениеPSRAM подключается: через SPI / QSPI / OPI по той же шине, что и Flash с отдельной линией Chip Select В модулях типа WROVER чип PSRAM обычно установлен внутри металлического экрана. В новых сериях возможна: in-package PSRAM (в одном корпусе с SoC) но архитектурно она остаётся «внешней» 3.2 Как CPU обращается к PSRAMДоступ НЕ прямой. Схема: CPU → Cache → MMU → SPI → PSRAM Алгоритм:CPU обращается к виртуальному адресу. MMU отображает его в физический адрес PSRAM. Cache: cache hit → мгновенно cache miss → чтение через SPI В новых сериях используется write-back cache. 3.3 Главное ограничениеPSRAM всегда медленнее внутренней SRAM, потому что: последовательная шина работа через кэш латентность SPI Следствие: стек задач и DMA-буферы по умолчанию остаются во внутренней памяти. 4. Важные аппаратные ограничения4.1 НапряжениеPSRAM бывает: 1.8 В 3.3 В Оно должно совпадать с Flash. Выбор задаётся: strapping pins eFuse Ошибка может: отключить память повредить чип 4.2 DMAНа старых ESP32: DMA напрямую с PSRAM невозможен На новых сериях: возможен но требует контроля когерентности кэша 4.3 Стек FreeRTOSПо умолчанию: стек задач → внутренняя RAM Технически можно разместить в PSRAM (через xTaskCreateStatic), но это не рекомендуется. 5. Особенности разных серий ESP325.1 Классический ESP32QSPI (4 линии) максимум 4 МБ отображаемого окна кэш 32 КБ на ядро при 8 МБ требуется Himem API (bank switching) Поддерживаются режимы MMU: Normal Low-High Even-Odd DMA напрямую не работает. 5.2 ESP32-S2независимые ICache и DCache до 10.5 МБ виртуального адресного пространства возможно выполнение кода из PSRAM настраиваемый размер кэша 5.3 ESP32-S3Quad / Octal SPI поддержка XTS-AES до 32 МБ отображаемого пространства общий кэш для двух ядер Octal PSRAM заметно быстрее Quad. 5.4 ESP32-C5 и ESP32-C61поддержка PSRAM есть до 32 МБ отображения доступ через кэш и GDMA Ранние C-серии (C2, C3, C6) PSRAM не поддерживают. 5.5 ESP32-P4Наиболее производительная архитектура: до 64 МБ PSRAM интерфейсы OPI и HPI двухуровневый кэш (L1 + L2) частоты до 200 МГц аппаратное шифрование 6. Использование PSRAM в ESP-IDFОсновной компонент: esp_psram В новых версиях ESP-IDF его нужно явно добавить в зависимости: idf_component_register( SRCS "main.c" INCLUDE_DIRS "." REQUIRES esp_psram )После этого появляется меню: Component config → ESP PSRAM7. Ключевые параметры menuconfig7.1 CONFIG_SPIRAM_BOOT_INITАвтоматическая инициализация при старте. Рекомендуется включать. 7.2 CONFIG_SPIRAM_IGNORE_NOTFOUNDПозволяет загружаться без PSRAM. Полезно для универсальных прошивок. 7.3 CONFIG_SPIRAM_MEMTESTТест памяти при старте. ≈ 1 секунда на 4 МБ. 7.4 CONFIG_SPIRAM_USEОпределяет стратегию интеграции: 1) MEMMAPПросто отображение в адресное пространство. Вы сами управляете памятью. 2) CAPS_ALLOCИспользование через: heap_caps_malloc(size, MALLOC_CAP_SPIRAM);Наиболее управляемый способ. 3) MALLOC (по умолчанию)PSRAM объединяется с общей кучей. malloc() автоматически выбирает регион. 7.5 CONFIG_SPIRAM_MALLOC_ALWAYSINTERNALПорог (по умолчанию 16 КБ): меньше → внутренняя RAM больше → PSRAM 7.6 CONFIG_SPIRAM_MALLOC_RESERVE_INTERNALРезервирует внутреннюю память под: DMA стеки задач критические участки Очень важная опция для стабильности. 7.7 Перенос кода и данныхCONFIG_SPIRAM_FETCH_INSTRUCTIONS CONFIG_SPIRAM_RODATA CONFIG_SPIRAM_XIP_FROM_PSRAM Позволяют: выполнять код из PSRAM разгрузить Flash ускорить систему (в Octal-режиме) 8. API esp_psramФункции: esp_psram_init(); esp_psram_is_initialized(); esp_psram_get_size();Практически используется только: esp_psram_get_size();9. Выделение памяти9.1 Автоматический режимvoid *ptr = malloc(size);Работает при CONFIG_SPIRAM_USE_MALLOC. 9.2 Явное выделение в PSRAMvoid *ptr = heap_caps_malloc(size, MALLOC_CAP_SPIRAM);Освобождение — обычный free(). 9.3 Когда использовать PSRAMПодходит для: больших JSON framebuffer аудиобуферов кешей временных массивов Не подходит для: DMA ISR стека задач структур с высокой частотой доступа 10. Практическая стратегияОптимальный подход для production: CONFIG_SPIRAM_USE_CAPS_ALLOC CONFIG_SPIRAM_MALLOC_RESERVE_INTERNAL WiFi/LWIP → в PSRAM Стек, DMA → внутренняя RAM Это даёт предсказуемую производительность. 11. ИтогPSRAM — это: дешёвый способ расширить RAM возможность работать с графикой и ML разгрузка внутренней памяти Но: – всегда медленнее внутренней SRAM – требует грамотной конфигурации – может вызывать проблемы когерентности Для серьёзных проектов рекомендуется: ESP-IDF ручное управление аллокацией контроль DMA-буферов резерв внутренней памяти
1. Зачем нужна PSRAM в ESP32Микроконтроллеры семейства ESP32 имеют сотни килобайт встроенной SRAM, размещённой на том же кристалле, что и CPU, периферия и контроллеры. Для задач вроде: обработки графики (LVGL, дисплеи), буферизации аудио, работы с большими JSON, сетевых стеков, ML-моделей, этого объёма часто недостаточно. Поэтому архитектура предусматривает подключение внешней PSRAM (Pseudo-Static RAM) — псевдо-статической оперативной памяти, которая расширяет доступный heap. 2. Что такое PSRAM2.1 ТерминологияВ документации Espressif используются как взаимозаменяемые: PSRAM SPI RAM SPIRAM Во всех случаях речь идёт об одном типе внешней памяти. 2.2 Почему «Pseudo-Static»PSRAM сочетает в себе: Внутренняя структура: DRAMЯчейки динамические (как в DRAM) Требуется refresh Внешний интерфейс: как у SRAMВстроенная логика регенерации CPU работает с ней как с обычной RAM Внешний контроллер refresh не нужен Именно поэтому — Pseudo-Static. 3. Аппаратная архитектура доступа к PSRAM3.1 ПодключениеPSRAM подключается: через SPI / QSPI / OPI по той же шине, что и Flash с отдельной линией Chip Select В модулях типа WROVER чип PSRAM обычно установлен внутри металлического экрана. В новых сериях возможна: in-package PSRAM (в одном корпусе с SoC) но архитектурно она остаётся «внешней» 3.2 Как CPU обращается к PSRAMДоступ НЕ прямой. Схема: CPU → Cache → MMU → SPI → PSRAM Алгоритм:CPU обращается к виртуальному адресу. MMU отображает его в физический адрес PSRAM. Cache: cache hit → мгновенно cache miss → чтение через SPI В новых сериях используется write-back cache. 3.3 Главное ограничениеPSRAM всегда медленнее внутренней SRAM, потому что: последовательная шина работа через кэш латентность SPI Следствие: стек задач и DMA-буферы по умолчанию остаются во внутренней памяти. 4. Важные аппаратные ограничения4.1 НапряжениеPSRAM бывает: 1.8 В 3.3 В Оно должно совпадать с Flash. Выбор задаётся: strapping pins eFuse Ошибка может: отключить память повредить чип 4.2 DMAНа старых ESP32: DMA напрямую с PSRAM невозможен На новых сериях: возможен но требует контроля когерентности кэша 4.3 Стек FreeRTOSПо умолчанию: стек задач → внутренняя RAM Технически можно разместить в PSRAM (через xTaskCreateStatic), но это не рекомендуется. 5. Особенности разных серий ESP325.1 Классический ESP32QSPI (4 линии) максимум 4 МБ отображаемого окна кэш 32 КБ на ядро при 8 МБ требуется Himem API (bank switching) Поддерживаются режимы MMU: Normal Low-High Even-Odd DMA напрямую не работает. 5.2 ESP32-S2независимые ICache и DCache до 10.5 МБ виртуального адресного пространства возможно выполнение кода из PSRAM настраиваемый размер кэша 5.3 ESP32-S3Quad / Octal SPI поддержка XTS-AES до 32 МБ отображаемого пространства общий кэш для двух ядер Octal PSRAM заметно быстрее Quad. 5.4 ESP32-C5 и ESP32-C61поддержка PSRAM есть до 32 МБ отображения доступ через кэш и GDMA Ранние C-серии (C2, C3, C6) PSRAM не поддерживают. 5.5 ESP32-P4Наиболее производительная архитектура: до 64 МБ PSRAM интерфейсы OPI и HPI двухуровневый кэш (L1 + L2) частоты до 200 МГц аппаратное шифрование 6. Использование PSRAM в ESP-IDFОсновной компонент: esp_psram В новых версиях ESP-IDF его нужно явно добавить в зависимости: idf_component_register( SRCS "main.c" INCLUDE_DIRS "." REQUIRES esp_psram )После этого появляется меню: Component config → ESP PSRAM7. Ключевые параметры menuconfig7.1 CONFIG_SPIRAM_BOOT_INITАвтоматическая инициализация при старте. Рекомендуется включать. 7.2 CONFIG_SPIRAM_IGNORE_NOTFOUNDПозволяет загружаться без PSRAM. Полезно для универсальных прошивок. 7.3 CONFIG_SPIRAM_MEMTESTТест памяти при старте. ≈ 1 секунда на 4 МБ. 7.4 CONFIG_SPIRAM_USEОпределяет стратегию интеграции: 1) MEMMAPПросто отображение в адресное пространство. Вы сами управляете памятью. 2) CAPS_ALLOCИспользование через: heap_caps_malloc(size, MALLOC_CAP_SPIRAM);Наиболее управляемый способ. 3) MALLOC (по умолчанию)PSRAM объединяется с общей кучей. malloc() автоматически выбирает регион. 7.5 CONFIG_SPIRAM_MALLOC_ALWAYSINTERNALПорог (по умолчанию 16 КБ): меньше → внутренняя RAM больше → PSRAM 7.6 CONFIG_SPIRAM_MALLOC_RESERVE_INTERNALРезервирует внутреннюю память под: DMA стеки задач критические участки Очень важная опция для стабильности. 7.7 Перенос кода и данныхCONFIG_SPIRAM_FETCH_INSTRUCTIONS CONFIG_SPIRAM_RODATA CONFIG_SPIRAM_XIP_FROM_PSRAM Позволяют: выполнять код из PSRAM разгрузить Flash ускорить систему (в Octal-режиме) 8. API esp_psramФункции: esp_psram_init(); esp_psram_is_initialized(); esp_psram_get_size();Практически используется только: esp_psram_get_size();9. Выделение памяти9.1 Автоматический режимvoid *ptr = malloc(size);Работает при CONFIG_SPIRAM_USE_MALLOC. 9.2 Явное выделение в PSRAMvoid *ptr = heap_caps_malloc(size, MALLOC_CAP_SPIRAM);Освобождение — обычный free(). 9.3 Когда использовать PSRAMПодходит для: больших JSON framebuffer аудиобуферов кешей временных массивов Не подходит для: DMA ISR стека задач структур с высокой частотой доступа 10. Практическая стратегияОптимальный подход для production: CONFIG_SPIRAM_USE_CAPS_ALLOC CONFIG_SPIRAM_MALLOC_RESERVE_INTERNAL WiFi/LWIP → в PSRAM Стек, DMA → внутренняя RAM Это даёт предсказуемую производительность. 11. ИтогPSRAM — это: дешёвый способ расширить RAM возможность работать с графикой и ML разгрузка внутренней памяти Но: – всегда медленнее внутренней SRAM – требует грамотной конфигурации – может вызывать проблемы когерентности Для серьёзных проектов рекомендуется: ESP-IDF ручное управление аллокацией контроль DMA-буферов резерв внутренней памяти -
 LiDAR (Light Detection and Ranging) — это технология измерения расстояния с помощью лазерного излучения. Метод основан на регистрации времени пролёта лазерного импульса (TOF, Time of Flight) от источника до объекта и обратно к приёмнику. По сути, лидар — это высокоточный лазерный дальномер, формирующий трёхмерную модель окружающего пространства в виде облака точек. История технологииКонцепция лидара была предложена в 1930 году британским физиком Edward Hutchinson Synge, который рассматривал возможность исследования атмосферы с помощью мощных световых источников. Сегодня LiDAR широко применяется в: метеорологии, геодезии, автономном транспорте, сельском хозяйстве, робототехнике, космических исследованиях. Как работает LiDARПринцип работы включает несколько этапов: Генерация импульса Лазерный излучатель (часто 905 нм или 1550 нм) формирует короткий импульс света. Отражение от объекта Луч достигает поверхности (здание, автомобиль, дерево, человек) и отражается. Регистрация сигнала Отражённый свет фиксируется фотоприёмником. Расчёт расстояния Система измеряет время пролёта импульса и вычисляет расстояние по формуле: D=c⋅t2D = \frac{c \cdot t}{2}D=2c⋅t где: D — расстояние, c — скорость света, t — время между отправкой и приёмом импульса. Формирование облака точек Миллионы измерений объединяются в трёхмерную карту сцены. Основные компоненты лидараТиповая система LiDAR включает: лазерный модуль (часто VCSEL); оптическую систему (линзы, фильтры); фотоприёмник (SiPM или лавинный фотодиод); АЦП (аналогово-цифровой преобразователь); вычислительный модуль (FPGA, AI-процессор); систему сканирования. Типы лидаров1. Механические лидары (360°)Имеют вращающуюся платформу с излучателем и приёмником. Особенности: горизонтальный обзор 360° высокая точность сложная механика более высокая стоимость Применяются в автономных автомобилях и картографировании. 2. Твердотельные лидарыНе содержат вращающихся элементов. Сканирование выполняется с помощью MEMS-зеркал или фазированных решёток. Преимущества: компактность устойчивость к вибрациям меньшая стоимость высокая надёжность Широко применяются в ADAS, дронах и робототехнике. Методы измерения скоростиLiDAR может измерять скорость объектов: Доплеровский метод — по изменению частоты отражённого сигнала. Последовательные измерения — по изменению расстояния во времени. Используется для определения скорости: ветра, транспортных средств, движущихся объектов. Области применения LiDAR1. Автономный транспорт и ADASLiDAR — ключевой сенсор в системах автопилотирования. Пример промышленного внедрения — разработки компании Waymo и беспилотные проекты Яндекс. Функции: обнаружение препятствий распознавание пешеходов адаптивный круиз-контроль экстренное торможение удержание полосы 2. Геодезия и картографияАэро-лидары устанавливаются на самолёты и БПЛА. Используются совместно с: GPS инерциальными системами (IMU) Результат — цифровая модель рельефа (ЦМР). 3. Метеорология и атмосферные исследованияПозволяют измерять: аэрозольную нагрузку концентрацию метана параметры облаков скорость ветра интенсивность осадков 4. Сельское хозяйствоПрименение: построение топографии полей анализ зон урожайности обнаружение сорняков (с применением ML) навигация сельхозтехники без GPS мониторинг виноградников и садов 5. АрхеологияLiDAR позволяет выявлять объекты под густым лесным покровом. Пример — обнаружение древних сооружений в регионе Ла-Москития (Гондурас) и исследование древнего города Махендрапарвата. 6. КосмосЛазерная альтиметрия применяется для картографирования планет. Пример — марсианский альтиметр MOLA на орбитальном аппарате NASA. Также лидар используется при сближении космических аппаратов и посадке на поверхность. Российский рынок лидаровПроизводствоВ 2025 году компания Радар ММС запустила производство модулей воздушно-лазерного сканирования для автомобилей и дронов. ИсследованияВ 2022 году МТУСИ совместно с ИОФ РАН протестировали мобильный лидар в рамках научной установки беспроводной подводной лазерной связи. Мировой рынок LiDARАвтомобильный сегментПо данным Fortune Business Insights: 2024 год — $3,72 млрд 2026 год — $4,16 млрд прогноз к 2032 году — $9,54 млрд CAGR — 12,6% Крупные игроки: Luminar Technologies Valeo S.A. Innoviz Technologies Continental Aeva Technologies Ouster Hesai Technology RoboSense Рынок лидаров для смартфонов2023 год — $2,03 млрд 2024 год — $2,42 млрд прогноз к 2032 году — $10 млрд CAGR — 19,38% Рост обеспечен развитием AR/VR и мобильной съёмки. Преимущества и ограничения технологииПреимуществавысокая точность (до сантиметров) независимость от освещённости формирование 3D-моделей в реальном времени высокая дальность (до 300+ м) Ограничениячувствительность к погодным условиям высокая стоимость (для высокодальних систем) необходимость обработки больших массивов данных Перспективы развитияТренды отрасли: переход от механических к твердотельным решениям интеграция с AI снижение стоимости модулей рост применения в умных городах развитие FMCW-лидаров интеграция в потребительскую электронику
LiDAR (Light Detection and Ranging) — это технология измерения расстояния с помощью лазерного излучения. Метод основан на регистрации времени пролёта лазерного импульса (TOF, Time of Flight) от источника до объекта и обратно к приёмнику. По сути, лидар — это высокоточный лазерный дальномер, формирующий трёхмерную модель окружающего пространства в виде облака точек. История технологииКонцепция лидара была предложена в 1930 году британским физиком Edward Hutchinson Synge, который рассматривал возможность исследования атмосферы с помощью мощных световых источников. Сегодня LiDAR широко применяется в: метеорологии, геодезии, автономном транспорте, сельском хозяйстве, робототехнике, космических исследованиях. Как работает LiDARПринцип работы включает несколько этапов: Генерация импульса Лазерный излучатель (часто 905 нм или 1550 нм) формирует короткий импульс света. Отражение от объекта Луч достигает поверхности (здание, автомобиль, дерево, человек) и отражается. Регистрация сигнала Отражённый свет фиксируется фотоприёмником. Расчёт расстояния Система измеряет время пролёта импульса и вычисляет расстояние по формуле: D=c⋅t2D = \frac{c \cdot t}{2}D=2c⋅t где: D — расстояние, c — скорость света, t — время между отправкой и приёмом импульса. Формирование облака точек Миллионы измерений объединяются в трёхмерную карту сцены. Основные компоненты лидараТиповая система LiDAR включает: лазерный модуль (часто VCSEL); оптическую систему (линзы, фильтры); фотоприёмник (SiPM или лавинный фотодиод); АЦП (аналогово-цифровой преобразователь); вычислительный модуль (FPGA, AI-процессор); систему сканирования. Типы лидаров1. Механические лидары (360°)Имеют вращающуюся платформу с излучателем и приёмником. Особенности: горизонтальный обзор 360° высокая точность сложная механика более высокая стоимость Применяются в автономных автомобилях и картографировании. 2. Твердотельные лидарыНе содержат вращающихся элементов. Сканирование выполняется с помощью MEMS-зеркал или фазированных решёток. Преимущества: компактность устойчивость к вибрациям меньшая стоимость высокая надёжность Широко применяются в ADAS, дронах и робототехнике. Методы измерения скоростиLiDAR может измерять скорость объектов: Доплеровский метод — по изменению частоты отражённого сигнала. Последовательные измерения — по изменению расстояния во времени. Используется для определения скорости: ветра, транспортных средств, движущихся объектов. Области применения LiDAR1. Автономный транспорт и ADASLiDAR — ключевой сенсор в системах автопилотирования. Пример промышленного внедрения — разработки компании Waymo и беспилотные проекты Яндекс. Функции: обнаружение препятствий распознавание пешеходов адаптивный круиз-контроль экстренное торможение удержание полосы 2. Геодезия и картографияАэро-лидары устанавливаются на самолёты и БПЛА. Используются совместно с: GPS инерциальными системами (IMU) Результат — цифровая модель рельефа (ЦМР). 3. Метеорология и атмосферные исследованияПозволяют измерять: аэрозольную нагрузку концентрацию метана параметры облаков скорость ветра интенсивность осадков 4. Сельское хозяйствоПрименение: построение топографии полей анализ зон урожайности обнаружение сорняков (с применением ML) навигация сельхозтехники без GPS мониторинг виноградников и садов 5. АрхеологияLiDAR позволяет выявлять объекты под густым лесным покровом. Пример — обнаружение древних сооружений в регионе Ла-Москития (Гондурас) и исследование древнего города Махендрапарвата. 6. КосмосЛазерная альтиметрия применяется для картографирования планет. Пример — марсианский альтиметр MOLA на орбитальном аппарате NASA. Также лидар используется при сближении космических аппаратов и посадке на поверхность. Российский рынок лидаровПроизводствоВ 2025 году компания Радар ММС запустила производство модулей воздушно-лазерного сканирования для автомобилей и дронов. ИсследованияВ 2022 году МТУСИ совместно с ИОФ РАН протестировали мобильный лидар в рамках научной установки беспроводной подводной лазерной связи. Мировой рынок LiDARАвтомобильный сегментПо данным Fortune Business Insights: 2024 год — $3,72 млрд 2026 год — $4,16 млрд прогноз к 2032 году — $9,54 млрд CAGR — 12,6% Крупные игроки: Luminar Technologies Valeo S.A. Innoviz Technologies Continental Aeva Technologies Ouster Hesai Technology RoboSense Рынок лидаров для смартфонов2023 год — $2,03 млрд 2024 год — $2,42 млрд прогноз к 2032 году — $10 млрд CAGR — 19,38% Рост обеспечен развитием AR/VR и мобильной съёмки. Преимущества и ограничения технологииПреимуществавысокая точность (до сантиметров) независимость от освещённости формирование 3D-моделей в реальном времени высокая дальность (до 300+ м) Ограничениячувствительность к погодным условиям высокая стоимость (для высокодальних систем) необходимость обработки больших массивов данных Перспективы развитияТренды отрасли: переход от механических к твердотельным решениям интеграция с AI снижение стоимости модулей рост применения в умных городах развитие FMCW-лидаров интеграция в потребительскую электронику -
 Конденсаторы — обязательные компоненты большинства электронных устройств: от бытовой техники до промышленной автоматики. Они выполняют функции накопления и отдачи энергии, фильтрации помех, формирования частоты и сглаживания пульсаций напряжения. Во многих случаях отказ оборудования связан именно с неисправностью конденсатора. Поэтому важно понимать, как корректно проверить его работоспособность с помощью мультиметра и какие дефекты встречаются чаще всего. Что такое конденсатор и как он работаетКонденсатор — это пассивный электронный компонент, состоящий из двух проводящих обкладок, разделённых диэлектриком. Его ключевые параметры: Ёмкость (Ф, мкФ, нФ, пФ) — способность накапливать заряд Рабочее напряжение (В) — максимально допустимое напряжение Тип диэлектрика — влияет на стабильность и область применения Полярность — у некоторых типов строго соблюдается Основные виды конденсаторов1. По назначениюВысоковольтныеИспользуются в силовой электронике и высоковольтном оборудовании. Бывают керамические, масляные, вакуумные. Доступ к ним часто ограничен требованиями безопасности. ПусковыеПрименяются в электродвигателях для увеличения пускового момента. Подстроечные (переменные)Позволяют изменять ёмкость регулировкой положения подвижной пластины. ИмпульсныеФормируют короткие пики напряжения для передачи сигналов. Помехоподавляющие (X и Y-класса)Стабилизируют работу чувствительных устройств, подавляя электромагнитные помехи. 2. По типу диэлектрикаБумажные Плёночные Керамические Слюдяные Электролитические (алюминиевые, танталовые) Стеклокерамические Оксидно-полупроводниковые 3. По полярностиПолярныеЭлектролитические Танталовые Имеют маркировку минусового вывода. Нарушение полярности приводит к выходу из строя. НеполярныеКерамические Плёночные Слюдяные Не требуют соблюдения полярности при подключении. Типичные неисправности конденсаторов1. Короткое замыкание (КЗ)Причины: пробой изоляции превышение рабочего напряжения перегрев механические повреждения Симптом: сопротивление близко к нулю. 2. ОбрывПотеря электрического контакта с обкладкой. Ёмкость становится равной нулю. Часто встречается: в электролитических в помехоподавляющих Y-конденсаторах (конструктивно защищены от КЗ) 3. Потеря ёмкостиОсобенно характерна для электролитических конденсаторов из-за высыхания электролита. 4. Повышенная утечкаЭлемент не удерживает заряд. Часто наблюдается у: электролитических танталовых Подготовка к проверке мультиметромПеред измерениями необходимо: Отключить устройство от сети Разрядить конденсатор Замкнуть выводы металлическим предметом (для мощных — через резистор) Осмотреть корпус вздутие потёки трещины обугливание Определить полярность Выпаять элемент Проверка на плате часто даёт некорректные результаты из-за влияния других компонентов. Как проверить полярный (электролитический) конденсаторПроверка на КЗ или обрывРазрядить элемент Установить мультиметр в режим: «прозвонка» «сопротивление» Подключить: «+» к плюсу «−» к минусу Интерпретация результатов:Показание Диагноз 0 Ом Короткое замыкание 1 без изменений Обрыв Сопротивление растёт Исправен Рост сопротивления означает заряд конденсатора от батареи мультиметра. Как проверить неполярный конденсаторУстановить режим измерения сопротивления (МОм) Подключить щупы без соблюдения полярности Результат:Более 2 МОм → исправен Менее 2 МОм → вероятна неисправность Проверка на короткое замыканиеВ режиме прозвонкиЕсли мультиметр постоянно издаёт звуковой сигнал — присутствует КЗ. В режиме сопротивленияСопротивление близкое к 0 Ом — короткое замыкание. Проверка на обрывМетод 1 — прозвонкаКратковременный щелчок → исправен Отсутствие реакции → возможен обрыв Метод 2 — измерение сопротивленияНа максимальном диапазоне сопротивление должно плавно увеличиваться. Проверка остаточного напряженияСамый чувствительный способ: В режиме сопротивления зарядить конденсатор 2–3 секунды Переключить мультиметр на измерение постоянного напряжения Подключить снова Если прибор показывает остаточное напряжение — элемент исправен. Подходит для большинства типов, кроме сверхмалых ёмкостей (<470 пФ). Как измерить ёмкость мультиметромЕсли прибор имеет функцию измерения ёмкости: Выбрать режим Cx Установить диапазон Подключить выводы Сравнить значение с номиналом Допустимое отклонение обычно: ±5–20% для большинства типов ±10% для электролитических Проверка пускового конденсатораОбесточить оборудование Выпаять и разрядить элемент Измерить ёмкость Сравнить с номиналом Если расхождение превышает допустимое — требуется замена. Проверка керамического конденсатораКерамические — неполярные. Режим измерения сопротивления Предел — МОм Показание >2 МОм → исправен Для точной оценки ёмкости нужен специализированный прибор. Можно ли проверять без выпаивания?В большинстве случаев — нет. Причины: параллельные цепи искажают показания диоды и транзисторы могут симулировать КЗ измеряется суммарная ёмкость Допустимо проверять: электролитические >1 мкФ только на КЗ или обрыв Для точной диагностики рекомендуется выпаивание. Когда лучше заменить, чем проверять?Если наблюдаются: вздутие утечка электролита сильный перегрев значительное отклонение ёмкости В таких случаях замена быстрее и надёжнее ремонта. ВыводПроверка конденсатора мультиметром — эффективный способ диагностики короткого замыкания, обрыва и грубых отклонений ёмкости. Для точных измерений малых ёмкостей и оценки ESR требуется специализированное оборудование.
Конденсаторы — обязательные компоненты большинства электронных устройств: от бытовой техники до промышленной автоматики. Они выполняют функции накопления и отдачи энергии, фильтрации помех, формирования частоты и сглаживания пульсаций напряжения. Во многих случаях отказ оборудования связан именно с неисправностью конденсатора. Поэтому важно понимать, как корректно проверить его работоспособность с помощью мультиметра и какие дефекты встречаются чаще всего. Что такое конденсатор и как он работаетКонденсатор — это пассивный электронный компонент, состоящий из двух проводящих обкладок, разделённых диэлектриком. Его ключевые параметры: Ёмкость (Ф, мкФ, нФ, пФ) — способность накапливать заряд Рабочее напряжение (В) — максимально допустимое напряжение Тип диэлектрика — влияет на стабильность и область применения Полярность — у некоторых типов строго соблюдается Основные виды конденсаторов1. По назначениюВысоковольтныеИспользуются в силовой электронике и высоковольтном оборудовании. Бывают керамические, масляные, вакуумные. Доступ к ним часто ограничен требованиями безопасности. ПусковыеПрименяются в электродвигателях для увеличения пускового момента. Подстроечные (переменные)Позволяют изменять ёмкость регулировкой положения подвижной пластины. ИмпульсныеФормируют короткие пики напряжения для передачи сигналов. Помехоподавляющие (X и Y-класса)Стабилизируют работу чувствительных устройств, подавляя электромагнитные помехи. 2. По типу диэлектрикаБумажные Плёночные Керамические Слюдяные Электролитические (алюминиевые, танталовые) Стеклокерамические Оксидно-полупроводниковые 3. По полярностиПолярныеЭлектролитические Танталовые Имеют маркировку минусового вывода. Нарушение полярности приводит к выходу из строя. НеполярныеКерамические Плёночные Слюдяные Не требуют соблюдения полярности при подключении. Типичные неисправности конденсаторов1. Короткое замыкание (КЗ)Причины: пробой изоляции превышение рабочего напряжения перегрев механические повреждения Симптом: сопротивление близко к нулю. 2. ОбрывПотеря электрического контакта с обкладкой. Ёмкость становится равной нулю. Часто встречается: в электролитических в помехоподавляющих Y-конденсаторах (конструктивно защищены от КЗ) 3. Потеря ёмкостиОсобенно характерна для электролитических конденсаторов из-за высыхания электролита. 4. Повышенная утечкаЭлемент не удерживает заряд. Часто наблюдается у: электролитических танталовых Подготовка к проверке мультиметромПеред измерениями необходимо: Отключить устройство от сети Разрядить конденсатор Замкнуть выводы металлическим предметом (для мощных — через резистор) Осмотреть корпус вздутие потёки трещины обугливание Определить полярность Выпаять элемент Проверка на плате часто даёт некорректные результаты из-за влияния других компонентов. Как проверить полярный (электролитический) конденсаторПроверка на КЗ или обрывРазрядить элемент Установить мультиметр в режим: «прозвонка» «сопротивление» Подключить: «+» к плюсу «−» к минусу Интерпретация результатов:Показание Диагноз 0 Ом Короткое замыкание 1 без изменений Обрыв Сопротивление растёт Исправен Рост сопротивления означает заряд конденсатора от батареи мультиметра. Как проверить неполярный конденсаторУстановить режим измерения сопротивления (МОм) Подключить щупы без соблюдения полярности Результат:Более 2 МОм → исправен Менее 2 МОм → вероятна неисправность Проверка на короткое замыканиеВ режиме прозвонкиЕсли мультиметр постоянно издаёт звуковой сигнал — присутствует КЗ. В режиме сопротивленияСопротивление близкое к 0 Ом — короткое замыкание. Проверка на обрывМетод 1 — прозвонкаКратковременный щелчок → исправен Отсутствие реакции → возможен обрыв Метод 2 — измерение сопротивленияНа максимальном диапазоне сопротивление должно плавно увеличиваться. Проверка остаточного напряженияСамый чувствительный способ: В режиме сопротивления зарядить конденсатор 2–3 секунды Переключить мультиметр на измерение постоянного напряжения Подключить снова Если прибор показывает остаточное напряжение — элемент исправен. Подходит для большинства типов, кроме сверхмалых ёмкостей (<470 пФ). Как измерить ёмкость мультиметромЕсли прибор имеет функцию измерения ёмкости: Выбрать режим Cx Установить диапазон Подключить выводы Сравнить значение с номиналом Допустимое отклонение обычно: ±5–20% для большинства типов ±10% для электролитических Проверка пускового конденсатораОбесточить оборудование Выпаять и разрядить элемент Измерить ёмкость Сравнить с номиналом Если расхождение превышает допустимое — требуется замена. Проверка керамического конденсатораКерамические — неполярные. Режим измерения сопротивления Предел — МОм Показание >2 МОм → исправен Для точной оценки ёмкости нужен специализированный прибор. Можно ли проверять без выпаивания?В большинстве случаев — нет. Причины: параллельные цепи искажают показания диоды и транзисторы могут симулировать КЗ измеряется суммарная ёмкость Допустимо проверять: электролитические >1 мкФ только на КЗ или обрыв Для точной диагностики рекомендуется выпаивание. Когда лучше заменить, чем проверять?Если наблюдаются: вздутие утечка электролита сильный перегрев значительное отклонение ёмкости В таких случаях замена быстрее и надёжнее ремонта. ВыводПроверка конденсатора мультиметром — эффективный способ диагностики короткого замыкания, обрыва и грубых отклонений ёмкости. Для точных измерений малых ёмкостей и оценки ESR требуется специализированное оборудование. -
 Интернет вещей (IoT, Internet of Things) в промышленной среде получил отдельное направление — промышленный интернет вещей (IIoT, Industrial Internet of Things). Это комплекс аппаратных и программных решений, который объединяет датчики, оборудование, контроллеры и ИТ-системы в единую цифровую среду с возможностью обмена данными в режиме, близком к реальному времени. Внедрение IIoT позволяет: осуществлять непрерывный мониторинг оборудования; переходить от планового к прогнозирующему обслуживанию (Predictive Maintenance); снижать внеплановые простои; оптимизировать энергопотребление; повышать прозрачность производственных процессов; интегрировать производство с ERP- и MES-системами. Что такое IIoT и какие задачи он решаетПромышленный интернет вещей (IIoT) — это совокупность технологий, обеспечивающих подключение оборудования и датчиков к сети для сбора, передачи, обработки и анализа данных. Ключевая задача IIoT — переход от реактивной модели эксплуатации оборудования («сломалось — ремонтируем») к проактивной модели управления активами. Проблема традиционного подходаНа предприятии с большим количеством сложных машин: оборудование обслуживается по регламенту, а не по фактическому состоянию; поломки часто возникают внезапно; возникают внеплановые простои; требуется держать избыточный склад запчастей; увеличиваются эксплуатационные расходы (OPEX). Как IIoT меняет модель управленияКаждая единица оборудования оснащается датчиками, которые фиксируют: температуру, вибрацию, давление, ток и напряжение, скорость вращения, другие технологические параметры. Данные передаются на локальные серверы или в облачную инфраструктуру, где автоматически анализируются. При отклонении параметров от нормативных значений система: уведомляет оператора; формирует заявку на обслуживание; может инициировать автоматическое регулирование. Это позволяет: предотвратить аварии, сократить downtime, снизить стоимость владения оборудованием (TCO). Прогнозирующее обслуживание: практический примерОдин из наиболее показательных кейсов — авиационная промышленность. Производители двигателей устанавливают независимые каналы связи, предназначенные исключительно для передачи телеметрии наземным службам. На основе массивов данных строятся аналитические модели, которые прогнозируют: остаточный ресурс узлов; вероятность отказа; оптимальное время замены деталей. В промышленности аналогичный подход применяет, например, Siemens. На производственных площадках компания внедряет системы датчиков, которые контролируют: механические параметры станков, энергопотребление, режимы загрузки линий. Если линия простаивает, система автоматически снижает энергопотребление, что напрямую сокращает операционные затраты. История развития IoT и становление IIoTКонцептуальные предпосылки IoT появились еще в 1980-х годах с развитием сетевых технологий. Термин «Internet of Things» в 1999 году предложил Kevin Ashton. Он рассматривал применение RFID-меток для отслеживания товаров в цепочках поставок. Активная фаза развития IoT началась в 2010-х годах благодаря: удешевлению сенсоров; распространению беспроводной связи; развитию облачных платформ; росту вычислительных мощностей. В промышленности это привело к формированию концепции IIoT и «умных фабрик» (Smart Factory) в рамках парадигмы Industry 4.0. Архитектура IIoT: уровни и требованияТиповая архитектура IIoT представляет собой многоуровневую систему. 1. Уровень сенсоров и устройств (Device Layer)Физический уровень включает: датчики, исполнительные механизмы, контроллеры, производственное оборудование. Критические требования: устойчивость к температуре, пыли, влажности; виброустойчивость; низкое энергопотребление; промышленная степень защиты (IP, EMI/EMC). 2. Сеть передачи данных (Communication Layer)Обеспечивает передачу информации между устройствами, edge-узлами и центрами обработки. Используются: Ethernet; Wi-Fi; 4G/5G; LPWAN; промышленные протоколы. Требования: высокая пропускная способность; минимальная задержка; отказоустойчивость; защищенность передачи данных. Оборудование промышленного уровня поставляют такие компании, как: Schneider Electric Allied Telesis Moxa Hirschmann Automation and Control B&R Выбор оборудования должен учитывать реальные условия эксплуатации — перепады температур, влажность, вибрации и электромагнитные помехи. 3. Граничные устройства (Edge Layer)Edge-устройства обрабатывают данные непосредственно на объекте. Их задачи: локальная фильтрация и агрегация данных; анализ в реальном времени; снижение нагрузки на облако; обеспечение автономной работы при потере связи. Обычно поддерживаются протоколы MQTT, OPC UA и другие индустриальные стандарты. Важно разграничивать: Edge — анализ и предварительная обработка данных; PLC/контроллеры — управление оборудованием. 4. Уровень управления (Control Layer)Включает: PLC; SCADA-системы; MES; интеграцию с ERP. Системы класса SCADA обеспечивают диспетчеризацию и визуализацию процессов, а MES — управление производственными операциями. 5. Обработка данных и аналитика (Data & Analytics Layer)На этом уровне используются: Big Data; машинное обучение; предиктивная аналитика; цифровые двойники (Digital Twin). Цель — выявление закономерностей, оптимизация процессов и стратегическое управление активами. Применение IIoT в различных отрасляхПромышленность и машиностроениемониторинг станков; оптимизация производственных линий; снижение брака; предиктивное обслуживание. Особое значение имеют edge-вычисления и отказоустойчивые сети. Логистика и транспортотслеживание транспорта в реальном времени; контроль состояния грузов; автоматическое пополнение запасов. Ключевую роль играют мобильные сети и устойчивость связи при перемещении между зонами покрытия. Энергетикамониторинг генерации и распределения; контроль подстанций; управление распределенными энергоресурсами; интеграция ВИЭ. Системы должны быть масштабируемыми и устойчивыми к тяжелым условиям эксплуатации. Сельское хозяйствомониторинг влажности почвы; контроль микроклимата; управление сельхозтехникой; автоматизация полива. Основной акцент — энергоэффективные беспроводные технологии и автономность. Преимущества внедрения IIoTВнедрение промышленного интернета вещей позволяет: снизить внеплановые простои; сократить издержки на обслуживание; уменьшить энергопотребление; повысить прозрачность процессов; улучшить управляемость цепочек поставок; повысить общую операционную эффективность предприятия. IIoT становится фундаментом цифровой трансформации промышленности и ключевым элементом конкурентоспособности в условиях Industry 4.0.
Интернет вещей (IoT, Internet of Things) в промышленной среде получил отдельное направление — промышленный интернет вещей (IIoT, Industrial Internet of Things). Это комплекс аппаратных и программных решений, который объединяет датчики, оборудование, контроллеры и ИТ-системы в единую цифровую среду с возможностью обмена данными в режиме, близком к реальному времени. Внедрение IIoT позволяет: осуществлять непрерывный мониторинг оборудования; переходить от планового к прогнозирующему обслуживанию (Predictive Maintenance); снижать внеплановые простои; оптимизировать энергопотребление; повышать прозрачность производственных процессов; интегрировать производство с ERP- и MES-системами. Что такое IIoT и какие задачи он решаетПромышленный интернет вещей (IIoT) — это совокупность технологий, обеспечивающих подключение оборудования и датчиков к сети для сбора, передачи, обработки и анализа данных. Ключевая задача IIoT — переход от реактивной модели эксплуатации оборудования («сломалось — ремонтируем») к проактивной модели управления активами. Проблема традиционного подходаНа предприятии с большим количеством сложных машин: оборудование обслуживается по регламенту, а не по фактическому состоянию; поломки часто возникают внезапно; возникают внеплановые простои; требуется держать избыточный склад запчастей; увеличиваются эксплуатационные расходы (OPEX). Как IIoT меняет модель управленияКаждая единица оборудования оснащается датчиками, которые фиксируют: температуру, вибрацию, давление, ток и напряжение, скорость вращения, другие технологические параметры. Данные передаются на локальные серверы или в облачную инфраструктуру, где автоматически анализируются. При отклонении параметров от нормативных значений система: уведомляет оператора; формирует заявку на обслуживание; может инициировать автоматическое регулирование. Это позволяет: предотвратить аварии, сократить downtime, снизить стоимость владения оборудованием (TCO). Прогнозирующее обслуживание: практический примерОдин из наиболее показательных кейсов — авиационная промышленность. Производители двигателей устанавливают независимые каналы связи, предназначенные исключительно для передачи телеметрии наземным службам. На основе массивов данных строятся аналитические модели, которые прогнозируют: остаточный ресурс узлов; вероятность отказа; оптимальное время замены деталей. В промышленности аналогичный подход применяет, например, Siemens. На производственных площадках компания внедряет системы датчиков, которые контролируют: механические параметры станков, энергопотребление, режимы загрузки линий. Если линия простаивает, система автоматически снижает энергопотребление, что напрямую сокращает операционные затраты. История развития IoT и становление IIoTКонцептуальные предпосылки IoT появились еще в 1980-х годах с развитием сетевых технологий. Термин «Internet of Things» в 1999 году предложил Kevin Ashton. Он рассматривал применение RFID-меток для отслеживания товаров в цепочках поставок. Активная фаза развития IoT началась в 2010-х годах благодаря: удешевлению сенсоров; распространению беспроводной связи; развитию облачных платформ; росту вычислительных мощностей. В промышленности это привело к формированию концепции IIoT и «умных фабрик» (Smart Factory) в рамках парадигмы Industry 4.0. Архитектура IIoT: уровни и требованияТиповая архитектура IIoT представляет собой многоуровневую систему. 1. Уровень сенсоров и устройств (Device Layer)Физический уровень включает: датчики, исполнительные механизмы, контроллеры, производственное оборудование. Критические требования: устойчивость к температуре, пыли, влажности; виброустойчивость; низкое энергопотребление; промышленная степень защиты (IP, EMI/EMC). 2. Сеть передачи данных (Communication Layer)Обеспечивает передачу информации между устройствами, edge-узлами и центрами обработки. Используются: Ethernet; Wi-Fi; 4G/5G; LPWAN; промышленные протоколы. Требования: высокая пропускная способность; минимальная задержка; отказоустойчивость; защищенность передачи данных. Оборудование промышленного уровня поставляют такие компании, как: Schneider Electric Allied Telesis Moxa Hirschmann Automation and Control B&R Выбор оборудования должен учитывать реальные условия эксплуатации — перепады температур, влажность, вибрации и электромагнитные помехи. 3. Граничные устройства (Edge Layer)Edge-устройства обрабатывают данные непосредственно на объекте. Их задачи: локальная фильтрация и агрегация данных; анализ в реальном времени; снижение нагрузки на облако; обеспечение автономной работы при потере связи. Обычно поддерживаются протоколы MQTT, OPC UA и другие индустриальные стандарты. Важно разграничивать: Edge — анализ и предварительная обработка данных; PLC/контроллеры — управление оборудованием. 4. Уровень управления (Control Layer)Включает: PLC; SCADA-системы; MES; интеграцию с ERP. Системы класса SCADA обеспечивают диспетчеризацию и визуализацию процессов, а MES — управление производственными операциями. 5. Обработка данных и аналитика (Data & Analytics Layer)На этом уровне используются: Big Data; машинное обучение; предиктивная аналитика; цифровые двойники (Digital Twin). Цель — выявление закономерностей, оптимизация процессов и стратегическое управление активами. Применение IIoT в различных отрасляхПромышленность и машиностроениемониторинг станков; оптимизация производственных линий; снижение брака; предиктивное обслуживание. Особое значение имеют edge-вычисления и отказоустойчивые сети. Логистика и транспортотслеживание транспорта в реальном времени; контроль состояния грузов; автоматическое пополнение запасов. Ключевую роль играют мобильные сети и устойчивость связи при перемещении между зонами покрытия. Энергетикамониторинг генерации и распределения; контроль подстанций; управление распределенными энергоресурсами; интеграция ВИЭ. Системы должны быть масштабируемыми и устойчивыми к тяжелым условиям эксплуатации. Сельское хозяйствомониторинг влажности почвы; контроль микроклимата; управление сельхозтехникой; автоматизация полива. Основной акцент — энергоэффективные беспроводные технологии и автономность. Преимущества внедрения IIoTВнедрение промышленного интернета вещей позволяет: снизить внеплановые простои; сократить издержки на обслуживание; уменьшить энергопотребление; повысить прозрачность процессов; улучшить управляемость цепочек поставок; повысить общую операционную эффективность предприятия. IIoT становится фундаментом цифровой трансформации промышленности и ключевым элементом конкурентоспособности в условиях Industry 4.0. -
 Сегодня сложно представить электронику без инфракрасных (ИК) технологий: пульты дистанционного управления, системы безопасности, промышленная автоматизация, медицинские приборы и робототехника — во всех этих решениях применяются ИК-приемники. Разберем подробно, что такое инфракрасный приемник, как он устроен, по какому принципу работает и как диагностировать его неисправности. Что такое ИК-приемникИК-приемник (инфракрасный приемник) — это электронное устройство, предназначенное для приема и декодирования сигналов, передаваемых в виде инфракрасного излучения от источника (обычно ИК-светодиода). Классический пример — пульт дистанционного управления телевизором или кондиционером. Передатчик формирует последовательность модулированных ИК-импульсов, а приемник: Улавливает инфракрасное излучение. Преобразует его в электрический сигнал. Демодулирует и передает данные в управляющую схему устройства. Где применяются инфракрасные приемники1. Бытовая электроникаПульты ДУ (телевизоры, аудиосистемы, кондиционеры). Медиаплееры и приставки. Ранее — передача данных в мобильных телефонах и ПК (до распространения Bluetooth и Wi-Fi, скорость достигала ~4 Мбит/с). 2. Освещение и автоматизация зданийДатчики движения в подъездах, коридорах, санузлах. Автоматическое включение/выключение освещения. Энергосберегающие системы «умного дома». 3. Системы безопасностиОхранные датчики движения. Инфракрасные барьеры периметра. Контроль несанкционированного доступа. 4. Бесконтактные устройстваДиспенсеры мыла и воды. Сенсорные смесители. Бесконтактные мусорные контейнеры. 5. Медицинская техника и носимая электроникаБесконтактные термометры. Пульсометры и фитнес-трекеры (анализ кровотока по отраженному ИК-сигналу). Применение ИК-приемников в промышленностиПростота, надежность и низкая стоимость делают ИК-датчики востребованными в промышленной среде. Конвейерные линииДетекция присутствия объекта. Контроль положения детали. Синхронизация этапов сборки и упаковки. Системы безопасностиИнфракрасные барьеры. Контроль складов и производственных зон. Защита оборудования. Контроль качестваИнфракрасная спектроскопия для анализа состава материалов. Выявление дефектов. Контроль смесей в химическом и пищевом производстве. Энергетика и металлургияПирометры и тепловизоры. Контроль температуры печей, трубопроводов, реакторов. Предотвращение перегрева и аварий. ЛогистикаСистемы учета и сортировки. Взаимодействие со сканерами штрихкодов и RFID. Машиностроение и робототехникаОбнаружение препятствий. Навигация автономных систем. Системы точного позиционирования. Принцип работы инфракрасного приемникаИК-приемники работают в диапазоне длин волн 700 нм – 1 мм, однако в бытовых и промышленных системах чаще используется диапазон 850–950 нм. Основные этапы работы:Прием излучения Чувствительный элемент (фотодиод или фототранзистор) реагирует на ИК-свет. Преобразование в электрический сигнал При попадании излучения генерируется ток. Фильтрация Оптический фильтр подавляет помехи (солнечный свет, лампы). Модуляция и демодуляция Сигнал передается импульсами (обычно 36–38 кГц). Приемник выделяет именно эту частоту, игнорируя фон. Передача в контроллер Демодулированный сигнал поступает в микроконтроллер. Устройство ИК-приемникаТиповой ИК-модуль включает: фотодиод; усилитель; полосовой фильтр; демодулятор; формирователь цифрового сигнала. Основные характеристикиПараметр Описание Длина волны 850–950 нм (типично) Частота модуляции 36–38 кГц (иногда 56 кГц) Чувствительность Минимальная мощность сигнала (мкВт) Угол обзора 30–90° Дальность Зависит от мощности передатчика Время отклика От миллисекунд Тип выхода Аналоговый или цифровой Пример: Vishay TSOP4456Рассмотрим популярный модуль — TSOP4456 компании Vishay Intertechnology. Основные параметры:Питание: 2,5–5,5 В Частота модуляции: 56 кГц Потребляемый ток: ~0,4 мА Угол обзора: ~45° Дальность приема: до 45 м Температура: –25…+85 °C Выход: цифровой (активный низкий уровень) Модуль применяется в системах дистанционного управления, совместим с протоколами RCA и другими распространенными стандартами. Факторы, влияющие на работу ИК-приемникаВ промышленной эксплуатации необходимо учитывать: запыленность; задымленность; влажность; вибрации; температурные перепады; электромагнитные помехи. В сложных условиях применяются модули в герметичных корпусах с промышленным исполнением. Устранение неисправностей ИК-приемникаДиагностика проводится поэтапно. 1. Проверка передатчикаНавести пульт на камеру смартфона и нажать кнопку — мигающий свет указывает на исправность ИК-диода. 2. Осмотр приемникаПроверить загрязнение линзы. Осмотреть корпус на механические повреждения. 3. Проверка питанияИзмерить напряжение мультиметром. Проверить цепь питания и предохранители. 4. Проверка пайкиОсмотреть контакты. При необходимости перепаять соединения. 5. Проверка сигналаИспользовать осциллограф. Убедиться в наличии корректных импульсов. 6. Диагностика контроллераЕсли приемник исправен, проблема может быть в микроконтроллере или основной плате. Преимущества ИК-приемниковНизкая стоимость Простота интеграции Энергоэффективность Высокая помехоустойчивость (при модуляции) Надежность Широкий диапазон рабочих температур Несмотря на развитие Bluetooth, Wi-Fi и других беспроводных технологий, ИК-приемники остаются экономически и технически оправданным решением во множестве задач.
Сегодня сложно представить электронику без инфракрасных (ИК) технологий: пульты дистанционного управления, системы безопасности, промышленная автоматизация, медицинские приборы и робототехника — во всех этих решениях применяются ИК-приемники. Разберем подробно, что такое инфракрасный приемник, как он устроен, по какому принципу работает и как диагностировать его неисправности. Что такое ИК-приемникИК-приемник (инфракрасный приемник) — это электронное устройство, предназначенное для приема и декодирования сигналов, передаваемых в виде инфракрасного излучения от источника (обычно ИК-светодиода). Классический пример — пульт дистанционного управления телевизором или кондиционером. Передатчик формирует последовательность модулированных ИК-импульсов, а приемник: Улавливает инфракрасное излучение. Преобразует его в электрический сигнал. Демодулирует и передает данные в управляющую схему устройства. Где применяются инфракрасные приемники1. Бытовая электроникаПульты ДУ (телевизоры, аудиосистемы, кондиционеры). Медиаплееры и приставки. Ранее — передача данных в мобильных телефонах и ПК (до распространения Bluetooth и Wi-Fi, скорость достигала ~4 Мбит/с). 2. Освещение и автоматизация зданийДатчики движения в подъездах, коридорах, санузлах. Автоматическое включение/выключение освещения. Энергосберегающие системы «умного дома». 3. Системы безопасностиОхранные датчики движения. Инфракрасные барьеры периметра. Контроль несанкционированного доступа. 4. Бесконтактные устройстваДиспенсеры мыла и воды. Сенсорные смесители. Бесконтактные мусорные контейнеры. 5. Медицинская техника и носимая электроникаБесконтактные термометры. Пульсометры и фитнес-трекеры (анализ кровотока по отраженному ИК-сигналу). Применение ИК-приемников в промышленностиПростота, надежность и низкая стоимость делают ИК-датчики востребованными в промышленной среде. Конвейерные линииДетекция присутствия объекта. Контроль положения детали. Синхронизация этапов сборки и упаковки. Системы безопасностиИнфракрасные барьеры. Контроль складов и производственных зон. Защита оборудования. Контроль качестваИнфракрасная спектроскопия для анализа состава материалов. Выявление дефектов. Контроль смесей в химическом и пищевом производстве. Энергетика и металлургияПирометры и тепловизоры. Контроль температуры печей, трубопроводов, реакторов. Предотвращение перегрева и аварий. ЛогистикаСистемы учета и сортировки. Взаимодействие со сканерами штрихкодов и RFID. Машиностроение и робототехникаОбнаружение препятствий. Навигация автономных систем. Системы точного позиционирования. Принцип работы инфракрасного приемникаИК-приемники работают в диапазоне длин волн 700 нм – 1 мм, однако в бытовых и промышленных системах чаще используется диапазон 850–950 нм. Основные этапы работы:Прием излучения Чувствительный элемент (фотодиод или фототранзистор) реагирует на ИК-свет. Преобразование в электрический сигнал При попадании излучения генерируется ток. Фильтрация Оптический фильтр подавляет помехи (солнечный свет, лампы). Модуляция и демодуляция Сигнал передается импульсами (обычно 36–38 кГц). Приемник выделяет именно эту частоту, игнорируя фон. Передача в контроллер Демодулированный сигнал поступает в микроконтроллер. Устройство ИК-приемникаТиповой ИК-модуль включает: фотодиод; усилитель; полосовой фильтр; демодулятор; формирователь цифрового сигнала. Основные характеристикиПараметр Описание Длина волны 850–950 нм (типично) Частота модуляции 36–38 кГц (иногда 56 кГц) Чувствительность Минимальная мощность сигнала (мкВт) Угол обзора 30–90° Дальность Зависит от мощности передатчика Время отклика От миллисекунд Тип выхода Аналоговый или цифровой Пример: Vishay TSOP4456Рассмотрим популярный модуль — TSOP4456 компании Vishay Intertechnology. Основные параметры:Питание: 2,5–5,5 В Частота модуляции: 56 кГц Потребляемый ток: ~0,4 мА Угол обзора: ~45° Дальность приема: до 45 м Температура: –25…+85 °C Выход: цифровой (активный низкий уровень) Модуль применяется в системах дистанционного управления, совместим с протоколами RCA и другими распространенными стандартами. Факторы, влияющие на работу ИК-приемникаВ промышленной эксплуатации необходимо учитывать: запыленность; задымленность; влажность; вибрации; температурные перепады; электромагнитные помехи. В сложных условиях применяются модули в герметичных корпусах с промышленным исполнением. Устранение неисправностей ИК-приемникаДиагностика проводится поэтапно. 1. Проверка передатчикаНавести пульт на камеру смартфона и нажать кнопку — мигающий свет указывает на исправность ИК-диода. 2. Осмотр приемникаПроверить загрязнение линзы. Осмотреть корпус на механические повреждения. 3. Проверка питанияИзмерить напряжение мультиметром. Проверить цепь питания и предохранители. 4. Проверка пайкиОсмотреть контакты. При необходимости перепаять соединения. 5. Проверка сигналаИспользовать осциллограф. Убедиться в наличии корректных импульсов. 6. Диагностика контроллераЕсли приемник исправен, проблема может быть в микроконтроллере или основной плате. Преимущества ИК-приемниковНизкая стоимость Простота интеграции Энергоэффективность Высокая помехоустойчивость (при модуляции) Надежность Широкий диапазон рабочих температур Несмотря на развитие Bluetooth, Wi-Fi и других беспроводных технологий, ИК-приемники остаются экономически и технически оправданным решением во множестве задач. -
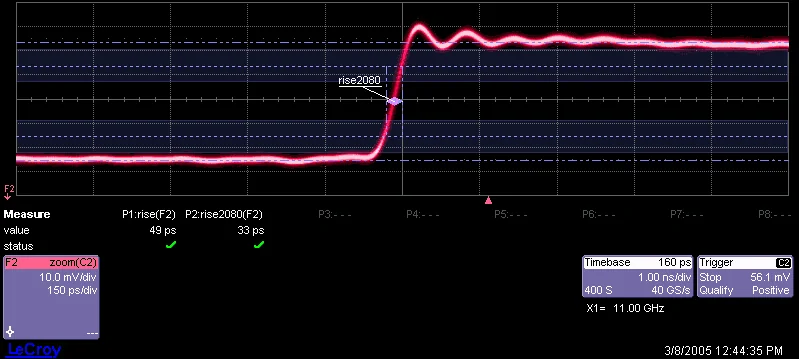 1. ВведениеАнализ сигналов, распространяющихся в протяжённых средах (например, атмосфере или океане), осложняется наличием: фоновых шумов; квазирегулярных структурных неоднородностей; случайных флуктуаций; локальных аномалий, нарушающих равновесное состояние среды. Классические методы линейной фильтрации ориентированы на подавление шума за счёт сглаживания сигнала. Однако при этом часто теряется информация о локальных скачках — именно тех особенностях, которые соответствуют аномальным неоднородностям. Предлагаемый подход основан на нелинейной обработке дискретизированного сигнала, при которой: периодические и квазирегулярные структуры сглаживаются; локальные разовые перепады усиливаются; обеспечивается высокая чувствительность к границам аномалий. Метод устраняет противоречие между необходимостью подавления фона и сохранением (или усилением) диагностически значимых перепадов сигнала. 2. Цель работыПредставить результаты численного моделирования оригинального метода нелинейной фильтрации временной структуры сложных негармонических сигналов, предназначенного для выявления аномалий в протяжённых средах. 3. Научная новизнаПредложен алгоритм нелинейной фильтрации, позволяющий: выявлять аномальные неоднородности в частично организованной структуре сигнала; определять положение границ таких неоднородностей; обеспечивать устойчивость к шумам и псевдорегулярным структурам. Метод сочетает свойства медианных, рекурсивных, итеративных и робастных фильтров, однако обладает рядом принципиальных отличий. 4. Методология4.1. Общая идея алгоритмаПусть задан дискретный сигнал S={s1,s2,...,sN}S = \{s_1, s_2, ..., s_N\}S={s1,s2,...,sN} Алгоритм включает последовательность операций накопления, сравнения и логарифмического преобразования интегральных характеристик сигнала. Основной принцип — сравнение поведения сигнала на симметричных участках трассы с использованием скользящих накопленных сумм. 4.2. Базовый алгоритм фильтрацииЭтап 1. Деление текущего интервалаТекущий временной интервал регистрации сигнала делится пополам с шагом, равным шагу дискретизации. Этап 2. Логарифм отношенияДля нарастающих интервалов вычисляется: ln(S1S2)\ln \left( \frac{S_1}{S_2} \right)ln(S2S1) где S1S_1S1 и S2S_2S2 — интегральные значения сигнала на соответствующих полуинтервалах. Шаг приращения равен удвоенному шагу дискретизации. Этап 3. НормировкаПолученный ряд умножается на отношение: Nn\frac{N}{n}nN где NNN — общее число отсчётов, nnn — число отсчётов в текущем интервале. Этап 4. Выделение аномалииАномалия определяется как: выраженный провал во временном ходе отфильтрованного сигнала; чем уже и глубже провал — тем контрастнее неоднородность. 5. Формирование модельной структуры неоднородностиДля точного определения положения границ используется более детальная процедура. 5.1. Формирование двух накопительных последовательностейИз исходных отсчётов формируются: Последовательность типа A — накопление от начала к концу. Последовательность типа B — накопление от конца к началу. Шаг приращения соответствует требуемому разрешению. 5.2. Формирование дополнительных отсчётовДля каждой накопительной величины: для типа A формируется AD — сумма последующих отсчётов; для типа B формируется BD — сумма предшествующих отсчётов. 5.3. Нормированное логарифмическое преобразованиеВычисляется: ln(min(AD,A)max(AD,A))\ln \left( \frac{\min(AD, A)}{\max(AD, A)} \right)ln(max(AD,A)min(AD,A)) Аналогично для пары B и BD. Результат нормируется на число исходных отсчётов, формируя последовательности: IAn,IBnIA_n, \quad IB_nIAn,IBn Эти величины пропорциональны средним коэффициентам ослабления среды на соответствующих участках. 5.4. Поиск общей части ΔРассматриваются отношения: IA1IBn,IA2IBn−1,…,IAnIB1\frac{IA_1}{IB_n}, \frac{IA_2}{IB_{n-1}}, \dots, \frac{IA_n}{IB_1}IBnIA1,IBn−1IA2,…,IB1IAn при условии, что соответствующие участки имеют общую часть: Δ=12 шага дискретизации\Delta = \frac{1}{2} \text{ шага дискретизации}Δ=21 шага дискретизации Находится глобальный минимум: IAk/IBn−k+1IA_k / IB_{n-k+1}IAk/IBn−k+1 5.5. Формирование основной цифровой последовательностиОсновная последовательность строится: из IAnIA_nIAn при n>kn > kn>k; из IBnIB_nIBn при n≤kn \le kn≤k. 5.6. Определение границ аномалииМаксимальный перепад основной последовательности → ближняя граница. Вторичный перепад → дальняя граница. 6. Численное моделированиеПроведено сравнение предложенной фильтрации с: линейной фильтрацией (LINF), медианной фильтрацией (MEDF). Моделирование выполнялось для экспоненциально спадающего сигнала длиной 50 отсчётов с перепадом в центре выборки. Использовались три отношения сигнал : перепад : шум: SIG1 — 10:1:1 SIG2 — 10:1:5 SIG3 — 10:1:10 7. Критерий эффективностиИспользовалось отношение дисперсий: σфильтр2σисходный2\frac{\sigma^2_{\text{фильтр}}}{\sigma^2_{\text{исходный}}}σисходный2σфильтр2 Отдельно анализировались участки до и после перепада. Для предложенной фильтрации (GRAN): значения DISP1 и DISP2 существенно превышают 1; это указывает на нелинейное усиление локального перепада; чувствительность возрастает при увеличении шумовой компоненты. Линейная и медианная фильтрации не обеспечивают сопоставимого выделения перепада при высоком уровне шума. 8. Сопоставление с известными методамиПредлагаемая фильтрация имеет общие черты со следующими методами: 8.1. Медианная фильтрацияподавление повторяющихся выбросов; сохранение одиночных перепадов. 8.2. Рекурсивная фильтрацияпрогнозирование гладкости; зависимость от порядка фильтра. 8.3. Итеративная обработкапоследовательное изменение порога дискриминации. 8.4. Робастные методыслабая чувствительность к малым возмущениям входных данных. 9. Преимущества предложенного методаИсключается усиление случайных мелких перепадов. Порядок фильтрации автоматически возрастает с длиной интервала. Используется адаптивный порог выявления перепадов. Отсутствуют отрицательные значения сигнала. Не требуется частотное подавление шумов. Робастность возрастает от центра выборки к её краям. Слабо зависит от длины выборки. Прост в аппаратурной реализации. Обеспечивает высокое быстродействие. 10. ВыводыЧисленное моделирование показало, что предложенный метод нелинейной фильтрации: эффективно выделяет локальные перепады сигнала; устойчив к шуму; подавляет псевдорегулярную структуру; превосходит линейные и медианные фильтры в условиях высокого уровня шума. Метод особенно перспективен для анализа сигналов обратного рассеяния в протяжённых средах, включая атмосферные приложения. 11. ЛитератураПолканов Ю.А. Способ определения положения оптической неоднородности атмосферы. Авт. свид-во СССР №1448907, кл. G01W1/00, 1988. Полканов Ю.А. Выявление аномальной неоднородности на фоне псевдорегулярной структуры сложного спадающего сигнала. Вестник БГУ, Серия 1, 1991. Полканов Ю.А. Об одной возможности выделения аномальной неоднородности атмосферы (Метод нелинейной фильтрации). Оптика атмосферы и океана, 1992.
1. ВведениеАнализ сигналов, распространяющихся в протяжённых средах (например, атмосфере или океане), осложняется наличием: фоновых шумов; квазирегулярных структурных неоднородностей; случайных флуктуаций; локальных аномалий, нарушающих равновесное состояние среды. Классические методы линейной фильтрации ориентированы на подавление шума за счёт сглаживания сигнала. Однако при этом часто теряется информация о локальных скачках — именно тех особенностях, которые соответствуют аномальным неоднородностям. Предлагаемый подход основан на нелинейной обработке дискретизированного сигнала, при которой: периодические и квазирегулярные структуры сглаживаются; локальные разовые перепады усиливаются; обеспечивается высокая чувствительность к границам аномалий. Метод устраняет противоречие между необходимостью подавления фона и сохранением (или усилением) диагностически значимых перепадов сигнала. 2. Цель работыПредставить результаты численного моделирования оригинального метода нелинейной фильтрации временной структуры сложных негармонических сигналов, предназначенного для выявления аномалий в протяжённых средах. 3. Научная новизнаПредложен алгоритм нелинейной фильтрации, позволяющий: выявлять аномальные неоднородности в частично организованной структуре сигнала; определять положение границ таких неоднородностей; обеспечивать устойчивость к шумам и псевдорегулярным структурам. Метод сочетает свойства медианных, рекурсивных, итеративных и робастных фильтров, однако обладает рядом принципиальных отличий. 4. Методология4.1. Общая идея алгоритмаПусть задан дискретный сигнал S={s1,s2,...,sN}S = \{s_1, s_2, ..., s_N\}S={s1,s2,...,sN} Алгоритм включает последовательность операций накопления, сравнения и логарифмического преобразования интегральных характеристик сигнала. Основной принцип — сравнение поведения сигнала на симметричных участках трассы с использованием скользящих накопленных сумм. 4.2. Базовый алгоритм фильтрацииЭтап 1. Деление текущего интервалаТекущий временной интервал регистрации сигнала делится пополам с шагом, равным шагу дискретизации. Этап 2. Логарифм отношенияДля нарастающих интервалов вычисляется: ln(S1S2)\ln \left( \frac{S_1}{S_2} \right)ln(S2S1) где S1S_1S1 и S2S_2S2 — интегральные значения сигнала на соответствующих полуинтервалах. Шаг приращения равен удвоенному шагу дискретизации. Этап 3. НормировкаПолученный ряд умножается на отношение: Nn\frac{N}{n}nN где NNN — общее число отсчётов, nnn — число отсчётов в текущем интервале. Этап 4. Выделение аномалииАномалия определяется как: выраженный провал во временном ходе отфильтрованного сигнала; чем уже и глубже провал — тем контрастнее неоднородность. 5. Формирование модельной структуры неоднородностиДля точного определения положения границ используется более детальная процедура. 5.1. Формирование двух накопительных последовательностейИз исходных отсчётов формируются: Последовательность типа A — накопление от начала к концу. Последовательность типа B — накопление от конца к началу. Шаг приращения соответствует требуемому разрешению. 5.2. Формирование дополнительных отсчётовДля каждой накопительной величины: для типа A формируется AD — сумма последующих отсчётов; для типа B формируется BD — сумма предшествующих отсчётов. 5.3. Нормированное логарифмическое преобразованиеВычисляется: ln(min(AD,A)max(AD,A))\ln \left( \frac{\min(AD, A)}{\max(AD, A)} \right)ln(max(AD,A)min(AD,A)) Аналогично для пары B и BD. Результат нормируется на число исходных отсчётов, формируя последовательности: IAn,IBnIA_n, \quad IB_nIAn,IBn Эти величины пропорциональны средним коэффициентам ослабления среды на соответствующих участках. 5.4. Поиск общей части ΔРассматриваются отношения: IA1IBn,IA2IBn−1,…,IAnIB1\frac{IA_1}{IB_n}, \frac{IA_2}{IB_{n-1}}, \dots, \frac{IA_n}{IB_1}IBnIA1,IBn−1IA2,…,IB1IAn при условии, что соответствующие участки имеют общую часть: Δ=12 шага дискретизации\Delta = \frac{1}{2} \text{ шага дискретизации}Δ=21 шага дискретизации Находится глобальный минимум: IAk/IBn−k+1IA_k / IB_{n-k+1}IAk/IBn−k+1 5.5. Формирование основной цифровой последовательностиОсновная последовательность строится: из IAnIA_nIAn при n>kn > kn>k; из IBnIB_nIBn при n≤kn \le kn≤k. 5.6. Определение границ аномалииМаксимальный перепад основной последовательности → ближняя граница. Вторичный перепад → дальняя граница. 6. Численное моделированиеПроведено сравнение предложенной фильтрации с: линейной фильтрацией (LINF), медианной фильтрацией (MEDF). Моделирование выполнялось для экспоненциально спадающего сигнала длиной 50 отсчётов с перепадом в центре выборки. Использовались три отношения сигнал : перепад : шум: SIG1 — 10:1:1 SIG2 — 10:1:5 SIG3 — 10:1:10 7. Критерий эффективностиИспользовалось отношение дисперсий: σфильтр2σисходный2\frac{\sigma^2_{\text{фильтр}}}{\sigma^2_{\text{исходный}}}σисходный2σфильтр2 Отдельно анализировались участки до и после перепада. Для предложенной фильтрации (GRAN): значения DISP1 и DISP2 существенно превышают 1; это указывает на нелинейное усиление локального перепада; чувствительность возрастает при увеличении шумовой компоненты. Линейная и медианная фильтрации не обеспечивают сопоставимого выделения перепада при высоком уровне шума. 8. Сопоставление с известными методамиПредлагаемая фильтрация имеет общие черты со следующими методами: 8.1. Медианная фильтрацияподавление повторяющихся выбросов; сохранение одиночных перепадов. 8.2. Рекурсивная фильтрацияпрогнозирование гладкости; зависимость от порядка фильтра. 8.3. Итеративная обработкапоследовательное изменение порога дискриминации. 8.4. Робастные методыслабая чувствительность к малым возмущениям входных данных. 9. Преимущества предложенного методаИсключается усиление случайных мелких перепадов. Порядок фильтрации автоматически возрастает с длиной интервала. Используется адаптивный порог выявления перепадов. Отсутствуют отрицательные значения сигнала. Не требуется частотное подавление шумов. Робастность возрастает от центра выборки к её краям. Слабо зависит от длины выборки. Прост в аппаратурной реализации. Обеспечивает высокое быстродействие. 10. ВыводыЧисленное моделирование показало, что предложенный метод нелинейной фильтрации: эффективно выделяет локальные перепады сигнала; устойчив к шуму; подавляет псевдорегулярную структуру; превосходит линейные и медианные фильтры в условиях высокого уровня шума. Метод особенно перспективен для анализа сигналов обратного рассеяния в протяжённых средах, включая атмосферные приложения. 11. ЛитератураПолканов Ю.А. Способ определения положения оптической неоднородности атмосферы. Авт. свид-во СССР №1448907, кл. G01W1/00, 1988. Полканов Ю.А. Выявление аномальной неоднородности на фоне псевдорегулярной структуры сложного спадающего сигнала. Вестник БГУ, Серия 1, 1991. Полканов Ю.А. Об одной возможности выделения аномальной неоднородности атмосферы (Метод нелинейной фильтрации). Оптика атмосферы и океана, 1992. -
 ВведениеКорректный запуск процессов внутри контейнера — одна из ключевых тем при разработке Docker-образов. Формально всё описано в документации Docker, однако на практике регулярно возникают неоднозначные ситуации: контейнер не останавливается корректно; сигналы не доходят до приложения; появляются zombie-процессы; PID 1 ведёт себя неожиданно. В этой статье разберём: Разницу между ENTRYPOINT и CMD. Отличие exec и shell форм. Почему критически важно, какой процесс имеет PID 1. Как правильно писать docker-entrypoint.sh. Когда и зачем использовать tini. Материал ориентирован на практическое применение и реальные сценарии. 1. ENTRYPOINT и CMD: фундаментальная разницаВ Dockerfile существуют две директивы для запуска процессов: ENTRYPOINT CMD Обе участвуют в формировании итоговой команды запуска контейнера, но выполняют разные роли. Логическая модельМожно представить их так: ENTRYPOINT + CMD = финальная команда контейнераРекомендуемая практикаENTRYPOINT — фиксированная команда (исполняемый файл или скрипт). CMD — аргументы по умолчанию, которые можно переопределить. Exec-форма и Shell-формаDocker поддерживает два синтаксиса. 1️⃣ Exec-форма (рекомендуется)ENTRYPOINT ["/bin/ping"] CMD ["it-lux.ru"]Особенности: Не используется shell. Нет подстановки переменных. Процесс запускается напрямую. Корректная обработка сигналов. После сборки: docker run pingВнутри контейнера выполнится: /bin/ping it-lux.ruПереопределение аргументов: docker run ping google.comТеперь выполнится: /bin/ping google.comЭто правильная архитектура: один образ — разные параметры запуска. 2️⃣ Shell-форма (менее предпочтительна)ENTRYPOINT ping it-lux.ruФактически Docker запустит: /bin/sh -c "ping it-lux.ru"Минусы: Появляется промежуточный shell. Сигналы могут не дойти до целевого процесса. PID 1 становится shell. Shell-форма допустима, но требует понимания последствий. 2. Проблема PID 1В Linux процесс с PID 1 — особый. Особенности: Он не имеет обработчиков сигналов по умолчанию. Он ответственен за "усыновление" осиротевших процессов. Он должен корректно обрабатывать SIGTERM. Docker при остановке контейнера выполняет: docker stop → отправляет SIGTERM → PID 1Если PID 1: не обрабатывает сигнал, не передаёт его дочерним процессам, то контейнер завершится некорректно (force kill через SIGKILL спустя timeout). 3. Ошибка с docker-entrypoint.shТипичный пример: FROM centos:7 COPY docker-entrypoint.sh /usr/bin ENTRYPOINT ["/usr/bin/docker-entrypoint.sh"]Содержимое: #!/bin/bash ping ya.ruЧто происходит? PID 1 — это: /bin/bash /usr/bin/docker-entrypoint.shА ping — дочерний процесс. При docker stop: SIGTERM получает bash bash может не передать сигнал дальше ping зависает появляются zombie-процессы Это некорректная архитектура контейнера. 4. Правильное решение — execВ bash существует встроенная команда exec. Она: заменяет текущий процесс передаёт ему PID не создаёт дополнительный уровень Правильный вариант: #!/bin/bash exec ping ya.ruТеперь: PID 1 → pingКонтейнер завершится корректно. 5. Использование CMD внутри entrypointБолее гибкий вариант: ENTRYPOINT ["/usr/bin/docker-entrypoint.sh"] CMD ["ya.ru"]Скрипт: #!/bin/bash # подготовительные действия set -- ping "$@" exec "$@"Разбор: $@ — все аргументы контейнера. set -- — формирует новую команду. exec "$@" — запускает её как PID 1. Запуск: docker run ping google.comРезультат: PID 1 → ping google.comЭто production-подход. 6. Когда одного exec недостаточноТеперь усложним сценарий. Допустим, запускается: Jenkins Apache Zabbix server Такие системы активно создают дочерние процессы. Примеры: Jenkins Zabbix Apache HTTP Server Если дочерние процессы: завершаются некорректно, остаются "осиротевшими", то PID 1 должен их "подчищать". Но большинство приложений: не реализуют init-поведение, не умеют корректно reaping zombie-процессов. 7. Решение — tiniЗдесь используется tini. Минималистичный init для контейнеров. Корректно проксирует сигналы. Убирает zombie-процессы. Работает как PID 1. Название — это "init" наоборот. Как подключить tiniПример Dockerfile: FROM debian:stable RUN apt-get update && apt-get install -y tini ENTRYPOINT ["/usr/bin/tini", "--"] CMD ["your-app"]Теперь: PID 1 → tini PID 7 → your-appЧто делает tini: Получает SIGTERM. Передаёт сигнал дочернему процессу. Reap'ит zombie-процессы. Корректно завершает контейнер. Это production best practice. 8. Почему bash ≠ tiniBash как PID 1 tini как PID 1 Не проксирует сигналы корректно Проксирует Не предназначен как init Предназначен Может терять SIGTERM Корректно передаёт Не чистит zombie Чистит Это принципиально разные роли. 9. Итоговые рекомендации (Best Practices)Используйте exec-форму всегда, когда возможно. В docker-entrypoint.sh обязательно применяйте exec. Разделяйте: ENTRYPOINT — исполняемый файл CMD — аргументы по умолчанию Если приложение создаёт дочерние процессы — используйте tini. Проверяйте, кто имеет PID 1: docker exec -it container ps auxЗаключениеНа простых примерах всё работает и без этих нюансов. Однако при усложнении логики контейнера: появляются проблемы с остановкой, теряются сигналы, возникают zombie-процессы, контейнер завершает работу некорректно. Docker упрощает деплой, но не отменяет фундаментальные принципы работы процессов в Linux. Понимание: роли PID 1, различий exec и shell, корректного построения entrypoint, необходимости tini позволяет создавать production-ready Docker-образы, которые ведут себя предсказуемо и корректно в любой среде.
ВведениеКорректный запуск процессов внутри контейнера — одна из ключевых тем при разработке Docker-образов. Формально всё описано в документации Docker, однако на практике регулярно возникают неоднозначные ситуации: контейнер не останавливается корректно; сигналы не доходят до приложения; появляются zombie-процессы; PID 1 ведёт себя неожиданно. В этой статье разберём: Разницу между ENTRYPOINT и CMD. Отличие exec и shell форм. Почему критически важно, какой процесс имеет PID 1. Как правильно писать docker-entrypoint.sh. Когда и зачем использовать tini. Материал ориентирован на практическое применение и реальные сценарии. 1. ENTRYPOINT и CMD: фундаментальная разницаВ Dockerfile существуют две директивы для запуска процессов: ENTRYPOINT CMD Обе участвуют в формировании итоговой команды запуска контейнера, но выполняют разные роли. Логическая модельМожно представить их так: ENTRYPOINT + CMD = финальная команда контейнераРекомендуемая практикаENTRYPOINT — фиксированная команда (исполняемый файл или скрипт). CMD — аргументы по умолчанию, которые можно переопределить. Exec-форма и Shell-формаDocker поддерживает два синтаксиса. 1️⃣ Exec-форма (рекомендуется)ENTRYPOINT ["/bin/ping"] CMD ["it-lux.ru"]Особенности: Не используется shell. Нет подстановки переменных. Процесс запускается напрямую. Корректная обработка сигналов. После сборки: docker run pingВнутри контейнера выполнится: /bin/ping it-lux.ruПереопределение аргументов: docker run ping google.comТеперь выполнится: /bin/ping google.comЭто правильная архитектура: один образ — разные параметры запуска. 2️⃣ Shell-форма (менее предпочтительна)ENTRYPOINT ping it-lux.ruФактически Docker запустит: /bin/sh -c "ping it-lux.ru"Минусы: Появляется промежуточный shell. Сигналы могут не дойти до целевого процесса. PID 1 становится shell. Shell-форма допустима, но требует понимания последствий. 2. Проблема PID 1В Linux процесс с PID 1 — особый. Особенности: Он не имеет обработчиков сигналов по умолчанию. Он ответственен за "усыновление" осиротевших процессов. Он должен корректно обрабатывать SIGTERM. Docker при остановке контейнера выполняет: docker stop → отправляет SIGTERM → PID 1Если PID 1: не обрабатывает сигнал, не передаёт его дочерним процессам, то контейнер завершится некорректно (force kill через SIGKILL спустя timeout). 3. Ошибка с docker-entrypoint.shТипичный пример: FROM centos:7 COPY docker-entrypoint.sh /usr/bin ENTRYPOINT ["/usr/bin/docker-entrypoint.sh"]Содержимое: #!/bin/bash ping ya.ruЧто происходит? PID 1 — это: /bin/bash /usr/bin/docker-entrypoint.shА ping — дочерний процесс. При docker stop: SIGTERM получает bash bash может не передать сигнал дальше ping зависает появляются zombie-процессы Это некорректная архитектура контейнера. 4. Правильное решение — execВ bash существует встроенная команда exec. Она: заменяет текущий процесс передаёт ему PID не создаёт дополнительный уровень Правильный вариант: #!/bin/bash exec ping ya.ruТеперь: PID 1 → pingКонтейнер завершится корректно. 5. Использование CMD внутри entrypointБолее гибкий вариант: ENTRYPOINT ["/usr/bin/docker-entrypoint.sh"] CMD ["ya.ru"]Скрипт: #!/bin/bash # подготовительные действия set -- ping "$@" exec "$@"Разбор: $@ — все аргументы контейнера. set -- — формирует новую команду. exec "$@" — запускает её как PID 1. Запуск: docker run ping google.comРезультат: PID 1 → ping google.comЭто production-подход. 6. Когда одного exec недостаточноТеперь усложним сценарий. Допустим, запускается: Jenkins Apache Zabbix server Такие системы активно создают дочерние процессы. Примеры: Jenkins Zabbix Apache HTTP Server Если дочерние процессы: завершаются некорректно, остаются "осиротевшими", то PID 1 должен их "подчищать". Но большинство приложений: не реализуют init-поведение, не умеют корректно reaping zombie-процессов. 7. Решение — tiniЗдесь используется tini. Минималистичный init для контейнеров. Корректно проксирует сигналы. Убирает zombie-процессы. Работает как PID 1. Название — это "init" наоборот. Как подключить tiniПример Dockerfile: FROM debian:stable RUN apt-get update && apt-get install -y tini ENTRYPOINT ["/usr/bin/tini", "--"] CMD ["your-app"]Теперь: PID 1 → tini PID 7 → your-appЧто делает tini: Получает SIGTERM. Передаёт сигнал дочернему процессу. Reap'ит zombie-процессы. Корректно завершает контейнер. Это production best practice. 8. Почему bash ≠ tiniBash как PID 1 tini как PID 1 Не проксирует сигналы корректно Проксирует Не предназначен как init Предназначен Может терять SIGTERM Корректно передаёт Не чистит zombie Чистит Это принципиально разные роли. 9. Итоговые рекомендации (Best Practices)Используйте exec-форму всегда, когда возможно. В docker-entrypoint.sh обязательно применяйте exec. Разделяйте: ENTRYPOINT — исполняемый файл CMD — аргументы по умолчанию Если приложение создаёт дочерние процессы — используйте tini. Проверяйте, кто имеет PID 1: docker exec -it container ps auxЗаключениеНа простых примерах всё работает и без этих нюансов. Однако при усложнении логики контейнера: появляются проблемы с остановкой, теряются сигналы, возникают zombie-процессы, контейнер завершает работу некорректно. Docker упрощает деплой, но не отменяет фундаментальные принципы работы процессов в Linux. Понимание: роли PID 1, различий exec и shell, корректного построения entrypoint, необходимости tini позволяет создавать production-ready Docker-образы, которые ведут себя предсказуемо и корректно в любой среде. -
Всем привет! Дорогие друзья кто мучается с прошивкой и софтом для полок СХД HPE 3par 7000, 7400, 8000, 8400 может и к другим подходиит, хз.. Если у вас есть вопросы по данным СХД или вы хотите обсудить проблемы HPE 3par заходите в наш телеграмм канал В общем нашел я оромный сборник с прошивками и софтом, ниже список сделаю, он не полный. HPE 3PAR INFORM OS 3 HPE Service Processor 4, 5 образы ISO HPE_3PAR_INFORM_OS 3.2.1 HPE_3PAR_INFORM_OS 3.2.2 MU4 HPE_3PAR_INFORM_OS 3.2.2 MU6 HPE_3PAR_INFORM_OS 3.3.1 MU1 HPE_3PAR_INFORM_OS 3.3.1 MU2 HPE_3PAR_INFORM_OS 3.3.1 MU3 HPE_3PAR_INFORM_OS 3.3.1 MU5 HPE_3PAR_INFORM_OS 3.3.2 MU1 Firmware Proliant SP 4 SP 5 SSMC Witness 3PAR_Management_Console_4.7.3_QR482-11188.iso 3PAR_StoreServ_NODE_Maintenance.pptx.pptx 3PAR_SW_Upgrade_Tool_U019_QR482-11400.iso HPE_3PAR_StoreServe_Management_Console_3.5_QR482-11398.iso HPE_3PAR_SW_Upgrade_Tool_024_QR482-11470.iso HPE_3PAR_SW_Upgrade_Tool_025_QR482-11477.iso HPE_3PAR_SW_Upgrade_Tool_026_QR482-11489.iso HPE_3PAR_SW_Upgrade_Tool_029_QR482-11507.iso HPE_3PAR_SW_Upgrade_Tool_030_QR482-11517.iso HPE_3PAR_SW_Upgrade_Tool_031_QR482-11520.iso ВОТ ЭТА ССЫЛКА
-
 Во время технического собеседования в крупную компанию мне задали простой вопрос: что такое Load Average? Формально ответить несложно — это «средняя загрузка системы за 1, 5 и 15 минут». Но если копнуть глубже, возникает ряд неудобных вопросов: Что именно усредняется? С какой частотой происходит измерение? Какие процессы считаются «ожидающими ресурсы»? Почему при кратковременных пиках мы не видим резких скачков? Почему Load Average = 1 соответствует 100% загрузке одноядерной системы? Если вас интересует не бытовое, а точное техническое понимание, разберёмся детально — с опорой на исходный код ядра Linux. Что такое Load Average (LA)В системах Linux и UNIX Load Average — это показатель среднего количества процессов: находящихся в состоянии RUNNING (исполняются или готовы к выполнению), находящихся в состоянии UNINTERRUPTIBLE (обычно ожидание I/O). Три значения, которые показывает команда uptime, соответствуют окнам: 1 минута 5 минут 15 минут Важно: Load Average — это не процент загрузки CPU. Это среднее количество активных (или ожидающих) задач. Для одноядерной системы: LA = 1 → процессор полностью занят LA < 1 → процессор простаивает часть времени LA > 1 → есть очередь процессов Где «подвох» в стандартном объяснении1. Это не арифметическое среднееЕсли бы LA считался как обычное среднее арифметическое, возникал бы вопрос о частоте дискретизации: считаем каждую секунду? каждые 10 мс? раз в минуту? Чем выше частота измерения — тем меньше получилось бы среднее значение. Но в Linux используется экспоненциальное сглаживание, а не классическое среднее. 2. Кто такие «ожидающие ресурсы»?Согласно исходному коду ядра Linux, учитываются процессы в состояниях: TASK_RUNNING TASK_UNINTERRUPTIBLEТо есть: задачи, выполняющиеся на CPU; задачи, ожидающие завершения операций ввода-вывода (например, медленный диск или NFS). Именно поэтому высокий Load Average может быть при низкой загрузке CPU — если система «застряла» на I/O. Как именно считается Load Average в LinuxРеализация находится в ядре Linux (например, в версии 2.4 — timer.c и sched.h). Ключевые факты:Измерение происходит каждые 5 секунд Используется фиксированная точка (fixed-point arithmetic) Применяется формула экспоненциального затухания Константы: #define LOAD_FREQ (5*HZ) /* интервал 5 секунд */ #define EXP_1 1884 /* коэффициент для 1 минуты */ #define EXP_5 2014 #define EXP_15 2037Формула расчётаВ упрощённом виде: Lnew=Lold⋅e−Δt/T+n⋅(1−e−Δt/T)L_{new} = L_{old} \cdot e^{-Δt/T} + n \cdot (1 - e^{-Δt/T})Lnew=Lold⋅e−Δt/T+n⋅(1−e−Δt/T) где: LLL — текущее значение Load Average nnn — число активных задач TTT — окно усреднения (1, 5, 15 минут) Δt=5Δt = 5Δt=5 секунд Это дискретная форма экспоненциального сглаживания. Почему используется экспонентаФормула основана на законе экспоненциального распада: dLdt=−1T(L−n)\frac{dL}{dt} = -\frac{1}{T}(L - n)dtdL=−T1(L−n) Смысл: если процессов больше текущего LA → показатель растёт если меньше → показатель экспоненциально уменьшается чем больше окно (15 минут), тем медленнее реакция Это обеспечивает: сглаживание кратковременных пиков устойчивость к «шуму» предсказуемую динамику Почему не видно резких скачков?Представим, что вы запустили 100 коротких процессов. Логично ожидать, что LA резко взлетит. Но этого не происходит, потому что: измерение идёт раз в 5 секунд используется экспоненциальное сглаживание старые значения затухают постепенно Экспонента выполняет роль фильтра низких частот. Почему LA = 1 означает 100% загрузку одноядерной системыПри постоянном числе процессов nnn: если n>Ln > Ln>L → LA растёт к n если n<Ln < Ln<L → LA уменьшается к n Если на одноядерной системе: в каждый момент времени активен ровно 1 процесс, очереди нет, то система полностью загружена — и LA стабилизируется на 1. Если LA > 1 — появляется очередь. Важные нюансы1. Load Average учитывает I/OЕсли процессы ждут диск или NFS, LA растёт, даже если CPU простаивает. 2. На многоядерных системахЕсли у вас 8 ядер: LA = 8 → система полностью загружена LA > 8 → есть очередь 3. Это не мгновенная метрикаLA показывает тренд, а не текущую загрузку. Ограничения моделиЭкспоненциальная модель предполагает: плавное изменение нагрузки отсутствие «жёстких» ограничений пропускной способности В реальности же: CPU имеет конечную пропускную способность I/O может быть узким местом высокие значения LA не всегда означают CPU-bound систему Поэтому интерпретировать Load Average нужно вместе с: top htop iostat vmstat ВыводыLoad Average — это экспоненциально сглаженное среднее количества активных процессов. Измерение происходит каждые 5 секунд. Учитываются процессы в состояниях RUNNING и UNINTERRUPTIBLE. Это не процент загрузки CPU. Значение > числа ядер означает наличие очереди. Главное: Load Average — это математическая модель сглаживания нагрузки, а не прямой счётчик занятости процессора.
Во время технического собеседования в крупную компанию мне задали простой вопрос: что такое Load Average? Формально ответить несложно — это «средняя загрузка системы за 1, 5 и 15 минут». Но если копнуть глубже, возникает ряд неудобных вопросов: Что именно усредняется? С какой частотой происходит измерение? Какие процессы считаются «ожидающими ресурсы»? Почему при кратковременных пиках мы не видим резких скачков? Почему Load Average = 1 соответствует 100% загрузке одноядерной системы? Если вас интересует не бытовое, а точное техническое понимание, разберёмся детально — с опорой на исходный код ядра Linux. Что такое Load Average (LA)В системах Linux и UNIX Load Average — это показатель среднего количества процессов: находящихся в состоянии RUNNING (исполняются или готовы к выполнению), находящихся в состоянии UNINTERRUPTIBLE (обычно ожидание I/O). Три значения, которые показывает команда uptime, соответствуют окнам: 1 минута 5 минут 15 минут Важно: Load Average — это не процент загрузки CPU. Это среднее количество активных (или ожидающих) задач. Для одноядерной системы: LA = 1 → процессор полностью занят LA < 1 → процессор простаивает часть времени LA > 1 → есть очередь процессов Где «подвох» в стандартном объяснении1. Это не арифметическое среднееЕсли бы LA считался как обычное среднее арифметическое, возникал бы вопрос о частоте дискретизации: считаем каждую секунду? каждые 10 мс? раз в минуту? Чем выше частота измерения — тем меньше получилось бы среднее значение. Но в Linux используется экспоненциальное сглаживание, а не классическое среднее. 2. Кто такие «ожидающие ресурсы»?Согласно исходному коду ядра Linux, учитываются процессы в состояниях: TASK_RUNNING TASK_UNINTERRUPTIBLEТо есть: задачи, выполняющиеся на CPU; задачи, ожидающие завершения операций ввода-вывода (например, медленный диск или NFS). Именно поэтому высокий Load Average может быть при низкой загрузке CPU — если система «застряла» на I/O. Как именно считается Load Average в LinuxРеализация находится в ядре Linux (например, в версии 2.4 — timer.c и sched.h). Ключевые факты:Измерение происходит каждые 5 секунд Используется фиксированная точка (fixed-point arithmetic) Применяется формула экспоненциального затухания Константы: #define LOAD_FREQ (5*HZ) /* интервал 5 секунд */ #define EXP_1 1884 /* коэффициент для 1 минуты */ #define EXP_5 2014 #define EXP_15 2037Формула расчётаВ упрощённом виде: Lnew=Lold⋅e−Δt/T+n⋅(1−e−Δt/T)L_{new} = L_{old} \cdot e^{-Δt/T} + n \cdot (1 - e^{-Δt/T})Lnew=Lold⋅e−Δt/T+n⋅(1−e−Δt/T) где: LLL — текущее значение Load Average nnn — число активных задач TTT — окно усреднения (1, 5, 15 минут) Δt=5Δt = 5Δt=5 секунд Это дискретная форма экспоненциального сглаживания. Почему используется экспонентаФормула основана на законе экспоненциального распада: dLdt=−1T(L−n)\frac{dL}{dt} = -\frac{1}{T}(L - n)dtdL=−T1(L−n) Смысл: если процессов больше текущего LA → показатель растёт если меньше → показатель экспоненциально уменьшается чем больше окно (15 минут), тем медленнее реакция Это обеспечивает: сглаживание кратковременных пиков устойчивость к «шуму» предсказуемую динамику Почему не видно резких скачков?Представим, что вы запустили 100 коротких процессов. Логично ожидать, что LA резко взлетит. Но этого не происходит, потому что: измерение идёт раз в 5 секунд используется экспоненциальное сглаживание старые значения затухают постепенно Экспонента выполняет роль фильтра низких частот. Почему LA = 1 означает 100% загрузку одноядерной системыПри постоянном числе процессов nnn: если n>Ln > Ln>L → LA растёт к n если n<Ln < Ln<L → LA уменьшается к n Если на одноядерной системе: в каждый момент времени активен ровно 1 процесс, очереди нет, то система полностью загружена — и LA стабилизируется на 1. Если LA > 1 — появляется очередь. Важные нюансы1. Load Average учитывает I/OЕсли процессы ждут диск или NFS, LA растёт, даже если CPU простаивает. 2. На многоядерных системахЕсли у вас 8 ядер: LA = 8 → система полностью загружена LA > 8 → есть очередь 3. Это не мгновенная метрикаLA показывает тренд, а не текущую загрузку. Ограничения моделиЭкспоненциальная модель предполагает: плавное изменение нагрузки отсутствие «жёстких» ограничений пропускной способности В реальности же: CPU имеет конечную пропускную способность I/O может быть узким местом высокие значения LA не всегда означают CPU-bound систему Поэтому интерпретировать Load Average нужно вместе с: top htop iostat vmstat ВыводыLoad Average — это экспоненциально сглаженное среднее количества активных процессов. Измерение происходит каждые 5 секунд. Учитываются процессы в состояниях RUNNING и UNINTERRUPTIBLE. Это не процент загрузки CPU. Значение > числа ядер означает наличие очереди. Главное: Load Average — это математическая модель сглаживания нагрузки, а не прямой счётчик занятости процессора. -
Есть команды, которые надо вводить с холодной головой и полным осознанием последствий. rm -rf / — очевидный пример. Но среди разработчиков и DevOps есть своя версия этой русской рулетки — git push --force. Я работал тогда в продуктовой компании — делали SaaS-платформу для управления проектами. Небольшая команда, человек двенадцать, хороший продукт, живые клиенты, нормальный процесс разработки. Мы использовали GitHub, feature-ветки, pull requests, code review — всё как у взрослых. Репозиторий был защищён: ветка main заблокирована от прямых пушей, обязательный PR с одобрением от двух ревьюеров. Всё серьёзно. Но была одна маленькая деталь, которую мы упустили: ветка develop — наша основная рабочая ветка, куда мерджились все фичи перед выходом в main — была защищена только от обычного push. Не от push --force. Это упущение жило полтора года. До того утра. Антон — старший разработчик, умный, опытный, пять лет в команде — в среду утром пришёл на работу в слегка раздражённом состоянии. Накануне вечером работал из дома, что-то переделывал в своей feature-ветке, несколько раз rebase'ил на свежий develop, история коммитов запуталась. Он хотел сделать красиво — squash коммиты, причесать историю, залить обратно. Он сделал git rebase -i HEAD~15. Причесал. Сделал git push origin feature/my-branch. Получил ошибку — ветка расходилась с remote из-за rebase. Это нормально. Написал git push --force origin feature/my-branch. И тут автодополнение в его терминале сыграло злую шутку. Он не заметил. Нажал Enter. Терминал отработал молниеносно. git push --force origin develop Ветка develop теперь содержала только его пятнадцать причёсанных коммитов. Полгода работы двенадцати разработчиков — восемьсот с лишним коммитов, десятки смёрджённых feature-веток — перестали существовать в remote. Первым заметил Кирилл — он в это время делал git pull origin develop и увидел странное сообщение о том, что его локальная ветка «впереди» remote на 847 коммитов. Написал в слак: «ребят, что-то странное с develop». Я в это время пил кофе. Зашёл в GitHub. Посмотрел на историю develop. Увидел пятнадцать коммитов за подписью Антона. Поставил кружку. Написал в общий чат: «стоп, никто не делайте git pull и не трогайте develop». Антон в этот момент только что дошёл до своего рабочего места — потому что через тридцать секунд в чате появилось его сообщение: «ребята, кажется, я что-то сломал». Восстановление заняло примерно двадцать минут и было почти триумфальным. Git — распределённая система. Это означает, что у каждого разработчика в локальном репозитории была актуальная копия develop на момент последнего git fetch. У Кирилла — который как раз делал git pull в момент инцидента — локальная ветка содержала все 847 коммитов. # На машине Кирилла: git log origin/develop..develop --oneline | wc -l # 847 # Пришлось временно снять все защиты с ветки в GitHub # и залить обратно правильную историю git push --force origin develop Через двадцать минут develop снова содержал все 847 коммитов. Все локальные репозитории сделали git fetch. Ничего не потерялось. Антон написал мне в личку: «Максим, я понимаю что случилось. Хочу объяснить». Мы созвонились. Он рассказал про автодополнение, про то, как перепутал ветки. Голос у него был как у человека, который ещё не понял, уволен он или нет. Я сказал ему три вещи. Первое: никто ничего не потерял, всё восстановлено, все живы. Второе: это системная ошибка, не личная — защита ветки была настроена неправильно, и это моя ответственность как DevOps. Третье: мы немедленно это исправим. В тот же день мы включили защиту от force push на develop. Добавили в onboarding раздел «Никогда не используй git push --force без явного указания feature-ветки». Везде заменили --force на --force-with-lease — он проверяет что remote не изменился с момента вашего последнего fetch, и отказывает если кто-то уже запушил. Антон остался в команде. Ещё через полгода стал тимлидом. Самый важный вывод из этой истории не технический. Технический прост: защищайте все ветки от force push, используйте --force-with-lease, настройте алиасы. Важный вывод другой: реакция команды на инцидент определяет культуру команды. Можно было устроить показательную порку. Вместо этого мы исправили систему — и получили разработчика, который с тех пор параноидально аккуратен с git и научил этому ещё троих новых. Ошибки надо исправлять в системе. Не в людях. А git push --force без явного указания ветки — это как ходить с заряженным пистолетом без предохранителя. Рано или поздно что-то нажмётся не то.
-
Эта история не о катастрофе — она о тех моментах, когда система работает именно так, как ты настроил, но совсем не так, как ты хотел. Мы запускали новый высоконагруженный сервис — рекомендательный движок. Перед запуском нужно было провести нагрузочный тест: убедиться что сервис держит планируемые 500 rps. Я накануне настроил nginx с rate limiting: 100 rps с одного IP, burst 200. Это защита от DDoS. Всё правильно, всё продуманно. На следующий день Вася из QA запустил нагрузочный тест с помощью k6 с офисного сервера. Офисный сервер имеет один внешний IP-адрес. Тест начался. Вася смотрел на метрики k6 — ошибки сыпались сразу: 503 Service Unavailable. Он написал мне: «Максим, сервис не выдерживает нагрузку, уже при 150 rps всё падает». Я зашёл в логи nginx. Увидел километры строк: [error] limiting requests, excess: 102.840 by zone "api_limit" Наш офисный сервер, с которого шёл тест, получил rate limit — и все 500 запросов в секунду, начиная со 101-го получали 503. Сервис при этом работал абсолютно нормально — его никто по-настоящему не нагружал. Я минуту просто смотрел в экран. Потом засмеялся — впервые за долгое время по-настоящему засмеялся в рабочее время. Мы добавили IP офисного нагрузочного сервера в whitelist. Провели нормальный тест. Сервис держал 800 rps без проблем. Все были довольны. Но главный урок этой истории не технический. Главный урок — это то, что перед тем как диагностировать проблему, надо убедиться что смотришь в нужное место. Вася видел ошибки и думал что сервис не справляется. Я видел ошибки и знал что это rate limit. Разница — в том, что смотрели на разные части системы. Коммуникация между QA и DevOps о том, с каких IP будет идти нагрузочный тест — теперь обязательный пункт в чеклисте перед любым нагрузочным тестированием. На ithub.uno есть хорошая статья про то, как правильно организовать этот процесс — рекомендую.
-
Есть комментарии в коде, которые являются либо руководством к действию, либо тихим криком о помощи. Комментарии с «TODO» — это обещания, которые редко выполняются. Денис, бэкенд-разработчик с которым я пересекался на одном проекте, рассказал мне эту историю как предупреждение. История произошла на его предыдущем месте работы. Был endpoint /api/debug/users — он возвращал список всех пользователей с email, именами и датами регистрации. Без всякой авторизации. Создан во время разработки, чтобы фронтенд-разработчик мог быстро проверять данные. В коде стоял комментарий: # TODO: УБРАТЬ ПЕРЕД ДЕПЛОЕМ В ПРОД!!! # Только для разработки, не для продакшна @app.route('/api/debug/users') def debug_users(): users = User.query.all() return jsonify([u.to_dict() for u in users]) Три восклицательных знака. Заглавные буквы. Всё честно. Разработчик сделал деплой. TODO не убрал — дедлайн, «потом». Потом не наступило. Endpoint жил в проде тихо и незаметно два года. Через два года при проведении security audit penetration tester обнаружил его за тридцать секунд работы с Burp Suite. База данных на тот момент содержала информацию о 340,000 пользователей. Всё это время данные были доступны любому, кто знал URL. Конца истории Денис не знает — его к тому времени уже не было в той компании. Знает только что был большой скандал и несколько уволенных. В нашей команде после этой истории появился CI-шаг: grep по всему коду на паттерны TODO.*прод, TODO.*prod, REMOVE BEFORE, DEBUG ONLY. Если находит — пайплайн падает с ошибкой. Работает без единого ложного срабатывания уже полтора года.
-
Самый коварный вид отказа систем — когда всё выглядит как работает, но не работает. Бэкап-система в этом смысле особенно опасна: вы никогда не проверяете её по-настоящему, пока не нужно восстановиться. Мой коллега Паша — педантичный и аккуратный инженер — настраивал резервное копирование для CRM-системы. Написал скрипт на bash: каждую ночь mysqldump, gzip, upload на S3. Всё логируется. При успехе в Slack приходит уведомление «Backup completed: 2.3GB». Скрипт работал восемь месяцев. Каждую ночь в Slack приходило: «Backup completed: 2.3GB». Красиво. Надёжно. Профессионально. Потом упал продакшн-сервер. Физически — сгорел диск. Паша пошёл восстанавливаться из бэкапа. Достал последний архив с S3. Распаковал. Открыл. Внутри был SQL-дамп базы данных information_schema. Не crm_production. А information_schema — системная база MySQL с метаданными: список таблиц, колонок, индексов. Никаких реальных данных. Паша открыл скрипт. Нашёл строку: mysqldump -u backup -p$PASS $DATABASE | gzip > backup.sql.gz Переменная $DATABASE. Посмотрел где она определяется: DATABASE=${DB_NAME:-information_schema} Переменная DB_NAME должна была передаваться через environment. Но при настройке cron-job он забыл добавить эту переменную. Cron запускал скрипт без переменной — скрипт использовал дефолтное значение information_schema — дамп создавался, весил 2.3GB (много метаданных за восемь месяцев), улетал на S3. Полное видимое благополучие. Восемь месяцев данных CRM были потеряны безвозвратно. После этого у нас появилось правило: бэкап-скрипт обязан проверять содержимое архива после создания. Не просто «файл существует» — а «внутри есть CREATE TABLE для нужных таблиц, INSERT строк больше нуля». И раз в месяц — тестовое восстановление в отдельную базу с проверкой количества записей. Если вы сейчас читаете это и у вас есть бэкап-система, которую вы ни разу не проверяли восстановлением — сделайте это сегодня. Не завтра. Сегодня.
-
Это история о том, почему production дашборды должны быть красного цвета, а staging — зелёного. И почему вкладки браузера надо называть. Пятница. Последний рабочий день перед длинными майскими. Я чистил старый staging кластер Kubernetes — там скопился мусор за несколько месяцев. Namespace за namespace, удаляю deployment'ы, PVC, сервисы. Всё идёт хорошо. В соседней вкладке открыт продакшн дашборд — краем глаза поглядываю на метрики. Не помню точно как это случилось — кажется, я переключился между вкладками не обратив внимания. Увидел список namespace в дашборде. Увидел namespace с именем legacy-services — его я и собирался удалить в staging. Нажал Delete. Подтвердил (да, там был confirm dialog — и я его подтвердил, потому что только что двадцать раз делал то же самое). Через тридцать секунд в слаке началось: #alerts: CRITICAL: payment-service down #alerts: CRITICAL: auth-service down #alerts: CRITICAL: user-service down Я перевёл взгляд на адресную строку. Там был URL продакшн кластера. legacy-services в продакшне — это было название, которое выбрал кто-то три года назад. В нём жило восемь критических сервисов. Дальше начался самый быстрый деплой в моей карьере. ArgoCD хранил все манифесты, кластер был жив — я удалил только namespace с содержимым, но не сам кластер. Запустил sync для всех приложений через ArgoCD. Kubernetes начал поднимать поды. Stateless сервисы встали за две-три минуты. Payment-service — за пять, потому что у него была initContainer-миграция. Auth-service — за четыре. Общее время даунтайма: семь минут двадцать секунд. Что изменилось: все дашборды теперь имеют цветовую маркировку — продакшн красным, staging жёлтым, dev зелёным. Это реализовано через плагин kubie — при переключении в prod-контекст терминал меняет цвет prompt на красный. И главное — удаление namespace теперь требует ввода имени namespace вручную. Никаких кнопок «Delete» без явного подтверждения текстом.
-
Есть баги, которые тихо портят данные и обнаруживаются через месяцы. А есть такие, которые существуют годами, всех раздражают, но никто не может их воспроизвести — потому что они зависят от часового пояса. Та система занималась планированием задач. Пользователь создаёт задачу на «завтра в 10:00» — система её выполняет в нужное время. Казалось бы, простейшая логика. Жалобы начались в марте. Клиенты из Екатеринбурга писали: «задачи выполняются не вовремя, иногда с опозданием на два часа». Я смотрел на логи — по нашим данным задачи выполнялись точно в срок. Поддержка закрывала тикеты: «не воспроизводится». Клиенты злились. Я взялся за это в начале апреля. Провёл два дня, читая код планировщика. Нашёл несколько мест где работа с временем выглядела подозрительно, отрефакторил — баг остался. Третий день — ревью всех datetime операций в системе. Ничего. На четвёртый день Игорь из поддержки сказал фразу, которая сразу всё объяснила: — Слушай, я заметил, что жалуются только пользователи из Екатеринбурга, Омска и вот этих городов... Он показал список. Я посмотрел на карту. Это были города в часовых поясах UTC+5 и восточнее. Зашёл на продакшн-сервер. Ввёл date. Увидел: Thu Apr 4 14:23:11 UTC 2024. Сервер работал в UTC. Это нормально. Проблема была в другом: когда пользователь из Екатеринбурга (UTC+5) создавал задачу на «завтра 10:00» через браузер, фронтенд отправлял строку 2024-04-05 10:00:00 — без timezone offset. Backend принимал её как UTC и сохранял в базу. Потом выполнял задачу в 10:00 UTC — что для пользователя в UTC+5 было 15:00 по местному времени. Пять часов разницы. Это проявилось только когда начали приходить пользователи из регионов — потому что первые клиенты и команда разработки были из Москвы (UTC+3), и у них разница была три часа, а не пять. Фикс: фронтенд теперь всегда отправляет datetime с timezone offset. Backend парсит только aware datetime объекты. На Хабре есть статья «Никогда не используйте naive datetime» — я её знал. Просто не я писал тот фрагмент. Теперь у нас есть линтер-правило, которое не даёт мержить код с naive datetime объектами.
-
Автоматизация — это прекрасно. Автоматизация без ограничений — это финансовая катастрофа. Я усвоил этот урок очень конкретным способом: через счёт от AWS на $23,000 за четыре ночных часа. Мы настраивали горизонтальный автоскейлинг для API сервиса. Логика была простая: если CPU выше 70% — добавляем инстансы. Работало замечательно в рабочие часы. Что мы не предусмотрели — верхний лимит. Мы установили minReplicas: 2 и забыли про maxReplicas. В Kubernetes HPA это означает «масштабируй сколько нужно». В 2:47 ночи наш сервис получил DDoS-атаку. Не особо сложную — просто поток запросов, каждый из которых немного нагружал CPU. Автоскейлер увидел рост CPU и начал добавлять поды. Поды поднимались, нагрузка на каждый снижалась — но общий поток атаки оставался постоянным. Автоскейлер видел всё ещё высокую нагрузку и добавлял ещё. И ещё. В 4:15 у нас работало 847 инстансов одного сервиса. Нода-группа в AWS автоматически масштабировала EC2 — тоже без ограничений. Именно в этот момент сработал billing alert и разбудил меня. Я зашёл в AWS console полусонный. Увидел цифру. Проснулся мгновенно. Мы остановили атаку через WAF (пришлось поднять и настроить с нуля, потому что «руки не доходили» раньше — за десять минут). Потом убили лишние инстансы. Написали в AWS поддержку — они вернули около $18,000 как «goodwill credit», потому что это был явно аномальный spike. $5,000 мы всё же заплатили. Что изменили: maxReplicas в каждом HPA, budget alerts с автоматическим отключением при превышении, WAF с базовыми rate-limit правилами — теперь это первое, что поднимается для нового сервиса. И чеклист «Перед включением автоскейлинга», который мы опубликовали в нашей вики и в комьюнити на ithub.uno.
-
Я долго не понимал, почему Kubernetes такой педантичный. Зачем все эти liveness probes, resource limits, PodDisruptionBudget — когда можно просто запустить контейнер и пусть работает? Потом был один день, который изменил моё отношение радикально. Мы деплоили крупное обновление — новая версия API с переработанной системой авторизации. Дата релиза была согласована с бизнесом, пресс-релиз готов, маркетинг ждёт. Всё тщательно проверено на стейджинге. Я жму deploy. Kubernetes начинает rolling update. Первые поды поднимаются — и тут Kubernetes останавливает деплой. Просто стоп. Ни один новый под не создаётся, старые не удаляются. Открываю kubectl describe pod — там написано: Readiness probe failed. Злюсь. Открываю логи пода. Вижу ошибку подключения к базе данных. Думаю: ну и что, это временная ошибка при старте, он бы сам восстановился. Хочу вручную форсировать деплой. Но что-то заставляет меня сначала проверить само соединение с базой. Открываю dashboard PostgreSQL — и вижу, что на новой версии приложения миграция схемы прошла неправильно. Один из индексов создался с ошибкой, из-за чего конкретный запрос в /api/v2/auth/check — тот самый, который проверяет readiness probe — возвращал 500. Если бы Kubernetes не остановил деплой, то старые поды с рабочей авторизацией были бы убиты, а новые — со сломанной — встали бы вместо них. Все пользователи получили бы 500 при попытке войти. Прямо в день анонса. Kubernetes оказался умнее меня. Его педантичность — которая меня так раздражала — спасла релиз. Мы откатили миграцию, исправили скрипт, прогнали ещё раз на стейджинге, задержали деплой на два часа. Бизнес поворчал — потом сказал спасибо, когда я объяснил альтернативу. С того дня я стал большим фанатом readiness probes. Не просто /healthz с ответом 200 — а настоящая проверка: соединение с базой, доступность зависимостей, корректность конфигурации.
-
Это история о том, как можно делать всё правильно — и всё равно облажаться. Потому что правильные действия, направленные не туда — это хуже бездействия. Два года назад мы запускали новый микросервис — агрегатор данных для аналитики. Я настроил мониторинг: Prometheus, Grafana, alertmanager, всё по классике. Дашборд выглядел прекрасно. Зелёный. Живой. Метрики бежали в реальном времени. Через неделю аналитики начали жаловаться: данные в отчётах иногда выглядят странно, какие-то пропуски. Я смотрел на дашборд — сервис работает, ошибок нет, очередь обрабатывается. Ещё через неделю жалобы участились. Я снова смотрел на мониторинг. Снова — всё хорошо. Начал думать, что проблема в данных источника. На четырнадцатый день Саша из аналитики подошла ко мне с конкретным примером: вот событие, которое должно было попасть в базу вчера в 14:32 — его нет. Вот ещё пять таких событий за последние две недели. Я зашёл непосредственно на сервер, посмотрел логи — и увидел сотни ошибок коннекта к базе данных. Каждую минуту. Все последние две недели. Но мониторинг показывал зелёный! Через десять минут я нашёл причину. При настройке мониторинга я указал IP-адрес сервера вручную. Потом — за день до запуска — инфраструктурная команда переехала на новые машины и IP поменялся. Я обновил конфиг сервиса, но забыл обновить конфиг Prometheus. Prometheus две недели радостно скрейпил метрики другого сервера, которому достался старый IP. Все эти две недели я смотрел на графики совершенно нормально работающего чужого сервера. Пока наш тихо терял данные. Пропущенные события восстановить не удалось. После этого я перешёл на service discovery в Prometheus — никаких статических IP. Только DNS-имена или автоматическое обнаружение. И добавил тест: alertmanager должен прислать тестовый алерт при старте — чтобы убедиться, что нотификации реально доходят.
-
Есть категория менеджеров, которые искренне верят, что перезагрузка решает все проблемы. Эту веру они несут через годы опыта работы с Windows на домашнем компьютере. Столкновение этой веры с реальностью продакшн-сервера — зрелище одновременно трагическое и поучительное. Эту историю рассказал мне Антон — DevOps в среднем онлайн-ретейлере — в баре, после второго бокала, с видом человека, который прошёл терапию, но ещё не полностью. Была пятница, около шести вечера. Их основной сервер начал подтормаживать — latency выросла раза в три. Антон уже нашёл проблему: утечка соединений в пуле базы данных, накопившаяся за неделю. Требовалось примерно двадцать минут на аккуратный фикс без рестарта. Тут появился продакт-менеджер Геннадий Витальевич. — Антон, у нас тормозит. Долго ещё? У меня через час встреча с клиентом. — Геннадий Витальевич, я нашёл проблему, фикс займёт минут двадцать, перезагрузка не нужна— — Просто перезагрузите сервер. Всегда помогает. — Нет, правда, в данном случае лучше не надо, потому что после перезагрузки будет несколько минут простоя— — Антон. Перезагрузите. Сервер. Антон перезагрузил сервер. Что он не знал — и что Геннадий Витальевич знать не мог — так это то, что накануне ночью обновился GRUB через автоматические обновления Ubuntu. Обновление прошло нормально, но файл конфигурации GRUB получил неверный UUID для корневого раздела. Система прекрасно работала — до первой перезагрузки. Сервер ушёл на перезагрузку. И не вернулся. Антон пять минут смотрел на консоль Hetzner с ошибкой Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0). Потом ещё пять минут просто сидел, не двигаясь. Дальнейшее — двухчасовая спасательная операция через rescue mode, ручное восстановление GRUB, три созвона с поддержкой хостинга и один звонок от директора с вопросом «что происходит». Геннадий Витальевич на встречу с клиентом опоздал на час пятнадцать. После этого в их компании появилось официальное правило: любая перезагрузка продакшн-сервера должна быть согласована с дежурным инженером, который проверяет чеклист из восьми пунктов. Геннадий Витальевич правило подписал. Говорят, без энтузиазма.
-
Эту историю я долго не хотел рассказывать. Не потому что она страшная — потому что она embarrassing. Но потом я прочитал пост на ithub.uno о том, что культура безопасности строится на открытости, а не на замалчивании. И решился. Было это в 2019-м. Я настраивал GitLab CI для небольшого проекта — сервис рассылки уведомлений. В процессе отладки пайплайна мне нужен был быстрый тест. Я создал файл .env.test с заглушками: DB_PASSWORD=test123, API_KEY=dummy_key_for_testing, SMTP_PASSWORD=test123. Потом написал .gitlab-ci.yml, который деплоил приложение, и указал в нём cp .env.test .env — чтобы для CI это работало. Commit. Push. Пайплайн прошёл. Всё работает. Я написал нормальный продакшн конфиг, залил через GitLab Secrets как положено — и на этом моя работа с тем проектом закончилась. Меня перевели на другой. Проект жил своей жизнью. Рассылки уходили. Никто не проверял, откуда именно берутся credentials. Через три года я вернулся на тот проект для аудита. Открыл конфиг на сервере. Увидел DB_PASSWORD=test123. Мне понадобилось секунд тридцать, чтобы понять что произошло. Оказывается, команда cp .env.test .env в пайплайне выполнялась после загрузки GitLab Secrets и перезаписывала их. Три года подряд, при каждом деплое, на сервер улетал файл с паролем test123. Самое парадоксальное: база данных была доступна только изнутри приватной сети, поэтому этот пароль де-факто ни на что не влиял. Но это — счастливое стечение обстоятельств, а не правильная архитектура. Я провёл полный security audit. Нашёл ещё две похожих проблемы — других инженеров, таких же «временных» решений, ставших постоянными. Написал документ «Как мы храним секреты» и внедрил pre-commit hook, который ищет в коде паттерны типа password=test, key=dummy, secret=123. Но test123 в том конфиге я помню с фотографической точностью. Три восклицательных знака. Заглавные буквы. Всё честно. Разработчик сделал деплой. TODO не убрал — дедлайн, «потом». Потом не наступило. Endpoint жил в проде тихо и незаметно два года. Через два года при проведении security audit penetration tester обнаружил его за тридцать секунд работы с Burp Suite. База данных на тот момент содержала информацию о 340,000 пользователей. Всё это время данные были доступны любому, кто знал URL. Конца истории Денис не знает — его к тому времени уже не было в той компании. Знает только что был большой скандал и несколько уволенных. В нашей команде после этой истории появился CI-шаг: grep по всему коду на паттерны TODO.*прод, TODO.*prod, REMOVE BEFORE, DEBUG ONLY. Если находит — пайплайн падает с ошибкой. Работает без единого ложного срабатывания уже полтора года.
-
В этой индустрии есть негласный закон: если что-то может сломаться в самый неподходящий момент — оно сломается именно тогда. Новогодняя ночь — идеальный момент для проверки этого закона. Я работал в финтех-компании. Мы делали платёжный шлюз. Нагрузка в новый год — одна из пиковых: все переводят деньги, покупают подарки в последний момент, пьют шампанское и одновременно пытаются провести транзакцию. 31 декабря, примерно в 22:00 я сидел у родителей. Оливье, телевизор, ощущение что ты наконец человек, а не придаток к ноутбуку. Дежурство официально было у Димы. Я был «вторым уровнем». В 23:58 мне позвонил Дима. Голос у него был такой, что я сразу встал из-за стола и вышел в коридор. — Макс, у нас лежит. Всё. Payment gateway не отвечает. Метрики нормальные, сервисы запущены, но транзакции не проходят. Я открыл ноутбук прямо в коридоре, на тумбочке с телефонным аппаратом эпохи СССР. Зашёл в Grafana — всё зелёное. CPU нормальный, память нормальная, сетевой трафик... стоп. Входящий — есть. Исходящий — ноль. Абсолютный ноль. Сервисы запущены, слушают порты, принимают соединения — но ничего не отправляют в ответ. В это время в телевизоре начали бить куранты. Моя мама заглянула в коридор с бокалом шампанского. Я сделал жест «одну минуту» — что в нашей профессии означает «от тридцати минут до нескольких часов». Нашёл проблему через двадцать две минуты нового года. Оказалось, в 23:55 сработал cron-job, который запускался раз в год 31 декабря для «очистки годовых логов». Скрипт удалял log-файлы старше 365 дней — разумная идея. Но через glob-паттерн он также захватывал конфигурационный файл SSL-сертификатов. Сертификаты физически никуда не делись, но конфиг, который указывал на них — исчез. Nginx перечитал конфигурацию и тихо перестал устанавливать TLS-соединения с upstream банковским API, требовавшим mutual TLS. Фикс занял четыре минуты: восстановить конфиг из git, перезапустить nginx, убедиться что транзакции пошли. Я вернулся к столу в 00:31. Шампанское было тёплым. Оливье съели без меня. А тот cron-job мы заменили нормальным logrotate с явными паттернами. И добавили тест: после каждого cron-задания запускается smoke-test платёжной цепочки. Каждую ночь. Включая 31 декабря.ии. Знает только что был большой скандал и несколько уволенных. В нашей команде после этой истории появился CI-шаг: grep по всему коду на паттерны TODO.*прод, TODO.*prod, REMOVE BEFORE, DEBUG ONLY. Если находит — пайплайн падает с ошибкой. Работает без единого ложного срабатывания уже полтора года.
