
IThub
Administrators
-
Joined
-
Last visited
Everything posted by IThub
-

 Введение: Linux в продакшене — это не просто установить и забытьПоставить Ubuntu, запустить приложение и назвать это "продакшеном" — рецепт будущей катастрофы. Настоящий production Linux — это слоёный пирог из правильного выбора дистрибутива, hardening-а, тюнинга ядра, настроенного мониторинга и чётких процедур обслуживания. Статья написана для тех, кто уже умеет работать с Linux и хочет понять почему нужно делать именно так, а не просто скопировать команды. Часть 1: Выбор дистрибутиваКритерии для production-выбораПрежде чем смотреть на дистрибутивы, определитесь с приоритетами: Стабильность vs свежесть: старые проверенные пакеты или последние версии? Коммерческая поддержка: нужен SLA от вендора или достаточно community? Цикл жизни: как долго дистрибутив будет получать security-патчи? Экосистема: есть ли готовые пакеты для вашего стека? Команда: что знает ваша команда? Переучивание дорого стоит. Ubuntu LTS ServerЦикл поддержки: 5 лет standard, 10 лет ESM (Extended Security Maintenance). Текущий LTS: 24.04 (Noble Numbat), следующий — 26.04. Ubuntu — безусловный лидер по распространённости в cloud-среде. AWS, GCP, Azure — везде Ubuntu является первым выбором по умолчанию. Огромная документация, большинство DevOps-инструментов тестируются на Ubuntu в первую очередь. Подходит для: Startups и компании без выделенного Linux-администратора Kubernetes workers и cloud-native окружения Быстрое развёртывание новых стеков Осторожно: Canonical меняет политики (snap-пакеты вместо deb без предупреждения) Обновления между LTS требуют тщательного тестирования ESM платный для > 5 машин в организации # Проверка версии и EOL даты lsb_release -a ubuntu-advantage status # Статус ESM подписки # Отключить snap если не нужен (спорно, но часто делают) sudo systemctl disable snapd --now sudo apt purge snapd Debian StableЦикл поддержки: ~3 года основная поддержка + 2 года LTS. Текущий: Debian 12 "Bookworm" (до 2028). Debian — "бабушка" большинства дистрибутивов. Её репутация: консервативная, предсказуемая, надёжная. Пакеты в Stable могут быть на 1–2 года старше апстрима, но зато они досконально протестированы. Никаких сюрпризов в 3 часа ночи. Подходит для: Серверы с длинным жизненным циклом (БД, хранилища) Инфраструктура, где стабильность важнее новых фич Встраиваемые и промышленные серверы Осторожно: Старые пакеты могут не поддерживать новые возможности (TLS 1.3 и т.п. уже везде есть, но крайние версии — нет) community-поддержка без коммерческого SLA # Debian: правильные sources.list для продакшена # Только stable, никакого testing/sid! cat /etc/apt/sources.list # deb http://deb.debian.org/debian bookworm main contrib non-free-firmware # deb http://security.debian.org/debian-security bookworm-security main # deb http://deb.debian.org/debian bookworm-updates main # Backports только для конкретных пакетов, не массово # deb http://deb.debian.org/debian bookworm-backports main RHEL / Rocky Linux / AlmaLinuxRHEL (Red Hat Enterprise Linux) — корпоративный стандарт в Enterprise-сегменте, особенно там где есть compliance требования (PCI DSS, HIPAA, FedRAMP). Платная подписка, но включает полный enterprise support от Red Hat. Rocky Linux и AlmaLinux — бинарно-совместимые клоны RHEL, бесплатные. После смерти CentOS 8 (2021) это лучшая замена для тех, кто хочет RHEL-совместимость без платы. Цикл поддержки: RHEL 9 → до 2032 (10 лет!). Rocky/Alma — аналогично. Подходит для: Enterprise-окружения с compliance требованиями Компании с контрактами Red Hat (получают support + Satellite) Там где нужен SELinux из коробки в полном объёме Серверы баз данных Oracle (Oracle Linux — тоже RHEL-клон) # Rocky Linux: подписка на обновления безопасности (бесплатно) sudo dnf install epel-release sudo dnf update # Проверка SELinux статуса getenforce # Enforcing / Permissive / Disabled sestatus # RHEL-специфика: subscription-manager sudo subscription-manager status sudo subscription-manager repos --list-enabled Alpine LinuxЦикл: rolling release (stable branches с ~2 годами поддержки). Alpine — минималистичный дистрибутив: musl libc вместо glibc, busybox вместо GNU coreutils, базовый образ 5 МБ. Создан для контейнеров и встраиваемых систем. Подходит для: Docker-образы (но есть нюансы с musl!) Edge-узлы и шлюзы с ограниченными ресурсами Безопасные "голые" серверы с минимальной поверхностью атаки Осторожно: musl libc != glibc: некоторые Go/C программы ведут себя иначе Не для тех, кто не знает что делает: меньше инструментов отладки Не для продакшена с незнакомым стеком Итоговая таблица выбора Ubuntu LTS Debian Stable Rocky/Alma Alpine Cloud-native ★★★★★ ★★★★ ★★★ ★★★★ Enterprise ★★★ ★★★ ★★★★★ ★★ Стабильность пакетов ★★★★ ★★★★★ ★★★★★ ★★★ Свежесть пакетов ★★★★ ★★★ ★★★ ★★★★★ Безопасность (OOB) ★★★★ ★★★★ ★★★★★ ★★★★ Поддержка сообщества ★★★★★ ★★★★★ ★★★★ ★★★ Простота обслуживания ★★★★★ ★★★★ ★★★ ★★ Рекомендация: для большинства команд без специфических требований — Ubuntu 24.04 LTS или Debian 12. Для enterprise с compliance — Rocky Linux 9. Для контейнеров — Alpine или Distroless. Часть 2: Первичная настройка надёжностиБазовое обновление и автоматические security-патчи# === Ubuntu / Debian === sudo apt update && sudo apt upgrade -y # Автоматические security-обновления (unattended-upgrades) sudo apt install unattended-upgrades apt-listchanges sudo dpkg-reconfigure unattended-upgrades # Конфиг /etc/apt/apt.conf.d/50unattended-upgrades # Оставляем только security, НЕ автоустанавливаем всё подряд sudo tee /etc/apt/apt.conf.d/50unattended-upgrades > /dev/null <<'EOF' Unattended-Upgrade::Allowed-Origins { "${distro_id}:${distro_codename}-security"; "${distro_id}ESMApps:${distro_codename}-apps-security"; "${distro_id}ESM:${distro_codename}-infra-security"; }; Unattended-Upgrade::AutoFixInterruptedDpkg "true"; Unattended-Upgrade::MinimalSteps "true"; Unattended-Upgrade::Remove-Unused-Dependencies "true"; Unattended-Upgrade::Automatic-Reboot "false"; // НЕ перезагружаем автоматически! Unattended-Upgrade::Mail "ops@yourcompany.com"; EOF # === Rocky / AlmaLinux === sudo dnf install dnf-automatic sudo systemctl enable --now dnf-automatic-install.timer # /etc/dnf/automatic.conf: apply_updates = yes, upgrade_type = security Правильная настройка NTPВремя — фундамент для логов, TLS-сертификатов, Kerberos, баз данных. Неправильное время = необъяснимые баги. # Современный стандарт: systemd-timesyncd (простой) или chrony (сложные сети) # chronyd рекомендован для серверов — точнее и поддерживает аппаратные часы sudo apt install chrony # Ubuntu/Debian # или: sudo dnf install chrony # RHEL-based # /etc/chrony.conf sudo tee /etc/chrony.conf > /dev/null <<'EOF' # Используем несколько источников из разных пулов pool 0.ru.pool.ntp.org iburst pool 1.ru.pool.ntp.org iburst pool 2.europe.pool.ntp.org iburst pool 3.pool.ntp.org iburst # Внутренний NTP-сервер (если есть) — даём максимальный приоритет # server 192.168.1.1 prefer iburst # Разрешаем step при большом расхождении (только при старте) makestep 1.0 3 # Дрейф файла driftfile /var/lib/chrony/drift # Логирование logdir /var/log/chrony # Синхронизация RTC (hardware clock) rtcsync EOF sudo systemctl restart chrony chronyc tracking # Статус синхронизации chronyc sources -v # Источники времени systemd: сделать сервисы по-настоящему надёжнымиБольшинство используют systemd только для start/stop/enable. Но в нём есть мощные механизмы для production-надёжности. # /etc/systemd/system/myapp.service — production-grade unit [Unit] Description=My Production Application Documentation=https://docs.mycompany.com/myapp # Зависимости — стартуем ПОСЛЕ того как сеть полностью готова After=network-online.target postgresql.service redis.service Wants=network-online.target Requires=postgresql.service # Условие запуска — только если файл конфига существует ConditionPathExists=/etc/myapp/config.yaml [Service] Type=notify # Приложение сигнализирует о готовности через sd_notify NotifyAccess=main User=myapp Group=myapp WorkingDirectory=/opt/myapp # Переменные окружения из защищённого файла (права 600, владелец root) EnvironmentFile=/etc/myapp/environment ExecStartPre=/opt/myapp/bin/validate-config # Валидация конфига перед стартом ExecStart=/opt/myapp/bin/myapp --config /etc/myapp/config.yaml ExecReload=/bin/kill -HUP $MAINPID # Graceful reload по сигналу HUP # ── Restart политика ────────────────────────────────────────────────────────── Restart=on-failure # Перезапускаем только при сбое (не при systemctl stop) RestartSec=5s # Ждём 5 секунд перед перезапуском StartLimitIntervalSec=120s # Окно для подсчёта неудачных стартов StartLimitBurst=5 # Максимум 5 перезапусков за 120 секунд # После исчерпания — юнит в Failed. Оповестить алертинг! # ── Watchdog ───────────────────────────────────────────────────────────────── # Приложение ДОЛЖНО вызывать sd_notify("WATCHDOG=1") каждые WatchdogSec/2 WatchdogSec=30s # ── Таймауты ───────────────────────────────────────────────────────────────── TimeoutStartSec=60s # Максимальное время на инициализацию TimeoutStopSec=30s # Максимальное время на graceful shutdown KillMode=mixed # Сначала SIGTERM главному процессу, потом SIGKILL всей группе KillSignal=SIGTERM # ── Лимиты ресурсов ────────────────────────────────────────────────────────── LimitNOFILE=65536 # Максимум открытых файлов LimitNPROC=4096 # Максимум процессов/потоков LimitMEMLOCK=infinity # Для приложений с mlock (JVM, некоторые БД) # ── Безопасность (sandboxing) ───────────────────────────────────────────────── NoNewPrivileges=true # Запрет повышения привилегий PrivateTmp=true # Изолированный /tmp PrivateDevices=true # Запрет доступа к /dev (кроме basic) ProtectSystem=strict # /usr, /boot, /etc только на чтение ProtectHome=true # Нет доступа к /home, /root ReadWritePaths=/var/lib/myapp /var/log/myapp # Разрешаем запись только сюда CapabilityBoundingSet=CAP_NET_BIND_SERVICE # Только если нужен порт < 1024 # ── Логирование ────────────────────────────────────────────────────────────── StandardOutput=journal StandardError=journal SyslogIdentifier=myapp [Install] WantedBy=multi-user.target # Анализ конфигурации unit (покажет ошибки и предупреждения) systemd-analyze verify /etc/systemd/system/myapp.service # Просмотр "дерева" зависимостей systemd-analyze critical-chain myapp.service # Лимиты запущенного сервиса cat /proc/$(systemctl show -p MainPID --value myapp)/limits # История перезапусков journalctl -u myapp --since "7 days ago" | grep -E "Started|Stopped|Failed" Настройка ulimits и системных лимитов# /etc/security/limits.conf — лимиты для пользователей # Для высоконагруженного приложения (например, веб-сервер, БД) myapp soft nofile 65536 myapp hard nofile 65536 myapp soft nproc 65536 myapp hard nproc 65536 # Для Elasticsearch / Kafka / других Java-приложений elasticsearch soft memlock unlimited elasticsearch hard memlock unlimited elasticsearch soft nofile 65536 elasticsearch hard nofile 65536 # /etc/systemd/system.conf — глобальные лимиты для systemd-процессов # DefaultLimitNOFILE=65536 # DefaultLimitNPROC=65536 # Проверка текущих лимитов процесса cat /proc/$(pgrep myapp | head -1)/limits Часть 3: Тюнинг ядра для продакшенаПараметры sysctl: сетьЭто самое важное для highload-серверов. По умолчанию Linux оптимизирован для десктопа, не для сервера. # /etc/sysctl.d/99-production.conf sudo tee /etc/sysctl.d/99-production.conf > /dev/null <<'EOF' # ════════════════════════════════════════════════════════════════════ # СЕТЬ — TCP/IP стек # ════════════════════════════════════════════════════════════════════ # Буферы сокетов (receive/send) # Для highload: 128 МБ (default ~212 КБ — катастрофически мало!) net.core.rmem_max = 134217728 # 128 МБ net.core.wmem_max = 134217728 net.core.rmem_default = 31457280 # 30 МБ net.core.wmem_default = 31457280 # TCP-специфичные буферы (min, default, max) net.ipv4.tcp_rmem = 4096 87380 134217728 net.ipv4.tcp_wmem = 4096 65536 134217728 # Очередь подключений (backlog) # Должна совпадать с параметром backlog в listen() вашего приложения net.core.somaxconn = 65535 net.core.netdev_max_backlog = 65535 # SYN-очередь (защита от SYN flood + highload accept) net.ipv4.tcp_max_syn_backlog = 65535 # TIME_WAIT: ускоряем переиспользование сокетов net.ipv4.tcp_tw_reuse = 1 # Переиспользовать TIME_WAIT сокеты (безопасно) net.ipv4.tcp_fin_timeout = 15 # Сократить FIN_WAIT таймаут (default 60 сек) # Диапазон эфемерных портов (для outbound соединений) net.ipv4.ip_local_port_range = 1024 65535 # Keepalive — обнаружение мёртвых соединений net.ipv4.tcp_keepalive_time = 120 # Начинаем проверку после 120 сек простоя net.ipv4.tcp_keepalive_intvl = 10 # Интервал между пробами net.ipv4.tcp_keepalive_probes = 6 # Количество проб # Алгоритм управления перегрузкой (congestion control) # BBR — современный алгоритм Google, значительно лучше для WAN и highload net.core.default_qdisc = fq net.ipv4.tcp_congestion_control = bbr # Быстрый открытый TCP (TFO) — уменьшает latency на 1 RTT # (убедитесь что клиенты поддерживают) net.ipv4.tcp_fastopen = 3 # 1=клиент, 2=сервер, 3=оба # Защита от мусорных RST пакетов net.ipv4.tcp_rfc1337 = 1 # ════════════════════════════════════════════════════════════════════ # ПАМЯТЬ # ════════════════════════════════════════════════════════════════════ # vm.swappiness: насколько агрессивно использовать swap # 0 = swap только при крайней необходимости (для БД и latency-критичных) # 10 = рекомендуется для production-серверов # 60 = default (слишком агрессивный для сервера) vm.swappiness = 10 # Dirty pages: когда сбрасывать на диск # Уменьшаем для предсказуемой latency (не даём накопиться большому flush) vm.dirty_ratio = 10 # Начинаем sync при 10% RAM dirty (default 20%) vm.dirty_background_ratio = 3 # Фоновый flush начинается при 3% (default 10%) vm.dirty_writeback_centisecs = 500 # Интервал фонового flush (5 сек, default 5 сек) vm.dirty_expire_centisecs = 3000 # Страницы считаются "старыми" через 30 сек # Overcommit (для Java/JVM и других приложений с большими heap) # 0 = эвристика ядра (default) # 1 = всегда overcommit (опасно, но нужно для некоторых БД) # 2 = строгий лимит (CommitLimit = swap + vm.overcommit_ratio% от RAM) vm.overcommit_memory = 0 # OOM Killer: штраф для критических процессов # Устанавливается через /proc или systemd OOMPolicy # (ниже — пример для PostgreSQL) # ════════════════════════════════════════════════════════════════════ # ФАЙЛОВАЯ СИСТЕМА # ════════════════════════════════════════════════════════════════════ # Максимум открытых файлов в системе (не путать с per-process ulimit) fs.file-max = 2097152 # Inotify: для приложений, следящих за файлами (Docker, K8s, IDE) fs.inotify.max_user_watches = 524288 fs.inotify.max_user_instances = 512 # AIO: асинхронный ввод-вывод (PostgreSQL, некоторые БД) fs.aio-max-nr = 1048576 # ════════════════════════════════════════════════════════════════════ # БЕЗОПАСНОСТЬ # ════════════════════════════════════════════════════════════════════ # Запрет разыменования символических ссылок в /tmp (защита от атак) fs.protected_symlinks = 1 fs.protected_hardlinks = 1 # Запрет записи в память выполняемых файлов fs.protected_regular = 2 fs.protected_fifos = 2 # ASLR (Address Space Layout Randomization) kernel.randomize_va_space = 2 # Полная рандомизация # Запрет SysRq (кроме sync/reboot — оставляем для экстренного случая) kernel.sysrq = 16 # 16 = только sync # Защита от Spectre/Meltdown через ptrace kernel.yama.ptrace_scope = 1 # Core dumps только в определённую директорию kernel.core_pattern = /var/crash/core.%e.%p.%t kernel.core_uses_pid = 1 EOF # Применить без перезагрузки sudo sysctl --system # Проверить конкретный параметр sysctl net.ipv4.tcp_congestion_control Hugepages: критично для баз данныхHugePages уменьшают нагрузку на TLB (Translation Lookaside Buffer) при работе с большими объёмами памяти. PostgreSQL, Oracle, MySQL InnoDB, Elasticsearch, Redis — все выигрывают от HugePages. # Проверить текущее состояние cat /proc/meminfo | grep -i huge # HugePages_Total: 0 ← не настроены # Hugepagesize: 2048 kB ← 2 МБ каждая страница # Рассчитать сколько нужно: # Для PostgreSQL: shared_buffers + прочая SHM / 2 МБ # Например: 16 ГБ shared_buffers → 16384 МБ / 2 МБ = 8192 страниц # /etc/sysctl.d/99-hugepages.conf echo "vm.nr_hugepages = 8192" | sudo tee /etc/sysctl.d/99-hugepages.conf # Или прозрачные HugePages (THP) — автоматически, но с latency spikes! # Для БД (особенно Redis) — ОТКЛЮЧИТЬ THP: echo never | sudo tee /sys/kernel/mm/transparent_hugepage/enabled echo never | sudo tee /sys/kernel/mm/transparent_hugepage/defrag # Сделать постоянным через rc.local или systemd service: sudo tee /etc/systemd/system/disable-thp.service > /dev/null <<'EOF' [Unit] Description=Disable Transparent Huge Pages DefaultDependencies=false After=sysinit.target local-fs.target [Service] Type=oneshot ExecStart=/bin/sh -c 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' ExecStart=/bin/sh -c 'echo never > /sys/kernel/mm/transparent_hugepage/defrag' RemainAfterExit=yes [Install] WantedBy=multi-user.target EOF sudo systemctl enable --now disable-thp Планировщик I/O: под задачу# Посмотреть текущий планировщик для диска cat /sys/block/sda/queue/scheduler # [mq-deadline] kyber bfq none # Выбор планировщика: # none (noop) — для NVMe SSD и виртуальных дисков (SSD сами управляют очередью) # mq-deadline — универсальный, хорош для смешанных нагрузок # bfq — для десктопов и интерактивных задач (не для продакшена) # kyber — для NVMe с очень низкой latency # Для NVMe SSD — none: echo none | sudo tee /sys/block/nvme0n1/queue/scheduler # Для SATA SSD — mq-deadline: echo mq-deadline | sudo tee /sys/block/sda/queue/scheduler # Через udev (постоянно): sudo tee /etc/udev/rules.d/60-ioschedulers.rules > /dev/null <<'EOF' # NVMe ACTION=="add|change", KERNEL=="nvme[0-9]*", ATTR{queue/scheduler}="none" # SATA/SAS SSD (по ROTATIONAL=0) ACTION=="add|change", KERNEL=="sd[a-z]|xvd[a-z]", ATTR{queue/rotational}=="0", ATTR{queue/scheduler}="mq-deadline" # HDD (по ROTATIONAL=1) ACTION=="add|change", KERNEL=="sd[a-z]", ATTR{queue/rotational}=="1", ATTR{queue/scheduler}="bfq" EOF # Дополнительные параметры очереди диска: # Глубина очереди запросов (для NVMe можно больше) cat /sys/block/nvme0n1/queue/nr_requests # default 64 echo 1024 | sudo tee /sys/block/nvme0n1/queue/nr_requests # Read-ahead (предварительное чтение) # Для последовательного чтения (логи, backup): увеличить # Для random I/O (OLTP БД): уменьшить blockdev --setra 256 /dev/sda # 128 КБ (256 × 512 байт) OOM Killer: кого убивать в последнюю очередь# OOM killer убивает процессы когда RAM исчерпана. # Значение oom_score_adj: от -1000 (никогда не убивать) до +1000 (убить первым) # Защитить критические процессы (PostgreSQL, основное приложение): echo -1000 | sudo tee /proc/$(pgrep postgres | head -1)/oom_score_adj # В systemd unit — правильный способ: # [Service] # OOMScoreAdjust=-900 # -1000 зарезервирован для ядра # Для throaway-процессов (worker, task runner) — пусть убивают первыми: # OOMScoreAdjust=500 # Включить расширенное логирование OOM kill: echo 1 | sudo tee /proc/sys/vm/oom_dump_tasks # Посмотреть oom_score всех процессов for p in /proc/[0-9]*/; do pid=$(basename $p) comm=$(cat $p/comm 2>/dev/null) score=$(cat $p/oom_score 2>/dev/null) adj=$(cat $p/oom_score_adj 2>/dev/null) [ -n "$score" ] && echo "$score $adj $pid $comm" done | sort -rn | head -20 Часть 4: Файловые системы и хранилищеВыбор файловой системыext4 — проверенный стандарт, но без поддержки checksums данных (только метаданных). XFS — отличная производительность на больших файлах и параллельном I/O. Default в RHEL. Нельзя уменьшить (только увеличить). Btrfs — copy-on-write, встроенные checksums, снапшоты. Хорош для систем где нужны снапшоты без LVM. В продакшене требует RAID-конфигурации для надёжности. ZFS — самая надёжная ФС с end-to-end checksums, встроенным RAID-Z, дедупликацией. Требует отдельной установки на Linux. Рекомендуется для хранилищ данных. # Монтирование ext4 с оптимальными опциями для продакшена: # /etc/fstab: # /dev/sdb1 /data ext4 defaults,noatime,lazytime,errors=remount-ro 0 2 # noatime — не обновлять atime при каждом чтении (значительно снижает I/O) # lazytime — обновлять временны́е метки только при flush (компромисс) # errors=remount-ro — при ошибке ФС переходит в read-only вместо паники # XFS с journalling только на metadata (для производительности): # /dev/sdb1 /data xfs defaults,noatime,logbsize=256k 0 2 # Проверка здоровья файловой системы: sudo tune2fs -l /dev/sdb1 | grep -E "Last checked|Mount count|Max mount count" sudo xfs_info /data sudo xfs_repair -n /data # Проверка XFS без исправления LVM: гибкое управление томамиLVM (Logical Volume Manager) — обязателен для production-серверов. Позволяет расширять разделы без downtime, создавать снапшоты для бэкапов. # Создание LVM структуры: # 1. Physical Volumes (PV) sudo pvcreate /dev/sdb /dev/sdc # 2. Volume Group (VG) sudo vgcreate data_vg /dev/sdb /dev/sdc sudo vgs # Проверка # 3. Logical Volumes (LV) sudo lvcreate -L 100G -n postgres_lv data_vg # 100 ГБ для PostgreSQL sudo lvcreate -L 50G -n logs_lv data_vg # 50 ГБ для логов sudo lvcreate -l 100%FREE -n backup_lv data_vg # Остаток под бэкапы # Форматирование sudo mkfs.xfs /dev/data_vg/postgres_lv sudo mkfs.ext4 /dev/data_vg/logs_lv # Расширение без downtime (XFS умеет расти онлайн): sudo lvextend -L +50G /dev/data_vg/postgres_lv # Добавить 50 ГБ к LV sudo xfs_growfs /var/lib/postgresql # Расширить ФС # Снапшот для онлайн-бэкапа: sudo lvcreate -L 10G -s -n postgres_snap /dev/data_vg/postgres_lv sudo mount -o ro /dev/data_vg/postgres_snap /mnt/backup_snap # rsync с /mnt/backup_snap → бэкап без остановки БД sudo umount /mnt/backup_snap sudo lvremove -f /dev/data_vg/postgres_snap Часть 5: Мониторинг и observabilityВстроенные инструменты диагностики# ── Производительность системы ─────────────────────────────────────────────── # top на стероидах: htop sudo apt install htop # Статистика I/O по процессам sudo iotop -o # -o = только активные процессы # Сетевые соединения (замена netstat) ss -tunap # TCP/UDP, номера, приложения, pid ss -s # Сводная статистика ss 'state established' # Только ESTABLISHED # Дисковый I/O в реальном времени iostat -xz 1 # Расширенная статистика, без нулей, обновление 1с # Нагрузка на сеть по интерфейсам sar -n DEV 1 # Из пакета sysstat # Сколько памяти реально свободно free -h cat /proc/meminfo | grep -E "MemAvailable|MemFree|Cached|SwapUsed" # ── Анализ производительности ──────────────────────────────────────────────── # perf: профилировщик ядра (какие системные вызовы тормозят) sudo perf top -g # Онлайн profiling sudo perf stat -p $(pgrep myapp) sleep 10 # Статистика за 10 секунд # strace: что делает процесс (дорого, только для диагностики) sudo strace -p $(pgrep myapp) -e trace=network,file -T 2>&1 | head -50 # lsof: открытые файлы и сокеты sudo lsof -p $(pgrep myapp) | wc -l # Сколько открыто sudo lsof -i :8080 # Кто слушает порт 8080 # ── Диагностика сети ───────────────────────────────────────────────────────── # Статистика TCP ошибок (ретрансмиты, dropped пакеты) netstat -s | grep -E "retransmit|failed|overflow|listen" # Или через nstat (более детально): nstat -az | grep -i -E "retrans|drop|overflow|fail" # Потери пакетов на интерфейсе ip -s link show eth0 # RX errors/dropped/overrun — проблемы приёма # TX errors/dropped — проблемы передачи # Traceroute с временами (для диагностики latency) mtr --report --report-cycles 20 8.8.8.8 # TCP-дамп для анализа (осторожно с нагрузкой!) sudo tcpdump -i eth0 -n port 5432 -c 1000 -w /tmp/postgres.pcap # Анализ в Wireshark Настройка централизованного логирования# journald — настройка хранения логов sudo tee /etc/systemd/journald.conf.d/99-production.conf > /dev/null <<'EOF' [Journal] Storage=persistent # Хранить на диске (не только в RAM) Compress=yes # Сжатие SystemMaxUse=2G # Максимум 2 ГБ для системных логов SystemKeepFree=500M # Оставлять 500 МБ свободными MaxRetentionSec=30day # Хранить не дольше 30 дней MaxFileSec=1day # Ротация ежедневно ForwardToSyslog=no # Не дублировать в rsyslog (если не нужно) RateLimitBurst=1000 # Лимит: 1000 сообщений RateLimitIntervalSec=30s # за 30 секунд на единицу EOF sudo systemctl restart systemd-journald # Полезные запросы journalctl: journalctl --since "1 hour ago" -p err # Ошибки за последний час journalctl -u myapp -f --output=json # Поток логов в JSON journalctl --disk-usage # Сколько занимают логи journalctl --vacuum-time=7d # Удалить старше 7 дней # rsyslog → файлы (для совместимости с legacy-инструментами): # /etc/rsyslog.d/99-production.conf sudo tee /etc/rsyslog.d/99-production.conf > /dev/null <<'EOF' # Высокопроизводительный режим $ActionQueueType LinkedList $ActionQueueSize 10000 $ActionResumeRetryCount -1 # Бесконечный retry при недоступности цели # Отправка в centralized syslog (Loki, Graylog, Splunk) *.* @@syslog.internal.example.com:514 # @@ = TCP (надёжнее UDP) EOF Prometheus Node Exporter: метрики для Grafana# Установка Node Exporter (собирает 1000+ метрик системы) wget https://github.com/prometheus/node_exporter/releases/latest/download/node_exporter-*.linux-amd64.tar.gz tar xf node_exporter-*.tar.gz sudo mv node_exporter-*/node_exporter /usr/local/bin/ sudo chmod +x /usr/local/bin/node_exporter # systemd unit для Node Exporter sudo tee /etc/systemd/system/node_exporter.service > /dev/null <<'EOF' [Unit] Description=Prometheus Node Exporter After=network.target [Service] Type=simple User=nobody ExecStart=/usr/local/bin/node_exporter \ --collector.systemd \ --collector.processes \ --collector.interrupts \ --collector.tcpstat \ --collector.diskstats \ --web.listen-address=:9100 \ --web.telemetry-path=/metrics Restart=on-failure RestartSec=5s NoNewPrivileges=true PrivateTmp=true [Install] WantedBy=multi-user.target EOF sudo systemctl enable --now node_exporter # Проверка curl -s http://localhost:9100/metrics | head -20 Ключевые метрики для алертов (Prometheus rules): # /etc/prometheus/rules/node-alerts.yml groups: - name: node-alerts rules: - alert: HighCPULoad expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 85 for: 10m labels: severity: warning annotations: summary: "CPU > 85% на {{ $labels.instance }} в течение 10 мин" - alert: LowMemory expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 10 for: 5m labels: severity: critical annotations: summary: "Доступно < 10% RAM на {{ $labels.instance }}" - alert: DiskSpaceCritical expr: node_filesystem_avail_bytes{fstype!~"tmpfs|fuse.lxcfs"} / node_filesystem_size_bytes * 100 < 10 for: 5m labels: severity: critical annotations: summary: "Диск {{ $labels.mountpoint }} заполнен на 90%+" - alert: HighDiskIOUtilization expr: rate(node_disk_io_time_seconds_total[5m]) * 100 > 80 for: 10m labels: severity: warning annotations: summary: "Диск {{ $labels.device }} загружен на 80%+" - alert: HighNetworkErrorRate expr: rate(node_network_receive_errs_total[5m]) + rate(node_network_transmit_errs_total[5m]) > 10 for: 5m labels: severity: warning - alert: SystemdServiceFailed expr: node_systemd_unit_state{state="failed"} == 1 for: 1m labels: severity: critical annotations: summary: "Сервис {{ $labels.name }} в состоянии Failed" Часть 6: Безопасность в продакшенеSSH: только так и никак иначе# /etc/ssh/sshd_config.d/99-hardening.conf sudo tee /etc/ssh/sshd_config.d/99-hardening.conf > /dev/null <<'EOF' # Только ключи, никаких паролей PasswordAuthentication no ChallengeResponseAuthentication no KbdInteractiveAuthentication no PermitEmptyPasswords no # Запрет root-логина PermitRootLogin no # Только конкретные пользователи или группы AllowGroups sshusers sudo # Современные алгоритмы (убираем слабые) KexAlgorithms curve25519-sha256,curve25519-sha256@libssh.org,ecdh-sha2-nistp256 HostKeyAlgorithms ssh-ed25519,rsa-sha2-512,rsa-sha2-256 Ciphers aes256-gcm@openssh.com,aes128-gcm@openssh.com,chacha20-poly1305@openssh.com MACs hmac-sha2-512-etm@openssh.com,hmac-sha2-256-etm@openssh.com # Таймаут неактивной сессии (30 минут) ClientAliveInterval 300 ClientAliveCountMax 6 # Защита от брутфорса: максимум 3 попытки аутентификации MaxAuthTries 3 MaxSessions 10 LoginGraceTime 30s # Отключить X11 forwarding и агент forwarding на серверах X11Forwarding no AllowAgentForwarding no # Логировать все подключения LogLevel VERBOSE EOF sudo sshd -t # Проверка синтаксиса sudo systemctl reload sshd UFW / nftables: файрвол# UFW — простой и читаемый интерфейс к iptables/nftables sudo apt install ufw # Политика по умолчанию: всё запрещено входящее, всё разрешено исходящее sudo ufw default deny incoming sudo ufw default allow outgoing # Разрешаем только нужное sudo ufw allow from 10.0.0.0/8 to any port 22 # SSH только из внутренней сети sudo ufw allow 80/tcp sudo ufw allow 443/tcp sudo ufw allow from 10.0.0.0/8 to any port 9100 # Node Exporter только изнутри # Rate limiting для SSH (защита от брутфорса) sudo ufw limit ssh sudo ufw enable sudo ufw status verbose # Логирование отклонённых пакетов sudo ufw logging on fail2ban: автоматическая блокировка атакsudo apt install fail2ban # /etc/fail2ban/jail.local sudo tee /etc/fail2ban/jail.local > /dev/null <<'EOF' [DEFAULT] bantime = 3600 # Блокировка на 1 час findtime = 600 # Окно анализа: 10 минут maxretry = 5 # Максимум попыток # Уведомление по email destemail = ops@yourcompany.com sender = fail2ban@yourserver.example.com action = %(action_mwl)s # Ban + email с логами # Белый список (никогда не блокировать) ignoreip = 127.0.0.1/8 ::1 10.0.0.0/8 192.168.0.0/16 [sshd] enabled = true port = ssh logpath = %(sshd_log)s maxretry = 3 # SSH: только 3 попытки [nginx-http-auth] enabled = true maxretry = 5 [nginx-limit-req] enabled = true maxretry = 10 [nginx-botsearch] enabled = true maxretry = 2 EOF sudo systemctl enable --now fail2ban sudo fail2ban-client status # Общий статус sudo fail2ban-client status sshd # Статус SSH jail auditd: аудит действий на сервереsudo apt install auditd # /etc/audit/rules.d/99-production.rules sudo tee /etc/audit/rules.d/99-production.rules > /dev/null <<'EOF' # Удаляем все текущие правила -D # Максимальный буфер (для highload) -b 8192 # Отказоустойчивость: при ошибке — продолжать (не паниковать) -f 1 # ── Критические файлы ──────────────────────────────────────────────────────── -w /etc/passwd -p wa -k identity -w /etc/shadow -p wa -k identity -w /etc/sudoers -p wa -k sudo_changes -w /etc/ssh/ -p wa -k ssh_config # Системные бинарники -w /usr/bin/sudo -p x -k privileged -w /usr/bin/su -p x -k privileged -w /bin/chmod -p x -k privileged -w /bin/chown -p x -k privileged # Изменения конфигурации cron -w /etc/cron.d/ -p wa -k cron -w /var/spool/cron/ -p wa -k cron # Загрузка/выгрузка модулей ядра -w /sbin/insmod -p x -k kernel_modules -w /sbin/rmmod -p x -k kernel_modules -a always,exit -F arch=b64 -S init_module -k kernel_modules # Сетевые изменения -a always,exit -F arch=b64 -S sethostname -S setdomainname -k system-locale -w /etc/hosts -p wa -k hosts -w /etc/network/ -p wa -k network # Неудачные системные вызовы (попытки эскалации привилегий) -a always,exit -F arch=b64 -S open -F exit=-EACCES -k access_denied -a always,exit -F arch=b64 -S open -F exit=-EPERM -k access_denied # Мониторинг директории приложения -w /opt/myapp/bin/ -p x -k app_exec EOF sudo augenrules --load # Загрузить правила sudo auditctl -l # Проверить активные правила ausearch -k sudo_changes --start today # Посмотреть события sudo aureport --summary # Сводный отчёт Часть 7: Процедуры и автоматизация обслуживанияСкрипт проверки здоровья сервера#!/bin/bash # /usr/local/bin/health-check.sh — ежедневный health check # Запускать через cron: 0 7 * * * /usr/local/bin/health-check.sh set -euo pipefail REPORT_FILE="/var/log/health-check-$(date +%Y%m%d).log" ALERT_EMAIL="ops@yourcompany.com" ISSUES=0 log() { echo "[$(date '+%H:%M:%S')] $*" | tee -a "$REPORT_FILE"; } warn() { log "⚠️ WARN: $*"; ((ISSUES++)); } err() { log "❌ ERROR: $*"; ((ISSUES++)); } ok() { log "✅ OK: $*"; } log "=== Health Check: $(hostname) === $(date) ===" # ── Свободное место на дисках ──────────────────────────────────────────────── log "--- Дисковое пространство ---" while IFS= read -r line; do usage=$(echo "$line" | awk '{print $5}' | tr -d '%') mount=$(echo "$line" | awk '{print $6}') [ "$usage" -ge 90 ] && err "Диск $mount заполнен на $usage%" && continue [ "$usage" -ge 80 ] && warn "Диск $mount заполнен на $usage%" && continue ok "Диск $mount: $usage%" done < <(df -h --output=pcent,target -x tmpfs -x devtmpfs | tail -n +2) # ── Память ─────────────────────────────────────────────────────────────────── log "--- Память ---" available_mb=$(awk '/MemAvailable/ {printf "%.0f", $2/1024}' /proc/meminfo) total_mb=$(awk '/MemTotal/ {printf "%.0f", $2/1024}' /proc/meminfo) used_pct=$(( (total_mb - available_mb) * 100 / total_mb )) swap_used=$(awk '/SwapTotal/{t=$2} /SwapFree/{f=$2} END{printf "%.0f", (t-f)/1024}' /proc/meminfo) [ "$used_pct" -ge 90 ] && err "RAM: использовано $used_pct%" [ "$used_pct" -ge 80 ] && warn "RAM: использовано $used_pct%" ok "RAM: $used_pct% использовано ($available_mb МБ свободно)" [ "$swap_used" -gt 100 ] && warn "Swap: используется ${swap_used} МБ" # ── Failed сервисы ─────────────────────────────────────────────────────────── log "--- Systemd сервисы ---" failed=$(systemctl list-units --state=failed --no-legend --no-pager | awk '{print $1}') if [ -n "$failed" ]; then for svc in $failed; do err "Сервис в Failed: $svc" done else ok "Все сервисы работают" fi # ── Нагрузка ───────────────────────────────────────────────────────────────── log "--- CPU загрузка ---" cpu_cores=$(nproc) load_avg=$(cut -d' ' -f1 /proc/loadavg) load_int=$(echo "$load_avg" | cut -d. -f1) [ "$load_int" -ge "$((cpu_cores * 2))" ] && err "Load average $load_avg при $cpu_cores ядрах" [ "$load_int" -ge "$cpu_cores" ] && warn "Load average $load_avg при $cpu_cores ядрах" ok "Load average: $load_avg (ядер: $cpu_cores)" # ── SSL-сертификаты ────────────────────────────────────────────────────────── log "--- SSL сертификаты ---" for cert_file in /etc/letsencrypt/live/*/cert.pem /etc/ssl/certs/*.pem; do [ -f "$cert_file" ] || continue expiry=$(openssl x509 -in "$cert_file" -noout -enddate 2>/dev/null \ | cut -d= -f2) expiry_epoch=$(date -d "$expiry" +%s 2>/dev/null || continue) days_left=$(( (expiry_epoch - $(date +%s)) / 86400 )) [ "$days_left" -le 7 ] && err "Сертификат $cert_file истекает через $days_left дней!" [ "$days_left" -le 30 ] && warn "Сертификат $cert_file истекает через $days_left дней" [ "$days_left" -gt 30 ] && ok "Сертификат $cert_file: осталось $days_left дней" done # ── Итог ───────────────────────────────────────────────────────────────────── log "" log "=== Итог: $ISSUES проблем(а) ===" if [ "$ISSUES" -gt 0 ]; then mail -s "⚠️ Health Check FAILED: $(hostname) — $ISSUES проблем" \ "$ALERT_EMAIL" < "$REPORT_FILE" fi exit $((ISSUES > 0 ? 1 : 0)) Автоматизированный бэкап с проверкой целостности#!/bin/bash # /usr/local/bin/backup.sh — ежедневный инкрементальный бэкап set -euo pipefail BACKUP_DIR="/var/backup" REMOTE="backup-user@backup-server.example.com:/backups/$(hostname)" DATE=$(date +%Y%m%d-%H%M) LOG="/var/log/backup.log" RETENTION_DAYS=30 log() { echo "[$(date '+%Y-%m-%d %H:%M:%S')] $*" | tee -a "$LOG"; } log "=== Бэкап начат: $DATE ===" # ── Конфигурация ───────────────────────────────────────────────────────────── rsync -avz --delete \ --exclude='*.tmp' \ --exclude='*.log' \ --exclude='/proc' \ --exclude='/sys' \ --exclude='/dev' \ --exclude='/run' \ --exclude='/tmp' \ --link-dest="$REMOTE/latest" \ / \ "$REMOTE/$DATE/" \ --log-file="$LOG" \ 2>&1 # Обновляем симлинк на последний бэкап ssh backup-user@backup-server.example.com \ "ln -sfn /backups/$(hostname)/$DATE /backups/$(hostname)/latest" # ── Проверка целостности (checksums) ───────────────────────────────────────── log "Генерация checksums..." find /etc /opt/myapp /var/lib -type f -newer /var/backup/.last_backup \ -exec sha256sum {} \; > "/var/backup/checksums-$DATE.txt" 2>/dev/null || true rsync -avz "/var/backup/checksums-$DATE.txt" \ "$REMOTE/checksums/$DATE.txt" touch /var/backup/.last_backup # ── Очистка старых бэкапов ─────────────────────────────────────────────────── log "Очистка бэкапов старше $RETENTION_DAYS дней..." ssh backup-user@backup-server.example.com \ "find /backups/$(hostname) -maxdepth 1 -type d -mtime +$RETENTION_DAYS \ ! -name 'latest' -exec rm -rf {} + 2>/dev/null; echo done" log "=== Бэкап завершён успешно ===" Быстрая шпаргалка: что сделать на каждом новом сервере#!/bin/bash # Минимальный чеклист для нового production-сервера echo "=== 1. Обновить систему ===" apt update && apt upgrade -y # или dnf update -y echo "=== 2. Создать admin-пользователя ===" adduser deploy usermod -aG sudo deploy mkdir -p /home/deploy/.ssh cp ~/.ssh/authorized_keys /home/deploy/.ssh/ chown -R deploy:deploy /home/deploy/.ssh chmod 700 /home/deploy/.ssh chmod 600 /home/deploy/.ssh/authorized_keys echo "=== 3. Настроить SSH ===" sed -i 's/#PasswordAuthentication yes/PasswordAuthentication no/' /etc/ssh/sshd_config sed -i 's/PermitRootLogin yes/PermitRootLogin no/' /etc/ssh/sshd_config systemctl reload sshd echo "=== 4. Файрвол ===" ufw --force enable ufw default deny incoming ufw allow from 10.0.0.0/8 to any port 22 ufw allow 80 443 echo "=== 5. NTP ===" apt install -y chrony systemctl enable --now chrony echo "=== 6. Применить sysctl тюнинг ===" # (скопировать /etc/sysctl.d/99-production.conf из шаблона) sysctl --system echo "=== 7. Node Exporter ===" # (установить и включить — см. раздел выше) echo "=== 8. fail2ban ===" apt install -y fail2ban systemctl enable --now fail2ban echo "=== 9. Unattended upgrades ===" apt install -y unattended-upgrades dpkg-reconfigure -f noninteractive unattended-upgrades echo "=== 10. Базовый мониторинг диска ===" # Добавить в cron: 0 7 * * * /usr/local/bin/health-check.sh echo "✅ Базовая настройка завершена. Не забыть:" echo " - Настроить бэкап" echo " - Подключить к Prometheus/Grafana" echo " - Добавить в систему конфигурационного управления (Ansible/Salt)" echo " - Задокументировать сервер в CMDB" ЗаключениеProduction Linux — это не дистрибутив, это дисциплина. Правильный выбор дистрибутива даёт фундамент. Тюнинг ядра и sysctl — производительность. systemd с правильными политиками — надёжность. Мониторинг — видимость. Безопасность — защиту. А автоматизация обслуживания — предсказуемость. Самые частые провалы в продакшене: Не настроены лимиты (ulimit, systemd LimitNOFILE) — приложение падает при нагрузке Нет мониторинга диска — о заполнении узнают по жалобам пользователей SSH доступен по паролям — вопрос не "взломают ли", а "когда" Не тестируются бэкапы — они есть, но не работают когда нужны Нет процедуры обновления — серверы не обновляются годами Используйте Ansible или Terraform для воспроизводимости: каждая настройка из этой статьи должна быть в коде, а не только в голове у одного администратора. Сервер должен разворачиваться автоматически — это единственная гарантия того, что в 3 часа ночи вы сможете его поднять заново.
Введение: Linux в продакшене — это не просто установить и забытьПоставить Ubuntu, запустить приложение и назвать это "продакшеном" — рецепт будущей катастрофы. Настоящий production Linux — это слоёный пирог из правильного выбора дистрибутива, hardening-а, тюнинга ядра, настроенного мониторинга и чётких процедур обслуживания. Статья написана для тех, кто уже умеет работать с Linux и хочет понять почему нужно делать именно так, а не просто скопировать команды. Часть 1: Выбор дистрибутиваКритерии для production-выбораПрежде чем смотреть на дистрибутивы, определитесь с приоритетами: Стабильность vs свежесть: старые проверенные пакеты или последние версии? Коммерческая поддержка: нужен SLA от вендора или достаточно community? Цикл жизни: как долго дистрибутив будет получать security-патчи? Экосистема: есть ли готовые пакеты для вашего стека? Команда: что знает ваша команда? Переучивание дорого стоит. Ubuntu LTS ServerЦикл поддержки: 5 лет standard, 10 лет ESM (Extended Security Maintenance). Текущий LTS: 24.04 (Noble Numbat), следующий — 26.04. Ubuntu — безусловный лидер по распространённости в cloud-среде. AWS, GCP, Azure — везде Ubuntu является первым выбором по умолчанию. Огромная документация, большинство DevOps-инструментов тестируются на Ubuntu в первую очередь. Подходит для: Startups и компании без выделенного Linux-администратора Kubernetes workers и cloud-native окружения Быстрое развёртывание новых стеков Осторожно: Canonical меняет политики (snap-пакеты вместо deb без предупреждения) Обновления между LTS требуют тщательного тестирования ESM платный для > 5 машин в организации # Проверка версии и EOL даты lsb_release -a ubuntu-advantage status # Статус ESM подписки # Отключить snap если не нужен (спорно, но часто делают) sudo systemctl disable snapd --now sudo apt purge snapd Debian StableЦикл поддержки: ~3 года основная поддержка + 2 года LTS. Текущий: Debian 12 "Bookworm" (до 2028). Debian — "бабушка" большинства дистрибутивов. Её репутация: консервативная, предсказуемая, надёжная. Пакеты в Stable могут быть на 1–2 года старше апстрима, но зато они досконально протестированы. Никаких сюрпризов в 3 часа ночи. Подходит для: Серверы с длинным жизненным циклом (БД, хранилища) Инфраструктура, где стабильность важнее новых фич Встраиваемые и промышленные серверы Осторожно: Старые пакеты могут не поддерживать новые возможности (TLS 1.3 и т.п. уже везде есть, но крайние версии — нет) community-поддержка без коммерческого SLA # Debian: правильные sources.list для продакшена # Только stable, никакого testing/sid! cat /etc/apt/sources.list # deb http://deb.debian.org/debian bookworm main contrib non-free-firmware # deb http://security.debian.org/debian-security bookworm-security main # deb http://deb.debian.org/debian bookworm-updates main # Backports только для конкретных пакетов, не массово # deb http://deb.debian.org/debian bookworm-backports main RHEL / Rocky Linux / AlmaLinuxRHEL (Red Hat Enterprise Linux) — корпоративный стандарт в Enterprise-сегменте, особенно там где есть compliance требования (PCI DSS, HIPAA, FedRAMP). Платная подписка, но включает полный enterprise support от Red Hat. Rocky Linux и AlmaLinux — бинарно-совместимые клоны RHEL, бесплатные. После смерти CentOS 8 (2021) это лучшая замена для тех, кто хочет RHEL-совместимость без платы. Цикл поддержки: RHEL 9 → до 2032 (10 лет!). Rocky/Alma — аналогично. Подходит для: Enterprise-окружения с compliance требованиями Компании с контрактами Red Hat (получают support + Satellite) Там где нужен SELinux из коробки в полном объёме Серверы баз данных Oracle (Oracle Linux — тоже RHEL-клон) # Rocky Linux: подписка на обновления безопасности (бесплатно) sudo dnf install epel-release sudo dnf update # Проверка SELinux статуса getenforce # Enforcing / Permissive / Disabled sestatus # RHEL-специфика: subscription-manager sudo subscription-manager status sudo subscription-manager repos --list-enabled Alpine LinuxЦикл: rolling release (stable branches с ~2 годами поддержки). Alpine — минималистичный дистрибутив: musl libc вместо glibc, busybox вместо GNU coreutils, базовый образ 5 МБ. Создан для контейнеров и встраиваемых систем. Подходит для: Docker-образы (но есть нюансы с musl!) Edge-узлы и шлюзы с ограниченными ресурсами Безопасные "голые" серверы с минимальной поверхностью атаки Осторожно: musl libc != glibc: некоторые Go/C программы ведут себя иначе Не для тех, кто не знает что делает: меньше инструментов отладки Не для продакшена с незнакомым стеком Итоговая таблица выбора Ubuntu LTS Debian Stable Rocky/Alma Alpine Cloud-native ★★★★★ ★★★★ ★★★ ★★★★ Enterprise ★★★ ★★★ ★★★★★ ★★ Стабильность пакетов ★★★★ ★★★★★ ★★★★★ ★★★ Свежесть пакетов ★★★★ ★★★ ★★★ ★★★★★ Безопасность (OOB) ★★★★ ★★★★ ★★★★★ ★★★★ Поддержка сообщества ★★★★★ ★★★★★ ★★★★ ★★★ Простота обслуживания ★★★★★ ★★★★ ★★★ ★★ Рекомендация: для большинства команд без специфических требований — Ubuntu 24.04 LTS или Debian 12. Для enterprise с compliance — Rocky Linux 9. Для контейнеров — Alpine или Distroless. Часть 2: Первичная настройка надёжностиБазовое обновление и автоматические security-патчи# === Ubuntu / Debian === sudo apt update && sudo apt upgrade -y # Автоматические security-обновления (unattended-upgrades) sudo apt install unattended-upgrades apt-listchanges sudo dpkg-reconfigure unattended-upgrades # Конфиг /etc/apt/apt.conf.d/50unattended-upgrades # Оставляем только security, НЕ автоустанавливаем всё подряд sudo tee /etc/apt/apt.conf.d/50unattended-upgrades > /dev/null <<'EOF' Unattended-Upgrade::Allowed-Origins { "${distro_id}:${distro_codename}-security"; "${distro_id}ESMApps:${distro_codename}-apps-security"; "${distro_id}ESM:${distro_codename}-infra-security"; }; Unattended-Upgrade::AutoFixInterruptedDpkg "true"; Unattended-Upgrade::MinimalSteps "true"; Unattended-Upgrade::Remove-Unused-Dependencies "true"; Unattended-Upgrade::Automatic-Reboot "false"; // НЕ перезагружаем автоматически! Unattended-Upgrade::Mail "ops@yourcompany.com"; EOF # === Rocky / AlmaLinux === sudo dnf install dnf-automatic sudo systemctl enable --now dnf-automatic-install.timer # /etc/dnf/automatic.conf: apply_updates = yes, upgrade_type = security Правильная настройка NTPВремя — фундамент для логов, TLS-сертификатов, Kerberos, баз данных. Неправильное время = необъяснимые баги. # Современный стандарт: systemd-timesyncd (простой) или chrony (сложные сети) # chronyd рекомендован для серверов — точнее и поддерживает аппаратные часы sudo apt install chrony # Ubuntu/Debian # или: sudo dnf install chrony # RHEL-based # /etc/chrony.conf sudo tee /etc/chrony.conf > /dev/null <<'EOF' # Используем несколько источников из разных пулов pool 0.ru.pool.ntp.org iburst pool 1.ru.pool.ntp.org iburst pool 2.europe.pool.ntp.org iburst pool 3.pool.ntp.org iburst # Внутренний NTP-сервер (если есть) — даём максимальный приоритет # server 192.168.1.1 prefer iburst # Разрешаем step при большом расхождении (только при старте) makestep 1.0 3 # Дрейф файла driftfile /var/lib/chrony/drift # Логирование logdir /var/log/chrony # Синхронизация RTC (hardware clock) rtcsync EOF sudo systemctl restart chrony chronyc tracking # Статус синхронизации chronyc sources -v # Источники времени systemd: сделать сервисы по-настоящему надёжнымиБольшинство используют systemd только для start/stop/enable. Но в нём есть мощные механизмы для production-надёжности. # /etc/systemd/system/myapp.service — production-grade unit [Unit] Description=My Production Application Documentation=https://docs.mycompany.com/myapp # Зависимости — стартуем ПОСЛЕ того как сеть полностью готова After=network-online.target postgresql.service redis.service Wants=network-online.target Requires=postgresql.service # Условие запуска — только если файл конфига существует ConditionPathExists=/etc/myapp/config.yaml [Service] Type=notify # Приложение сигнализирует о готовности через sd_notify NotifyAccess=main User=myapp Group=myapp WorkingDirectory=/opt/myapp # Переменные окружения из защищённого файла (права 600, владелец root) EnvironmentFile=/etc/myapp/environment ExecStartPre=/opt/myapp/bin/validate-config # Валидация конфига перед стартом ExecStart=/opt/myapp/bin/myapp --config /etc/myapp/config.yaml ExecReload=/bin/kill -HUP $MAINPID # Graceful reload по сигналу HUP # ── Restart политика ────────────────────────────────────────────────────────── Restart=on-failure # Перезапускаем только при сбое (не при systemctl stop) RestartSec=5s # Ждём 5 секунд перед перезапуском StartLimitIntervalSec=120s # Окно для подсчёта неудачных стартов StartLimitBurst=5 # Максимум 5 перезапусков за 120 секунд # После исчерпания — юнит в Failed. Оповестить алертинг! # ── Watchdog ───────────────────────────────────────────────────────────────── # Приложение ДОЛЖНО вызывать sd_notify("WATCHDOG=1") каждые WatchdogSec/2 WatchdogSec=30s # ── Таймауты ───────────────────────────────────────────────────────────────── TimeoutStartSec=60s # Максимальное время на инициализацию TimeoutStopSec=30s # Максимальное время на graceful shutdown KillMode=mixed # Сначала SIGTERM главному процессу, потом SIGKILL всей группе KillSignal=SIGTERM # ── Лимиты ресурсов ────────────────────────────────────────────────────────── LimitNOFILE=65536 # Максимум открытых файлов LimitNPROC=4096 # Максимум процессов/потоков LimitMEMLOCK=infinity # Для приложений с mlock (JVM, некоторые БД) # ── Безопасность (sandboxing) ───────────────────────────────────────────────── NoNewPrivileges=true # Запрет повышения привилегий PrivateTmp=true # Изолированный /tmp PrivateDevices=true # Запрет доступа к /dev (кроме basic) ProtectSystem=strict # /usr, /boot, /etc только на чтение ProtectHome=true # Нет доступа к /home, /root ReadWritePaths=/var/lib/myapp /var/log/myapp # Разрешаем запись только сюда CapabilityBoundingSet=CAP_NET_BIND_SERVICE # Только если нужен порт < 1024 # ── Логирование ────────────────────────────────────────────────────────────── StandardOutput=journal StandardError=journal SyslogIdentifier=myapp [Install] WantedBy=multi-user.target # Анализ конфигурации unit (покажет ошибки и предупреждения) systemd-analyze verify /etc/systemd/system/myapp.service # Просмотр "дерева" зависимостей systemd-analyze critical-chain myapp.service # Лимиты запущенного сервиса cat /proc/$(systemctl show -p MainPID --value myapp)/limits # История перезапусков journalctl -u myapp --since "7 days ago" | grep -E "Started|Stopped|Failed" Настройка ulimits и системных лимитов# /etc/security/limits.conf — лимиты для пользователей # Для высоконагруженного приложения (например, веб-сервер, БД) myapp soft nofile 65536 myapp hard nofile 65536 myapp soft nproc 65536 myapp hard nproc 65536 # Для Elasticsearch / Kafka / других Java-приложений elasticsearch soft memlock unlimited elasticsearch hard memlock unlimited elasticsearch soft nofile 65536 elasticsearch hard nofile 65536 # /etc/systemd/system.conf — глобальные лимиты для systemd-процессов # DefaultLimitNOFILE=65536 # DefaultLimitNPROC=65536 # Проверка текущих лимитов процесса cat /proc/$(pgrep myapp | head -1)/limits Часть 3: Тюнинг ядра для продакшенаПараметры sysctl: сетьЭто самое важное для highload-серверов. По умолчанию Linux оптимизирован для десктопа, не для сервера. # /etc/sysctl.d/99-production.conf sudo tee /etc/sysctl.d/99-production.conf > /dev/null <<'EOF' # ════════════════════════════════════════════════════════════════════ # СЕТЬ — TCP/IP стек # ════════════════════════════════════════════════════════════════════ # Буферы сокетов (receive/send) # Для highload: 128 МБ (default ~212 КБ — катастрофически мало!) net.core.rmem_max = 134217728 # 128 МБ net.core.wmem_max = 134217728 net.core.rmem_default = 31457280 # 30 МБ net.core.wmem_default = 31457280 # TCP-специфичные буферы (min, default, max) net.ipv4.tcp_rmem = 4096 87380 134217728 net.ipv4.tcp_wmem = 4096 65536 134217728 # Очередь подключений (backlog) # Должна совпадать с параметром backlog в listen() вашего приложения net.core.somaxconn = 65535 net.core.netdev_max_backlog = 65535 # SYN-очередь (защита от SYN flood + highload accept) net.ipv4.tcp_max_syn_backlog = 65535 # TIME_WAIT: ускоряем переиспользование сокетов net.ipv4.tcp_tw_reuse = 1 # Переиспользовать TIME_WAIT сокеты (безопасно) net.ipv4.tcp_fin_timeout = 15 # Сократить FIN_WAIT таймаут (default 60 сек) # Диапазон эфемерных портов (для outbound соединений) net.ipv4.ip_local_port_range = 1024 65535 # Keepalive — обнаружение мёртвых соединений net.ipv4.tcp_keepalive_time = 120 # Начинаем проверку после 120 сек простоя net.ipv4.tcp_keepalive_intvl = 10 # Интервал между пробами net.ipv4.tcp_keepalive_probes = 6 # Количество проб # Алгоритм управления перегрузкой (congestion control) # BBR — современный алгоритм Google, значительно лучше для WAN и highload net.core.default_qdisc = fq net.ipv4.tcp_congestion_control = bbr # Быстрый открытый TCP (TFO) — уменьшает latency на 1 RTT # (убедитесь что клиенты поддерживают) net.ipv4.tcp_fastopen = 3 # 1=клиент, 2=сервер, 3=оба # Защита от мусорных RST пакетов net.ipv4.tcp_rfc1337 = 1 # ════════════════════════════════════════════════════════════════════ # ПАМЯТЬ # ════════════════════════════════════════════════════════════════════ # vm.swappiness: насколько агрессивно использовать swap # 0 = swap только при крайней необходимости (для БД и latency-критичных) # 10 = рекомендуется для production-серверов # 60 = default (слишком агрессивный для сервера) vm.swappiness = 10 # Dirty pages: когда сбрасывать на диск # Уменьшаем для предсказуемой latency (не даём накопиться большому flush) vm.dirty_ratio = 10 # Начинаем sync при 10% RAM dirty (default 20%) vm.dirty_background_ratio = 3 # Фоновый flush начинается при 3% (default 10%) vm.dirty_writeback_centisecs = 500 # Интервал фонового flush (5 сек, default 5 сек) vm.dirty_expire_centisecs = 3000 # Страницы считаются "старыми" через 30 сек # Overcommit (для Java/JVM и других приложений с большими heap) # 0 = эвристика ядра (default) # 1 = всегда overcommit (опасно, но нужно для некоторых БД) # 2 = строгий лимит (CommitLimit = swap + vm.overcommit_ratio% от RAM) vm.overcommit_memory = 0 # OOM Killer: штраф для критических процессов # Устанавливается через /proc или systemd OOMPolicy # (ниже — пример для PostgreSQL) # ════════════════════════════════════════════════════════════════════ # ФАЙЛОВАЯ СИСТЕМА # ════════════════════════════════════════════════════════════════════ # Максимум открытых файлов в системе (не путать с per-process ulimit) fs.file-max = 2097152 # Inotify: для приложений, следящих за файлами (Docker, K8s, IDE) fs.inotify.max_user_watches = 524288 fs.inotify.max_user_instances = 512 # AIO: асинхронный ввод-вывод (PostgreSQL, некоторые БД) fs.aio-max-nr = 1048576 # ════════════════════════════════════════════════════════════════════ # БЕЗОПАСНОСТЬ # ════════════════════════════════════════════════════════════════════ # Запрет разыменования символических ссылок в /tmp (защита от атак) fs.protected_symlinks = 1 fs.protected_hardlinks = 1 # Запрет записи в память выполняемых файлов fs.protected_regular = 2 fs.protected_fifos = 2 # ASLR (Address Space Layout Randomization) kernel.randomize_va_space = 2 # Полная рандомизация # Запрет SysRq (кроме sync/reboot — оставляем для экстренного случая) kernel.sysrq = 16 # 16 = только sync # Защита от Spectre/Meltdown через ptrace kernel.yama.ptrace_scope = 1 # Core dumps только в определённую директорию kernel.core_pattern = /var/crash/core.%e.%p.%t kernel.core_uses_pid = 1 EOF # Применить без перезагрузки sudo sysctl --system # Проверить конкретный параметр sysctl net.ipv4.tcp_congestion_control Hugepages: критично для баз данныхHugePages уменьшают нагрузку на TLB (Translation Lookaside Buffer) при работе с большими объёмами памяти. PostgreSQL, Oracle, MySQL InnoDB, Elasticsearch, Redis — все выигрывают от HugePages. # Проверить текущее состояние cat /proc/meminfo | grep -i huge # HugePages_Total: 0 ← не настроены # Hugepagesize: 2048 kB ← 2 МБ каждая страница # Рассчитать сколько нужно: # Для PostgreSQL: shared_buffers + прочая SHM / 2 МБ # Например: 16 ГБ shared_buffers → 16384 МБ / 2 МБ = 8192 страниц # /etc/sysctl.d/99-hugepages.conf echo "vm.nr_hugepages = 8192" | sudo tee /etc/sysctl.d/99-hugepages.conf # Или прозрачные HugePages (THP) — автоматически, но с latency spikes! # Для БД (особенно Redis) — ОТКЛЮЧИТЬ THP: echo never | sudo tee /sys/kernel/mm/transparent_hugepage/enabled echo never | sudo tee /sys/kernel/mm/transparent_hugepage/defrag # Сделать постоянным через rc.local или systemd service: sudo tee /etc/systemd/system/disable-thp.service > /dev/null <<'EOF' [Unit] Description=Disable Transparent Huge Pages DefaultDependencies=false After=sysinit.target local-fs.target [Service] Type=oneshot ExecStart=/bin/sh -c 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' ExecStart=/bin/sh -c 'echo never > /sys/kernel/mm/transparent_hugepage/defrag' RemainAfterExit=yes [Install] WantedBy=multi-user.target EOF sudo systemctl enable --now disable-thp Планировщик I/O: под задачу# Посмотреть текущий планировщик для диска cat /sys/block/sda/queue/scheduler # [mq-deadline] kyber bfq none # Выбор планировщика: # none (noop) — для NVMe SSD и виртуальных дисков (SSD сами управляют очередью) # mq-deadline — универсальный, хорош для смешанных нагрузок # bfq — для десктопов и интерактивных задач (не для продакшена) # kyber — для NVMe с очень низкой latency # Для NVMe SSD — none: echo none | sudo tee /sys/block/nvme0n1/queue/scheduler # Для SATA SSD — mq-deadline: echo mq-deadline | sudo tee /sys/block/sda/queue/scheduler # Через udev (постоянно): sudo tee /etc/udev/rules.d/60-ioschedulers.rules > /dev/null <<'EOF' # NVMe ACTION=="add|change", KERNEL=="nvme[0-9]*", ATTR{queue/scheduler}="none" # SATA/SAS SSD (по ROTATIONAL=0) ACTION=="add|change", KERNEL=="sd[a-z]|xvd[a-z]", ATTR{queue/rotational}=="0", ATTR{queue/scheduler}="mq-deadline" # HDD (по ROTATIONAL=1) ACTION=="add|change", KERNEL=="sd[a-z]", ATTR{queue/rotational}=="1", ATTR{queue/scheduler}="bfq" EOF # Дополнительные параметры очереди диска: # Глубина очереди запросов (для NVMe можно больше) cat /sys/block/nvme0n1/queue/nr_requests # default 64 echo 1024 | sudo tee /sys/block/nvme0n1/queue/nr_requests # Read-ahead (предварительное чтение) # Для последовательного чтения (логи, backup): увеличить # Для random I/O (OLTP БД): уменьшить blockdev --setra 256 /dev/sda # 128 КБ (256 × 512 байт) OOM Killer: кого убивать в последнюю очередь# OOM killer убивает процессы когда RAM исчерпана. # Значение oom_score_adj: от -1000 (никогда не убивать) до +1000 (убить первым) # Защитить критические процессы (PostgreSQL, основное приложение): echo -1000 | sudo tee /proc/$(pgrep postgres | head -1)/oom_score_adj # В systemd unit — правильный способ: # [Service] # OOMScoreAdjust=-900 # -1000 зарезервирован для ядра # Для throaway-процессов (worker, task runner) — пусть убивают первыми: # OOMScoreAdjust=500 # Включить расширенное логирование OOM kill: echo 1 | sudo tee /proc/sys/vm/oom_dump_tasks # Посмотреть oom_score всех процессов for p in /proc/[0-9]*/; do pid=$(basename $p) comm=$(cat $p/comm 2>/dev/null) score=$(cat $p/oom_score 2>/dev/null) adj=$(cat $p/oom_score_adj 2>/dev/null) [ -n "$score" ] && echo "$score $adj $pid $comm" done | sort -rn | head -20 Часть 4: Файловые системы и хранилищеВыбор файловой системыext4 — проверенный стандарт, но без поддержки checksums данных (только метаданных). XFS — отличная производительность на больших файлах и параллельном I/O. Default в RHEL. Нельзя уменьшить (только увеличить). Btrfs — copy-on-write, встроенные checksums, снапшоты. Хорош для систем где нужны снапшоты без LVM. В продакшене требует RAID-конфигурации для надёжности. ZFS — самая надёжная ФС с end-to-end checksums, встроенным RAID-Z, дедупликацией. Требует отдельной установки на Linux. Рекомендуется для хранилищ данных. # Монтирование ext4 с оптимальными опциями для продакшена: # /etc/fstab: # /dev/sdb1 /data ext4 defaults,noatime,lazytime,errors=remount-ro 0 2 # noatime — не обновлять atime при каждом чтении (значительно снижает I/O) # lazytime — обновлять временны́е метки только при flush (компромисс) # errors=remount-ro — при ошибке ФС переходит в read-only вместо паники # XFS с journalling только на metadata (для производительности): # /dev/sdb1 /data xfs defaults,noatime,logbsize=256k 0 2 # Проверка здоровья файловой системы: sudo tune2fs -l /dev/sdb1 | grep -E "Last checked|Mount count|Max mount count" sudo xfs_info /data sudo xfs_repair -n /data # Проверка XFS без исправления LVM: гибкое управление томамиLVM (Logical Volume Manager) — обязателен для production-серверов. Позволяет расширять разделы без downtime, создавать снапшоты для бэкапов. # Создание LVM структуры: # 1. Physical Volumes (PV) sudo pvcreate /dev/sdb /dev/sdc # 2. Volume Group (VG) sudo vgcreate data_vg /dev/sdb /dev/sdc sudo vgs # Проверка # 3. Logical Volumes (LV) sudo lvcreate -L 100G -n postgres_lv data_vg # 100 ГБ для PostgreSQL sudo lvcreate -L 50G -n logs_lv data_vg # 50 ГБ для логов sudo lvcreate -l 100%FREE -n backup_lv data_vg # Остаток под бэкапы # Форматирование sudo mkfs.xfs /dev/data_vg/postgres_lv sudo mkfs.ext4 /dev/data_vg/logs_lv # Расширение без downtime (XFS умеет расти онлайн): sudo lvextend -L +50G /dev/data_vg/postgres_lv # Добавить 50 ГБ к LV sudo xfs_growfs /var/lib/postgresql # Расширить ФС # Снапшот для онлайн-бэкапа: sudo lvcreate -L 10G -s -n postgres_snap /dev/data_vg/postgres_lv sudo mount -o ro /dev/data_vg/postgres_snap /mnt/backup_snap # rsync с /mnt/backup_snap → бэкап без остановки БД sudo umount /mnt/backup_snap sudo lvremove -f /dev/data_vg/postgres_snap Часть 5: Мониторинг и observabilityВстроенные инструменты диагностики# ── Производительность системы ─────────────────────────────────────────────── # top на стероидах: htop sudo apt install htop # Статистика I/O по процессам sudo iotop -o # -o = только активные процессы # Сетевые соединения (замена netstat) ss -tunap # TCP/UDP, номера, приложения, pid ss -s # Сводная статистика ss 'state established' # Только ESTABLISHED # Дисковый I/O в реальном времени iostat -xz 1 # Расширенная статистика, без нулей, обновление 1с # Нагрузка на сеть по интерфейсам sar -n DEV 1 # Из пакета sysstat # Сколько памяти реально свободно free -h cat /proc/meminfo | grep -E "MemAvailable|MemFree|Cached|SwapUsed" # ── Анализ производительности ──────────────────────────────────────────────── # perf: профилировщик ядра (какие системные вызовы тормозят) sudo perf top -g # Онлайн profiling sudo perf stat -p $(pgrep myapp) sleep 10 # Статистика за 10 секунд # strace: что делает процесс (дорого, только для диагностики) sudo strace -p $(pgrep myapp) -e trace=network,file -T 2>&1 | head -50 # lsof: открытые файлы и сокеты sudo lsof -p $(pgrep myapp) | wc -l # Сколько открыто sudo lsof -i :8080 # Кто слушает порт 8080 # ── Диагностика сети ───────────────────────────────────────────────────────── # Статистика TCP ошибок (ретрансмиты, dropped пакеты) netstat -s | grep -E "retransmit|failed|overflow|listen" # Или через nstat (более детально): nstat -az | grep -i -E "retrans|drop|overflow|fail" # Потери пакетов на интерфейсе ip -s link show eth0 # RX errors/dropped/overrun — проблемы приёма # TX errors/dropped — проблемы передачи # Traceroute с временами (для диагностики latency) mtr --report --report-cycles 20 8.8.8.8 # TCP-дамп для анализа (осторожно с нагрузкой!) sudo tcpdump -i eth0 -n port 5432 -c 1000 -w /tmp/postgres.pcap # Анализ в Wireshark Настройка централизованного логирования# journald — настройка хранения логов sudo tee /etc/systemd/journald.conf.d/99-production.conf > /dev/null <<'EOF' [Journal] Storage=persistent # Хранить на диске (не только в RAM) Compress=yes # Сжатие SystemMaxUse=2G # Максимум 2 ГБ для системных логов SystemKeepFree=500M # Оставлять 500 МБ свободными MaxRetentionSec=30day # Хранить не дольше 30 дней MaxFileSec=1day # Ротация ежедневно ForwardToSyslog=no # Не дублировать в rsyslog (если не нужно) RateLimitBurst=1000 # Лимит: 1000 сообщений RateLimitIntervalSec=30s # за 30 секунд на единицу EOF sudo systemctl restart systemd-journald # Полезные запросы journalctl: journalctl --since "1 hour ago" -p err # Ошибки за последний час journalctl -u myapp -f --output=json # Поток логов в JSON journalctl --disk-usage # Сколько занимают логи journalctl --vacuum-time=7d # Удалить старше 7 дней # rsyslog → файлы (для совместимости с legacy-инструментами): # /etc/rsyslog.d/99-production.conf sudo tee /etc/rsyslog.d/99-production.conf > /dev/null <<'EOF' # Высокопроизводительный режим $ActionQueueType LinkedList $ActionQueueSize 10000 $ActionResumeRetryCount -1 # Бесконечный retry при недоступности цели # Отправка в centralized syslog (Loki, Graylog, Splunk) *.* @@syslog.internal.example.com:514 # @@ = TCP (надёжнее UDP) EOF Prometheus Node Exporter: метрики для Grafana# Установка Node Exporter (собирает 1000+ метрик системы) wget https://github.com/prometheus/node_exporter/releases/latest/download/node_exporter-*.linux-amd64.tar.gz tar xf node_exporter-*.tar.gz sudo mv node_exporter-*/node_exporter /usr/local/bin/ sudo chmod +x /usr/local/bin/node_exporter # systemd unit для Node Exporter sudo tee /etc/systemd/system/node_exporter.service > /dev/null <<'EOF' [Unit] Description=Prometheus Node Exporter After=network.target [Service] Type=simple User=nobody ExecStart=/usr/local/bin/node_exporter \ --collector.systemd \ --collector.processes \ --collector.interrupts \ --collector.tcpstat \ --collector.diskstats \ --web.listen-address=:9100 \ --web.telemetry-path=/metrics Restart=on-failure RestartSec=5s NoNewPrivileges=true PrivateTmp=true [Install] WantedBy=multi-user.target EOF sudo systemctl enable --now node_exporter # Проверка curl -s http://localhost:9100/metrics | head -20 Ключевые метрики для алертов (Prometheus rules): # /etc/prometheus/rules/node-alerts.yml groups: - name: node-alerts rules: - alert: HighCPULoad expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 85 for: 10m labels: severity: warning annotations: summary: "CPU > 85% на {{ $labels.instance }} в течение 10 мин" - alert: LowMemory expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 10 for: 5m labels: severity: critical annotations: summary: "Доступно < 10% RAM на {{ $labels.instance }}" - alert: DiskSpaceCritical expr: node_filesystem_avail_bytes{fstype!~"tmpfs|fuse.lxcfs"} / node_filesystem_size_bytes * 100 < 10 for: 5m labels: severity: critical annotations: summary: "Диск {{ $labels.mountpoint }} заполнен на 90%+" - alert: HighDiskIOUtilization expr: rate(node_disk_io_time_seconds_total[5m]) * 100 > 80 for: 10m labels: severity: warning annotations: summary: "Диск {{ $labels.device }} загружен на 80%+" - alert: HighNetworkErrorRate expr: rate(node_network_receive_errs_total[5m]) + rate(node_network_transmit_errs_total[5m]) > 10 for: 5m labels: severity: warning - alert: SystemdServiceFailed expr: node_systemd_unit_state{state="failed"} == 1 for: 1m labels: severity: critical annotations: summary: "Сервис {{ $labels.name }} в состоянии Failed" Часть 6: Безопасность в продакшенеSSH: только так и никак иначе# /etc/ssh/sshd_config.d/99-hardening.conf sudo tee /etc/ssh/sshd_config.d/99-hardening.conf > /dev/null <<'EOF' # Только ключи, никаких паролей PasswordAuthentication no ChallengeResponseAuthentication no KbdInteractiveAuthentication no PermitEmptyPasswords no # Запрет root-логина PermitRootLogin no # Только конкретные пользователи или группы AllowGroups sshusers sudo # Современные алгоритмы (убираем слабые) KexAlgorithms curve25519-sha256,curve25519-sha256@libssh.org,ecdh-sha2-nistp256 HostKeyAlgorithms ssh-ed25519,rsa-sha2-512,rsa-sha2-256 Ciphers aes256-gcm@openssh.com,aes128-gcm@openssh.com,chacha20-poly1305@openssh.com MACs hmac-sha2-512-etm@openssh.com,hmac-sha2-256-etm@openssh.com # Таймаут неактивной сессии (30 минут) ClientAliveInterval 300 ClientAliveCountMax 6 # Защита от брутфорса: максимум 3 попытки аутентификации MaxAuthTries 3 MaxSessions 10 LoginGraceTime 30s # Отключить X11 forwarding и агент forwarding на серверах X11Forwarding no AllowAgentForwarding no # Логировать все подключения LogLevel VERBOSE EOF sudo sshd -t # Проверка синтаксиса sudo systemctl reload sshd UFW / nftables: файрвол# UFW — простой и читаемый интерфейс к iptables/nftables sudo apt install ufw # Политика по умолчанию: всё запрещено входящее, всё разрешено исходящее sudo ufw default deny incoming sudo ufw default allow outgoing # Разрешаем только нужное sudo ufw allow from 10.0.0.0/8 to any port 22 # SSH только из внутренней сети sudo ufw allow 80/tcp sudo ufw allow 443/tcp sudo ufw allow from 10.0.0.0/8 to any port 9100 # Node Exporter только изнутри # Rate limiting для SSH (защита от брутфорса) sudo ufw limit ssh sudo ufw enable sudo ufw status verbose # Логирование отклонённых пакетов sudo ufw logging on fail2ban: автоматическая блокировка атакsudo apt install fail2ban # /etc/fail2ban/jail.local sudo tee /etc/fail2ban/jail.local > /dev/null <<'EOF' [DEFAULT] bantime = 3600 # Блокировка на 1 час findtime = 600 # Окно анализа: 10 минут maxretry = 5 # Максимум попыток # Уведомление по email destemail = ops@yourcompany.com sender = fail2ban@yourserver.example.com action = %(action_mwl)s # Ban + email с логами # Белый список (никогда не блокировать) ignoreip = 127.0.0.1/8 ::1 10.0.0.0/8 192.168.0.0/16 [sshd] enabled = true port = ssh logpath = %(sshd_log)s maxretry = 3 # SSH: только 3 попытки [nginx-http-auth] enabled = true maxretry = 5 [nginx-limit-req] enabled = true maxretry = 10 [nginx-botsearch] enabled = true maxretry = 2 EOF sudo systemctl enable --now fail2ban sudo fail2ban-client status # Общий статус sudo fail2ban-client status sshd # Статус SSH jail auditd: аудит действий на сервереsudo apt install auditd # /etc/audit/rules.d/99-production.rules sudo tee /etc/audit/rules.d/99-production.rules > /dev/null <<'EOF' # Удаляем все текущие правила -D # Максимальный буфер (для highload) -b 8192 # Отказоустойчивость: при ошибке — продолжать (не паниковать) -f 1 # ── Критические файлы ──────────────────────────────────────────────────────── -w /etc/passwd -p wa -k identity -w /etc/shadow -p wa -k identity -w /etc/sudoers -p wa -k sudo_changes -w /etc/ssh/ -p wa -k ssh_config # Системные бинарники -w /usr/bin/sudo -p x -k privileged -w /usr/bin/su -p x -k privileged -w /bin/chmod -p x -k privileged -w /bin/chown -p x -k privileged # Изменения конфигурации cron -w /etc/cron.d/ -p wa -k cron -w /var/spool/cron/ -p wa -k cron # Загрузка/выгрузка модулей ядра -w /sbin/insmod -p x -k kernel_modules -w /sbin/rmmod -p x -k kernel_modules -a always,exit -F arch=b64 -S init_module -k kernel_modules # Сетевые изменения -a always,exit -F arch=b64 -S sethostname -S setdomainname -k system-locale -w /etc/hosts -p wa -k hosts -w /etc/network/ -p wa -k network # Неудачные системные вызовы (попытки эскалации привилегий) -a always,exit -F arch=b64 -S open -F exit=-EACCES -k access_denied -a always,exit -F arch=b64 -S open -F exit=-EPERM -k access_denied # Мониторинг директории приложения -w /opt/myapp/bin/ -p x -k app_exec EOF sudo augenrules --load # Загрузить правила sudo auditctl -l # Проверить активные правила ausearch -k sudo_changes --start today # Посмотреть события sudo aureport --summary # Сводный отчёт Часть 7: Процедуры и автоматизация обслуживанияСкрипт проверки здоровья сервера#!/bin/bash # /usr/local/bin/health-check.sh — ежедневный health check # Запускать через cron: 0 7 * * * /usr/local/bin/health-check.sh set -euo pipefail REPORT_FILE="/var/log/health-check-$(date +%Y%m%d).log" ALERT_EMAIL="ops@yourcompany.com" ISSUES=0 log() { echo "[$(date '+%H:%M:%S')] $*" | tee -a "$REPORT_FILE"; } warn() { log "⚠️ WARN: $*"; ((ISSUES++)); } err() { log "❌ ERROR: $*"; ((ISSUES++)); } ok() { log "✅ OK: $*"; } log "=== Health Check: $(hostname) === $(date) ===" # ── Свободное место на дисках ──────────────────────────────────────────────── log "--- Дисковое пространство ---" while IFS= read -r line; do usage=$(echo "$line" | awk '{print $5}' | tr -d '%') mount=$(echo "$line" | awk '{print $6}') [ "$usage" -ge 90 ] && err "Диск $mount заполнен на $usage%" && continue [ "$usage" -ge 80 ] && warn "Диск $mount заполнен на $usage%" && continue ok "Диск $mount: $usage%" done < <(df -h --output=pcent,target -x tmpfs -x devtmpfs | tail -n +2) # ── Память ─────────────────────────────────────────────────────────────────── log "--- Память ---" available_mb=$(awk '/MemAvailable/ {printf "%.0f", $2/1024}' /proc/meminfo) total_mb=$(awk '/MemTotal/ {printf "%.0f", $2/1024}' /proc/meminfo) used_pct=$(( (total_mb - available_mb) * 100 / total_mb )) swap_used=$(awk '/SwapTotal/{t=$2} /SwapFree/{f=$2} END{printf "%.0f", (t-f)/1024}' /proc/meminfo) [ "$used_pct" -ge 90 ] && err "RAM: использовано $used_pct%" [ "$used_pct" -ge 80 ] && warn "RAM: использовано $used_pct%" ok "RAM: $used_pct% использовано ($available_mb МБ свободно)" [ "$swap_used" -gt 100 ] && warn "Swap: используется ${swap_used} МБ" # ── Failed сервисы ─────────────────────────────────────────────────────────── log "--- Systemd сервисы ---" failed=$(systemctl list-units --state=failed --no-legend --no-pager | awk '{print $1}') if [ -n "$failed" ]; then for svc in $failed; do err "Сервис в Failed: $svc" done else ok "Все сервисы работают" fi # ── Нагрузка ───────────────────────────────────────────────────────────────── log "--- CPU загрузка ---" cpu_cores=$(nproc) load_avg=$(cut -d' ' -f1 /proc/loadavg) load_int=$(echo "$load_avg" | cut -d. -f1) [ "$load_int" -ge "$((cpu_cores * 2))" ] && err "Load average $load_avg при $cpu_cores ядрах" [ "$load_int" -ge "$cpu_cores" ] && warn "Load average $load_avg при $cpu_cores ядрах" ok "Load average: $load_avg (ядер: $cpu_cores)" # ── SSL-сертификаты ────────────────────────────────────────────────────────── log "--- SSL сертификаты ---" for cert_file in /etc/letsencrypt/live/*/cert.pem /etc/ssl/certs/*.pem; do [ -f "$cert_file" ] || continue expiry=$(openssl x509 -in "$cert_file" -noout -enddate 2>/dev/null \ | cut -d= -f2) expiry_epoch=$(date -d "$expiry" +%s 2>/dev/null || continue) days_left=$(( (expiry_epoch - $(date +%s)) / 86400 )) [ "$days_left" -le 7 ] && err "Сертификат $cert_file истекает через $days_left дней!" [ "$days_left" -le 30 ] && warn "Сертификат $cert_file истекает через $days_left дней" [ "$days_left" -gt 30 ] && ok "Сертификат $cert_file: осталось $days_left дней" done # ── Итог ───────────────────────────────────────────────────────────────────── log "" log "=== Итог: $ISSUES проблем(а) ===" if [ "$ISSUES" -gt 0 ]; then mail -s "⚠️ Health Check FAILED: $(hostname) — $ISSUES проблем" \ "$ALERT_EMAIL" < "$REPORT_FILE" fi exit $((ISSUES > 0 ? 1 : 0)) Автоматизированный бэкап с проверкой целостности#!/bin/bash # /usr/local/bin/backup.sh — ежедневный инкрементальный бэкап set -euo pipefail BACKUP_DIR="/var/backup" REMOTE="backup-user@backup-server.example.com:/backups/$(hostname)" DATE=$(date +%Y%m%d-%H%M) LOG="/var/log/backup.log" RETENTION_DAYS=30 log() { echo "[$(date '+%Y-%m-%d %H:%M:%S')] $*" | tee -a "$LOG"; } log "=== Бэкап начат: $DATE ===" # ── Конфигурация ───────────────────────────────────────────────────────────── rsync -avz --delete \ --exclude='*.tmp' \ --exclude='*.log' \ --exclude='/proc' \ --exclude='/sys' \ --exclude='/dev' \ --exclude='/run' \ --exclude='/tmp' \ --link-dest="$REMOTE/latest" \ / \ "$REMOTE/$DATE/" \ --log-file="$LOG" \ 2>&1 # Обновляем симлинк на последний бэкап ssh backup-user@backup-server.example.com \ "ln -sfn /backups/$(hostname)/$DATE /backups/$(hostname)/latest" # ── Проверка целостности (checksums) ───────────────────────────────────────── log "Генерация checksums..." find /etc /opt/myapp /var/lib -type f -newer /var/backup/.last_backup \ -exec sha256sum {} \; > "/var/backup/checksums-$DATE.txt" 2>/dev/null || true rsync -avz "/var/backup/checksums-$DATE.txt" \ "$REMOTE/checksums/$DATE.txt" touch /var/backup/.last_backup # ── Очистка старых бэкапов ─────────────────────────────────────────────────── log "Очистка бэкапов старше $RETENTION_DAYS дней..." ssh backup-user@backup-server.example.com \ "find /backups/$(hostname) -maxdepth 1 -type d -mtime +$RETENTION_DAYS \ ! -name 'latest' -exec rm -rf {} + 2>/dev/null; echo done" log "=== Бэкап завершён успешно ===" Быстрая шпаргалка: что сделать на каждом новом сервере#!/bin/bash # Минимальный чеклист для нового production-сервера echo "=== 1. Обновить систему ===" apt update && apt upgrade -y # или dnf update -y echo "=== 2. Создать admin-пользователя ===" adduser deploy usermod -aG sudo deploy mkdir -p /home/deploy/.ssh cp ~/.ssh/authorized_keys /home/deploy/.ssh/ chown -R deploy:deploy /home/deploy/.ssh chmod 700 /home/deploy/.ssh chmod 600 /home/deploy/.ssh/authorized_keys echo "=== 3. Настроить SSH ===" sed -i 's/#PasswordAuthentication yes/PasswordAuthentication no/' /etc/ssh/sshd_config sed -i 's/PermitRootLogin yes/PermitRootLogin no/' /etc/ssh/sshd_config systemctl reload sshd echo "=== 4. Файрвол ===" ufw --force enable ufw default deny incoming ufw allow from 10.0.0.0/8 to any port 22 ufw allow 80 443 echo "=== 5. NTP ===" apt install -y chrony systemctl enable --now chrony echo "=== 6. Применить sysctl тюнинг ===" # (скопировать /etc/sysctl.d/99-production.conf из шаблона) sysctl --system echo "=== 7. Node Exporter ===" # (установить и включить — см. раздел выше) echo "=== 8. fail2ban ===" apt install -y fail2ban systemctl enable --now fail2ban echo "=== 9. Unattended upgrades ===" apt install -y unattended-upgrades dpkg-reconfigure -f noninteractive unattended-upgrades echo "=== 10. Базовый мониторинг диска ===" # Добавить в cron: 0 7 * * * /usr/local/bin/health-check.sh echo "✅ Базовая настройка завершена. Не забыть:" echo " - Настроить бэкап" echo " - Подключить к Prometheus/Grafana" echo " - Добавить в систему конфигурационного управления (Ansible/Salt)" echo " - Задокументировать сервер в CMDB" ЗаключениеProduction Linux — это не дистрибутив, это дисциплина. Правильный выбор дистрибутива даёт фундамент. Тюнинг ядра и sysctl — производительность. systemd с правильными политиками — надёжность. Мониторинг — видимость. Безопасность — защиту. А автоматизация обслуживания — предсказуемость. Самые частые провалы в продакшене: Не настроены лимиты (ulimit, systemd LimitNOFILE) — приложение падает при нагрузке Нет мониторинга диска — о заполнении узнают по жалобам пользователей SSH доступен по паролям — вопрос не "взломают ли", а "когда" Не тестируются бэкапы — они есть, но не работают когда нужны Нет процедуры обновления — серверы не обновляются годами Используйте Ansible или Terraform для воспроизводимости: каждая настройка из этой статьи должна быть в коде, а не только в голове у одного администратора. Сервер должен разворачиваться автоматически — это единственная гарантия того, что в 3 часа ночи вы сможете его поднять заново. -
 С чего начинается тюнингNginx в дефолтной конфигурации — это как спортивный автомобиль с заводскими настройками для езды по бездорожью: едет, но не так быстро, как мог бы. Хорошая новость: большинство важных оптимизаций достигается правкой конфига, а не покупкой более мощного железа. Плохая новость: многие "гайды по тюнингу" в интернете — копипаста десятилетней давности, без понимания что и зачем. Параметры для Nginx 1.8 на 2-ядерном сервере копируют на 32-ядерный продакшен под highload — и удивляются что не помогает или становится хуже. Этот материал — о том, как думать о тюнинге Nginx: что делает каждый параметр, какие компромиссы он несёт, и как проверить что оптимизация действительно работает. Версии в статье: Nginx 1.24+ / 1.25+ (mainline). Большинство конфигов работают с 1.18+. Диагностика перед тюнингом: что измерятьТюнинг без метрик — гадание на кофейной гуще. Сначала измеряем, потом меняем, потом снова измеряем. Текущее состояние Nginx# Версия и скомпилированные модули nginx -V 2>&1 | tr ' ' '\n' | grep -E 'version|with-|without-' # Активная конфигурация (проверка синтаксиса) nginx -t # Рабочие процессы и их нагрузка ps aux | grep nginx top -p $(pgrep -d',' nginx) # Открытые соединения ss -s ss -tnp | grep nginx | wc -l # Статус (если включён stub_status) curl -s http://127.0.0.1/nginx_status # Active connections: 847 # server accepts handled requests # 12340582 12340582 28473910 # Reading: 12 Writing: 84 Waiting: 751 # Лимиты файловых дескрипторов cat /proc/$(pgrep -f 'nginx: master')/limits | grep 'open files' ulimit -n Нагрузочное тестирование# wrk — современный HTTP benchmarker # Установка: apt install wrk / brew install wrk wrk -t12 -c400 -d30s --latency http://your-server/api/endpoint # Параметры: # -t12 — 12 потоков (= число ядер) # -c400 — 400 конкурентных соединений # -d30s — 30 секунд # --latency — показать перцентили задержек # Вывод: # Running 30s test @ http://your-server/ # 12 threads and 400 connections # Thread Stats Avg Stdev Max +/- Stdev # Latency 23.45ms 8.12ms 890ms 92.34% # Req/Sec 1.45k 312.45 2.10k 68.23% # Latency Distribution # 50% 21.23ms # 75% 28.45ms # 90% 35.67ms # 99% 78.90ms ← 99-й перцентиль важнее среднего! # 521245 requests in 30.00s, 2.34GB read # Requests/sec: 17374.83 # Transfer/sec: 79.92MB # ab (Apache Benchmark) — встроен везде, но хуже wrk ab -n 10000 -c 100 http://your-server/ # hey — ещё один вариант (Go) hey -n 50000 -c 200 http://your-server/ Мониторинг в реальном времени# Топ запросов по времени ответа (из access_log) awk '{print $NF, $7}' /var/log/nginx/access.log | sort -rn | head -20 # Количество запросов в секунду (live) tail -f /var/log/nginx/access.log | pv -l -i 1 > /dev/null # Распределение кодов ответов за последний час awk -v d="$(date -d '1 hour ago' '+%d/%b/%Y:%H')" \ '$4 ~ d {print $9}' /var/log/nginx/access.log | sort | uniq -c | sort -rn # Топ IP по количеству запросов awk '{print $1}' /var/log/nginx/access.log | sort | uniq -c | sort -rn | head -20 Уровень 1: Системные настройки LinuxNginx ограничен операционной системой. Без правильной настройки Linux все оптимизации Nginx упрутся в системный потолок. Файловые дескрипторы# /etc/security/limits.conf nginx soft nofile 65535 nginx hard nofile 65535 root soft nofile 65535 root hard nofile 65535 # Для systemd (приоритет над limits.conf): # /etc/systemd/system/nginx.service.d/override.conf [Service] LimitNOFILE=65535 sudo systemctl daemon-reload sudo systemctl restart nginx # Проверка: cat /proc/$(cat /var/run/nginx.pid)/limits | grep 'open files' Сетевой стек (sysctl)# /etc/sysctl.d/99-nginx.conf # ===== TCP буферы ===== # Увеличиваем буферы приёма/передачи net.core.rmem_default = 262144 net.core.wmem_default = 262144 net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 87380 16777216 net.ipv4.tcp_wmem = 4096 65536 16777216 # ===== Очередь соединений ===== # Размер очереди для accept() — важно при всплесках трафика net.core.somaxconn = 65535 net.ipv4.tcp_max_syn_backlog = 65535 # ===== TCP оптимизации ===== # Быстрое переиспользование TIME_WAIT соединений net.ipv4.tcp_tw_reuse = 1 # Алгоритм управления перегрузкой # BBR — лучший выбор для большинства продакшен-сценариев (ядро 4.9+) net.core.default_qdisc = fq net.ipv4.tcp_congestion_control = bbr # Уменьшаем время FIN_WAIT2 (2 минуты по умолчанию — слишком долго) net.ipv4.tcp_fin_timeout = 15 # Максимальное число открытых TCP соединений net.ipv4.tcp_max_tw_buckets = 1440000 # Разрешаем bind на порт без TIME_WAIT net.ipv4.tcp_timestamps = 1 # ===== Очередь обработки пакетов ===== net.core.netdev_max_backlog = 65535 # ===== Локальный диапазон портов ===== # Для upstream keepalive нужно много эфемерных портов net.ipv4.ip_local_port_range = 1024 65535 # Применить: sudo sysctl -p /etc/sysctl.d/99-nginx.conf # Проверить BBR: sysctl net.ipv4.tcp_congestion_control # должно быть: net.ipv4.tcp_congestion_control = bbr Прозрачные hugepages и планировщик I/O# Для высоконагруженных серверов — отключить transparent hugepages # (могут вызывать latency spikes) echo never > /sys/kernel/mm/transparent_hugepage/enabled echo never > /sys/kernel/mm/transparent_hugepage/defrag # В /etc/rc.local для постоянства: echo 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' >> /etc/rc.local echo 'echo never > /sys/kernel/mm/transparent_hugepage/defrag' >> /etc/rc.local # Планировщик I/O для SSD (none или mq-deadline быстрее cfq) echo mq-deadline > /sys/block/sda/queue/scheduler # Проверить: cat /sys/block/sda/queue/scheduler Уровень 2: Базовый конфиг Nginx — Worker и Events# /etc/nginx/nginx.conf # ===== WORKER PROCESSES ===== # Правило: 1 воркер на 1 физическое ядро CPU # auto — Nginx сам определяет количество ядер (рекомендуется) worker_processes auto; # Привязка воркеров к ядрам (CPU affinity) # Уменьшает cache miss у процессора, повышает производительность ~5-10% # Для 4 ядер: # worker_cpu_affinity 0001 0010 0100 1000; # Для auto (Nginx 1.9+): worker_cpu_affinity auto; # Приоритет процесса (от -20 до 20, меньше = выше приоритет) # -5 даёт небольшое преимущество без ущерба системе worker_priority -5; # Файловые дескрипторы на воркер (должно совпадать с ulimit -n) worker_rlimit_nofile 65535; # PID файл pid /var/run/nginx.pid; # ===== ERROR LOG ===== # warn в продакшене (info/debug — слишком verbose для highload) error_log /var/log/nginx/error.log warn; # ===== EVENTS ===== events { # Максимум соединений на воркер # Итого соединений = worker_processes × worker_connections # Не ставьте больше 65535 — ограничение Linux # Реально для highload: 4096-16384 worker_connections 10240; # epoll — единственный правильный выбор на Linux # (Nginx выбирает автоматически, но явно лучше) use epoll; # Принимать все ожидающие соединения за один вызов accept() # ОБЯЗАТЕЛЬНО для highload! Без этого воркер обрабатывает по 1 соединению multi_accept on; # Принимать мьютекс для accept() (устарело в современных ядрах, # но оставляем для совместимости) # accept_mutex off; # Можно отключить на ядрах 3.9+ } Уровень 3: HTTP блок — основные оптимизацииhttp { # ===== БАЗОВЫЕ MIME ТИПЫ ===== include /etc/nginx/mime.types; default_type application/octet-stream; # ===== SENDFILE: ZERO-COPY ПЕРЕДАЧА ФАЙЛОВ ===== # Передаёт файлы напрямую из файловой системы в сокет # минуя user space — экономит копирование данных в памяти # ОБЯЗАТЕЛЬНО для статики! sendfile on; # Отправлять заголовки и начало файла в одном TCP-пакете # Работает только совместно с sendfile on tcp_nopush on; # Отключить алгоритм Nagle — не буферизировать маленькие пакеты # Уменьшает latency для интерактивных запросов # tcp_nopush и tcp_nodelay вместе: сначала накапливаем (nopush), # потом сразу отправляем последний пакет (nodelay) tcp_nodelay on; # ===== KEEPALIVE ===== # Время жизни keepalive соединения с клиентом # 65s стандарт, 75s — максимум до таймаута прокси (Cloudflare = 90s) keepalive_timeout 65; # Максимум запросов через одно keepalive соединение # После этого — закрываем и открываем новое # 1000 — хороший баланс между переиспользованием и памятью keepalive_requests 1000; # ===== БУФЕРЫ ===== # Эти настройки критически важны для производительности proxy! # Размер хэш-таблицы имён серверов server_names_hash_bucket_size 128; server_names_hash_max_size 1024; # Буфер для чтения заголовков запроса клиента # 16k достаточно для большинства запросов, включая большие cookie client_header_buffer_size 16k; large_client_header_buffers 4 32k; # Максимальный размер тела запроса (загрузка файлов) # 0 — отключить ограничение (не рекомендуется!) client_max_body_size 64m; # Таймаут на чтение тела запроса client_body_timeout 30s; # Таймаут на чтение заголовков запроса client_header_timeout 15s; # Таймаут на отправку ответа клиенту # (между двумя последовательными операциями send) send_timeout 30s; # Буфер для тела запроса в памяти (если больше — пишем на диск) client_body_buffer_size 256k; # ===== ТИПЫ ХЭШЕЙ ===== types_hash_max_size 4096; types_hash_bucket_size 128; # ===== БЕЗОПАСНОСТЬ: УБИРАЕМ ВЕРСИЮ NGINX ===== server_tokens off; # ===== ЛОГИ ===== # Формат логов с временем обработки запроса — важно для анализа! log_format main '$remote_addr - $remote_user [$time_local] ' '"$request" $status $body_bytes_sent ' '"$http_referer" "$http_user_agent" ' 'rt=$request_time uct=$upstream_connect_time ' 'uht=$upstream_header_time urt=$upstream_response_time'; # Расширенный формат для детальной диагностики: log_format detailed '$remote_addr - $remote_user [$time_local] ' '"$request" $status $body_bytes_sent ' 'rt=$request_time ' 'urt="$upstream_response_time" ' 'uct="$upstream_connect_time" ' 'uht="$upstream_header_time" ' 'cs=$upstream_cache_status ' 'host=$host ' 'xff="$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main buffer=64k flush=5s; # buffer=64k — буферизация логов (не пишем на диск каждую строку) # flush=5s — сбрасываем буфер каждые 5 секунд # Для максимальной производительности — отключить access_log на статике # (настраивается в location блоках) # ===== ВКЛЮЧАЕМ ПОДКОНФИГИ ===== include /etc/nginx/conf.d/*.conf; } Уровень 4: Gzip и Brotli — сжатие ответовhttp { # ===== GZIP ===== gzip on; # Не сжимать ответы для IE6 (исторический артефакт, можно убрать) gzip_disable "msie6"; # Сжимать ответы для всех клиентов, в т.ч. через прокси # any — сжимать независимо от заголовка Via gzip_proxied any; # Уровень сжатия: 1-9 # 1 — быстро, мало сжатие (~60%) # 6 — баланс (рекомендуется для продакшена ~70%) # 9 — максимум, но тратит значительно больше CPU (~72%, но в 3-5 раз медленнее 6) gzip_comp_level 6; # Минимальный размер для сжатия (не сжимать маленькие файлы — смысла нет) gzip_min_length 1024; # Буферы для сжатия gzip_buffers 16 8k; # HTTP версия (сжимать и для HTTP/1.0 клиентов — редко нужно) gzip_http_version 1.1; # Типы контента для сжатия # text/html сжимается всегда (по умолчанию) gzip_types text/plain text/css text/xml text/javascript application/json application/javascript application/xml application/xml+rss application/x-javascript application/x-font-ttf application/vnd.ms-fontobject font/opentype image/svg+xml image/x-icon; # Добавить заголовок Vary: Accept-Encoding # Указывает прокси-серверам хранить сжатые и несжатые версии отдельно gzip_vary on; # ===== BROTLI (требует модуль ngx_brotli) ===== # Brotli на 15-25% эффективнее gzip при тех же CPU-затратах # Поддерживается всеми современными браузерами # Установка модуля (Ubuntu/Debian): # apt install libnginx-mod-http-brotli-filter # Или из исходников: https://github.com/google/ngx_brotli # load_module modules/ngx_http_brotli_filter_module.so; # load_module modules/ngx_http_brotli_static_module.so; brotli on; brotli_comp_level 6; # 0-11, 6 — хороший баланс brotli_min_length 1024; brotli_types text/plain text/css text/xml text/javascript application/json application/javascript application/xml application/xml+rss image/svg+xml; # Brotli static — отдавать предкомпрессированные .br файлы # Нужно сгенерировать: find /var/www -name "*.js" | xargs -I{} brotli {} brotli_static on; # ===== GZIP STATIC — предкомпрессированные .gz файлы ===== # Если файл app.js.gz существует — отдаём его без CPU на сжатие gzip_static on; } Предварительное сжатие статики (экономит CPU)#!/bin/bash # Скрипт для предкомпрессии статических файлов STATIC_DIR="/var/www/html" find "$STATIC_DIR" \ \( -name "*.js" -o -name "*.css" -o -name "*.html" -o -name "*.json" \ -o -name "*.xml" -o -name "*.svg" \) \ -type f | while read file; do # gzip (только если .gz не существует или файл новее) if [ ! -f "${file}.gz" ] || [ "$file" -nt "${file}.gz" ]; then gzip -9 -k "$file" fi # brotli if command -v brotli &> /dev/null; then if [ ! -f "${file}.br" ] || [ "$file" -nt "${file}.br" ]; then brotli -q 11 -k "$file" fi fi done echo "Предкомпрессия завершена: $(find $STATIC_DIR -name '*.gz' | wc -l) gz файлов" Уровень 5: Кэширование — proxy_cache и FastCGI cacheProxy Cache (для проксирования на upstream)http { # ===== ЗОНА КЭША ===== # keys_zone=cache_name:10m — зона памяти для хранения ключей # levels=1:2 — структура директорий (более эффективный поиск) # inactive=60m — удалять неиспользуемые файлы через 60 минут # max_size=10g — максимальный размер кэша на диске # use_temp_path=off — не использовать временный путь (быстрее) proxy_cache_path /var/cache/nginx/proxy levels=1:2 keys_zone=proxy_cache:50m inactive=60m max_size=10g use_temp_path=off; server { location /api/ { proxy_pass http://backend; # ===== PROXY БУФЕРЫ ===== # Буферизировать ответ от upstream в памяти # Важно: без буферизации Nginx держит соединение с upstream # пока клиент не скачает весь ответ (медленные клиенты = занятые воркеры) proxy_buffering on; # Количество и размер буферов для тела ответа # proxy_buffers × proxy_buffer_size = RAM на соединение # 32 × 16k = 512k на соединение proxy_buffers 32 16k; proxy_buffer_size 16k; # Для заголовков ответа # Если ответ не помещается в proxy_buffers — пишем во временный файл proxy_max_temp_file_size 0; # 0 = отключить (пишем всё в память) # или установить лимит: proxy_max_temp_file_size 1024m; # Буфер для занятых соединений (busy = клиент читает медленно) proxy_busy_buffers_size 64k; # ===== PROXY ТАЙМАУТЫ ===== # Таймаут установки соединения с upstream proxy_connect_timeout 5s; # Таймаут между двумя последовательными операциями чтения от upstream proxy_read_timeout 60s; # Таймаут передачи данных к upstream proxy_send_timeout 60s; # ===== ЗАГОЛОВКИ К UPSTREAM ===== proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; proxy_http_version 1.1; # HTTP/1.1 для keepalive! proxy_set_header Connection ""; # Убрать заголовок Connection для keepalive # ===== КЭШИРОВАНИЕ ===== proxy_cache proxy_cache; proxy_cache_valid 200 302 10m; # Кэшировать 200/302 на 10 минут proxy_cache_valid 404 1m; # 404 — на 1 минуту proxy_cache_valid any 30s; # Остальное — 30 секунд # Ключ кэша (что уникально идентифицирует запрос) proxy_cache_key "$scheme$request_method$host$request_uri"; # Методы для кэширования (по умолчанию только GET и HEAD) proxy_cache_methods GET HEAD; # Кэшировать ответы с заголовком Set-Cookie # (осторожно — персональные данные!) # proxy_ignore_headers Set-Cookie; # Stale cache — отдавать устаревший кэш пока upstream недоступен # Спасает от "пятистотки" при временных проблемах с бэкендом proxy_cache_use_stale error timeout updating http_500 http_502 http_503 http_504; # Блокировка одновременных запросов к upstream (coalescing) # Один запрос идёт к upstream, остальные ждут результата в кэше proxy_cache_lock on; proxy_cache_lock_timeout 5s; proxy_cache_lock_age 5s; # Фоновое обновление кэша (stale-while-revalidate) # Отдаём устаревший кэш и одновременно запускаем фоновое обновление proxy_cache_background_update on; # Добавляем заголовок X-Cache-Status для отладки add_header X-Cache-Status $upstream_cache_status always; } # ===== СТАТИКА: МАКСИМАЛЬНЫЙ КЭШ ===== location ~* \.(jpg|jpeg|png|gif|ico|svg|webp|woff|woff2|ttf|eot)$ { expires 1y; add_header Cache-Control "public, immutable, max-age=31536000"; access_log off; # Не логировать статику (экономит I/O) tcp_nodelay off; # Для больших файлов nopush важнее nodelay sendfile on; aio on; # Асинхронный I/O для больших файлов } location ~* \.(js|css)$ { expires 1y; add_header Cache-Control "public, immutable, max-age=31536000"; access_log off; } location ~* \.(html|htm)$ { expires 1h; add_header Cache-Control "public, max-age=3600, must-revalidate"; } } } FastCGI Cache (для PHP-FPM)http { # Зона FastCGI кэша fastcgi_cache_path /var/cache/nginx/fastcgi levels=1:2 keys_zone=fastcgi_cache:20m inactive=60m max_size=5g use_temp_path=off; # Глобальная переменная для определения статуса кэша map $request_method $no_cache_method { default 0; POST 1; PUT 1; DELETE 1; PATCH 1; } server { set $skip_cache 0; # Не кэшировать авторизованных пользователей (например, WordPress) if ($http_cookie ~* "wordpress_logged_in|woocommerce_cart") { set $skip_cache 1; } # Не кэшировать POST запросы if ($request_method = POST) { set $skip_cache 1; } # Не кэшировать URL с query string (можно убрать если кэш по полному URL) # if ($query_string != "") { # set $skip_cache 1; # } # Не кэшировать admin/личный кабинет if ($request_uri ~* "^/admin|^/wp-admin|^/login") { set $skip_cache 1; } location ~ \.php$ { include fastcgi_params; fastcgi_pass unix:/run/php/php8.2-fpm.sock; fastcgi_index index.php; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; # ===== FastCGI БУФЕРЫ ===== fastcgi_buffers 16 16k; fastcgi_buffer_size 32k; fastcgi_busy_buffers_size 64k; # Таймауты fastcgi_connect_timeout 5s; fastcgi_read_timeout 60s; fastcgi_send_timeout 60s; # ===== КЭШ ===== fastcgi_cache fastcgi_cache; fastcgi_cache_key "$scheme$request_method$host$request_uri"; fastcgi_cache_valid 200 5m; fastcgi_cache_valid 301 302 1m; fastcgi_cache_valid 404 30s; fastcgi_cache_bypass $skip_cache; fastcgi_no_cache $skip_cache; fastcgi_cache_use_stale error timeout updating http_500 http_503; fastcgi_cache_lock on; fastcgi_cache_background_update on; add_header X-FastCGI-Cache $upstream_cache_status; } } } Инвалидация кэша# Очистить весь кэш proxy find /var/cache/nginx/proxy -type f -delete # Очистить конкретный URL (через модуль ngx_cache_purge): # location ~ /purge(/.*) { # fastcgi_cache_purge fastcgi_cache "$scheme$request_method$host$1"; # } # curl -X PURGE http://your-server/api/products/123 # Мониторинг кэша: # X-Cache-Status значения: # HIT — ответ из кэша ✅ # MISS — кэш не нашёл, запрос к upstream # BYPASS — кэш пропущен (skip_cache = 1) # EXPIRED — кэш устарел, запрошен свежий ответ # STALE — отдан устаревший кэш (upstream недоступен) # UPDATING — отдан устаревший кэш пока фоновое обновление # REVALIDATED — кэш подтверждён (304 от upstream) Уровень 6: Upstream Keepalive и балансировкаhttp { # ===== UPSTREAM С KEEPALIVE ===== upstream backend { # Алгоритм балансировки # least_conn — меньше соединений = меньше задержка (лучше для long-poll) # ip_hash — один клиент всегда на один сервер (сессии) # По умолчанию: round-robin least_conn; server 10.0.0.10:8080 weight=3; # Тройной вес (мощнее) server 10.0.0.11:8080 weight=1; server 10.0.0.12:8080 weight=1 backup; # Резервный (включается при падении основных) # Параметры health check (требует nginx plus или upstream_check_module): # server 10.0.0.10:8080 max_fails=3 fail_timeout=30s; # ===== KEEPALIVE ПУЛА К UPSTREAM ===== # Количество keepalive соединений в пуле (на воркер!) # НЕ максимальное число соединений — это пул переиспользуемых! # Правило: (RPS / worker_count) × avg_response_time_sec × 1.5 # При 10000 RPS, 4 воркерах, 20мс ответе: 10000/4 × 0.02 × 1.5 = 75 keepalive 128; # Таймаут keepalive соединения с upstream keepalive_timeout 60s; # Максимум запросов через одно keepalive соединение к upstream keepalive_requests 10000; } server { location / { proxy_pass http://backend; # КРИТИЧЕСКИ ВАЖНО для upstream keepalive! # HTTP/1.1 поддерживает keepalive (1.0 — нет) proxy_http_version 1.1; # Убираем заголовок Connection: close (стандарт для HTTP/1.0 прокси) proxy_set_header Connection ""; } } } Уровень 7: SSL/TLS — производительность без потери безопасностиhttp { # ===== SSL СЕССИИ ===== # Кэш SSL сессий (повторное использование TLS handshake) # 1m ≈ 4000 сессий. Для highload: 50m-100m ssl_session_cache shared:SSL:50m; # Время жизни кэшированной SSL сессии ssl_session_timeout 1d; # 24 часа — максимум рекомендуемый # SSL Session Tickets (альтернатива session cache, статeful у клиента) # Для идеальной forward secrecy — отключить # Для максимальной производительности — включить ssl_session_tickets off; # Безопаснее, но чуть медленнее # ===== ПРОТОКОЛЫ И ШИФРЫ ===== # Только TLS 1.2 и 1.3 (1.0 и 1.1 — уязвимы и устарели) ssl_protocols TLSv1.2 TLSv1.3; # Шифры (Mozilla Modern конфигурация) ssl_ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384; # Сервер выбирает шифр (не клиент) — важно для безопасности ssl_prefer_server_ciphers off; # off для TLS 1.3 (там нет выбора шифра) # ===== ECDH КРИВАЯ ===== ssl_ecdh_curve X25519:prime256v1:secp384r1; # ===== STAPLING ===== # OCSP Stapling: сервер сам проверяет сертификат и включает ответ в TLS handshake # Клиенту не нужно делать отдельный запрос к CA — быстрее! ssl_stapling on; ssl_stapling_verify on; resolver 8.8.8.8 8.8.4.4 1.1.1.1 valid=300s; resolver_timeout 5s; # ===== DH параметры (для DHE шифров) ===== # Генерировать: openssl dhparam -out /etc/nginx/dhparam.pem 2048 # ssl_dhparam /etc/nginx/dhparam.pem; server { listen 443 ssl; # ===== HTTP/2 ===== # Мультиплексирование запросов — один TCP для множества запросов # Сжатие заголовков (HPACK) — экономит трафик # Server Push — отправка ресурсов до запроса (редко нужен) listen 443 ssl http2; ssl_certificate /etc/nginx/ssl/fullchain.pem; ssl_certificate_key /etc/nginx/ssl/privkey.pem; # ===== HSTS ===== # Браузер не будет делать HTTP запросы — сразу HTTPS # Включать только когда уверены что HTTPS работает корректно! add_header Strict-Transport-Security "max-age=31536000; includeSubDomains; preload" always; # ===== SECURITY ЗАГОЛОВКИ ===== add_header X-Frame-Options "SAMEORIGIN" always; add_header X-Content-Type-Options "nosniff" always; add_header X-XSS-Protection "1; mode=block" always; add_header Referrer-Policy "strict-origin-when-cross-origin" always; add_header Permissions-Policy "geolocation=(), microphone=()" always; } # Редирект HTTP → HTTPS server { listen 80; server_name example.com www.example.com; # 301 для всего кроме .well-known (Let's Encrypt) location /.well-known/acme-challenge/ { root /var/www/html; } location / { return 301 https://$host$request_uri; } } } Измерение времени TLS handshake# Проверка SSL без кэша (первое соединение) curl -w "\n=== Timing ===\nDNS: %{time_namelookup}s\nConnect: %{time_connect}s\nTLS: %{time_appconnect}s\nTTFB: %{time_starttransfer}s\nTotal: %{time_total}s\n" \ --no-keepalive -s -o /dev/null https://your-server/ # С session resumption (второе соединение) curl -w "TLS Resumption Total: %{time_total}s\n" \ --no-keepalive -s -o /dev/null https://your-server/ \ --tls-session-info # Проверка OCSP Stapling: echo QUIT | openssl s_client -connect your-server:443 -status 2>/dev/null | \ grep -A 17 'OCSP response' Уровень 8: Rate Limiting — защита и QoShttp { # ===== ЗОНЫ RATE LIMITING ===== # Ограничение по IP адресу # zone=name:10m — 10МБ памяти (~160 000 IP адресов) # rate=100r/s — 100 запросов в секунду с одного IP limit_req_zone $binary_remote_addr zone=api_limit:20m rate=100r/s; # Ограничение для авторизации (жёстче!) limit_req_zone $binary_remote_addr zone=auth_limit:10m rate=5r/m; # Ограничение по URL + IP (для конкретных эндпоинтов) limit_req_zone "$binary_remote_addr$uri" zone=upload_limit:10m rate=5r/m; # Ограничение одновременных соединений limit_conn_zone $binary_remote_addr zone=conn_limit:10m; # Лог уровень для rejected запросов (warn — не засорять error.log) limit_req_log_level warn; # Код ответа при превышении лимита (429 = Too Many Requests) limit_req_status 429; limit_conn_status 429; server { # ===== API ENDPOINT ===== location /api/ { # burst=200 — разрешить всплески до 200 запросов сверх лимита # nodelay — не задерживать burst запросы, обрабатывать немедленно # (без nodelay — запросы ставятся в очередь и задерживаются) limit_req zone=api_limit burst=200 nodelay; # Максимум 100 одновременных соединений с одного IP limit_conn conn_limit 100; proxy_pass http://backend; } # ===== АВТОРИЗАЦИЯ: СТРОГИЙ ЛИМИТ ===== location /api/auth/ { limit_req zone=auth_limit burst=10 nodelay; limit_conn conn_limit 10; proxy_pass http://backend; } # ===== ЗАГРУЗКА ФАЙЛОВ ===== location /upload/ { limit_req zone=upload_limit burst=2 nodelay; limit_conn conn_limit 5; client_max_body_size 100m; proxy_pass http://backend; } } } Белые списки для rate limitinghttp { # Карта: 0 = применять limit, 1 = пропустить geo $limit { default 1; # Ограничивать всех 10.0.0.0/8 0; # Доверенная внутренняя сеть — без ограничений 192.168.0.0/16 0; # Локальная сеть — без ограничений 1.2.3.4 0; # Конкретный IP (мониторинг, партнёры) } # Если $limit = 0 — пустой ключ, limit_req не применяется map $limit $limit_key { 0 ""; 1 $binary_remote_addr; } limit_req_zone $limit_key zone=api_limit:20m rate=100r/s; } Уровень 9: Open File Cache и другие деталиhttp { # ===== OPEN FILE CACHE ===== # Кэшировать информацию об открытых файлах: # файловые дескрипторы, размеры, время модификации, ошибки # Особенно важно при большом количестве файлов статики! # max=10000 — максимум 10000 записей в кэше # inactive=30s — удалять если не обращались 30 секунд open_file_cache max=10000 inactive=30s; # Сколько раз файл должен быть запрошен за inactive период # чтобы остаться в кэше open_file_cache_min_uses 2; # Проверять актуальность кэша каждые 60 секунд open_file_cache_valid 60s; # Кэшировать ошибки (файл не найден, нет прав) open_file_cache_errors on; # ===== SENDFILE + AIO для больших файлов ===== # Для файлов > 8MB — асинхронный I/O эффективнее aio threads; # AIO через thread pool (Nginx 1.7.11+) # или aio on; # POSIX AIO (старый вариант, хуже) directio 8m; # Файлы > 8MB: читать напрямую, минуя page cache # Полезно для больших видеофайлов которые не нужно кэшировать # ===== OUTPUT BUFFERS ===== # Размер буфера вывода (используется с sendfile) output_buffers 2 512k; # ===== ПЕРЕМЕННЫЕ ===== # Кэш переменных (для complex map и geo директив) variables_hash_max_size 2048; variables_hash_bucket_size 128; # ===== MAP HASH ===== map_hash_max_size 2048; map_hash_bucket_size 128; } Уровень 10: Полный production конфиг сервера# /etc/nginx/conf.d/example.com.conf server { listen 443 ssl http2; listen [::]:443 ssl http2; server_name example.com www.example.com; root /var/www/html; index index.html index.php; # SSL ssl_certificate /etc/letsencrypt/live/example.com/fullchain.pem; ssl_certificate_key /etc/letsencrypt/live/example.com/privkey.pem; # Логи с детальным форматом access_log /var/log/nginx/example.com.access.log detailed buffer=64k flush=5s; error_log /var/log/nginx/example.com.error.log warn; # Скрываем .git, .env и другие служебные файлы location ~ /\. { deny all; access_log off; log_not_found off; } location ~* \.(env|log|sh|sql|conf|config|bak|backup|swp|tmp)$ { deny all; } # ===== СТАТИКА: МАКСИМАЛЬНАЯ ОТДАЧА ===== location ~* \.(jpg|jpeg|png|gif|ico|svg|webp|avif|woff|woff2|ttf|eot|otf)$ { expires 1y; add_header Cache-Control "public, immutable"; add_header Vary Accept-Encoding; access_log off; log_not_found off; gzip_static on; brotli_static on; } location ~* \.(js|css|map)$ { expires 1y; add_header Cache-Control "public, immutable"; access_log off; gzip_static on; brotli_static on; } # ===== FAVICON И ROBOTS ===== location = /favicon.ico { access_log off; log_not_found off; expires 1y; } location = /robots.txt { access_log off; log_not_found off; } # ===== API ===== location /api/ { limit_req zone=api_limit burst=200 nodelay; limit_conn conn_limit 100; proxy_pass http://backend; proxy_http_version 1.1; proxy_set_header Connection ""; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; proxy_cache proxy_cache; proxy_cache_valid 200 5m; proxy_cache_valid 404 30s; proxy_cache_use_stale error timeout updating http_500 http_502 http_503 http_504; proxy_cache_lock on; proxy_cache_background_update on; add_header X-Cache-Status $upstream_cache_status always; } # ===== PHP ===== location ~ \.php$ { try_files $uri =404; fastcgi_split_path_info ^(.+\.php)(/.+)$; fastcgi_pass unix:/run/php/php8.2-fpm.sock; fastcgi_index index.php; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; include fastcgi_params; fastcgi_buffers 16 16k; fastcgi_buffer_size 32k; fastcgi_read_timeout 60s; fastcgi_cache fastcgi_cache; fastcgi_cache_valid 200 5m; fastcgi_cache_bypass $skip_cache; fastcgi_no_cache $skip_cache; fastcgi_cache_use_stale error timeout updating http_500 http_503; fastcgi_cache_lock on; add_header X-FastCGI-Cache $upstream_cache_status; } # ===== КОРЕНЬ ===== location / { try_files $uri $uri/ /index.php?$query_string; } } Диагностика и мониторинг в продакшенеStub Status модульserver { listen 127.0.0.1:8080; location /nginx_status { stub_status; allow 127.0.0.1; allow 10.0.0.0/8; # Сеть мониторинга deny all; } } # Парсинг nginx_status: curl -s http://127.0.0.1:8080/nginx_status # Active connections: 1247 # server accepts handled requests # 87354291 87354291 245912847 # Reading: 12 Writing: 847 Waiting: 388 # Интерпретация: # Active = Reading + Writing + Waiting # Waiting = keepalive соединения (ждут следующего запроса) # Writing = активно пишем ответ клиенту # Reading = читаем запрос от клиента # Если Waiting >> Writing — много keepalive соединений, это нормально # Если Reading >> 0 постоянно — клиенты медленно отправляют запросы # Если Writing = worker_processes × worker_connections — всё занято! # accepts == handled — нет dropped connections. Если differs — проблема! Анализ логов# Медленные запросы (> 1 секунды) awk '$NF > 1' /var/log/nginx/access.log | \ awk '{print $NF, $7}' | sort -rn | head -20 # HIT rate кэша grep -o 'cs=[A-Z]*' /var/log/nginx/access.log | \ sort | uniq -c | sort -rn # 94521 cs=HIT ← 87% HIT rate — хорошо! # 12305 cs=MISS # 1823 cs=BYPASS # 289 cs=EXPIRED # Ошибки upstream grep 'upstream timed out\|connect() failed\|upstream prematurely' \ /var/log/nginx/error.log | tail -50 # Топ 5xx ошибок awk '$9 ~ /^5/' /var/log/nginx/access.log | \ awk '{print $9, $7}' | sort | uniq -c | sort -rn | head -20 Чеклист тюнинга: финальная проверка#!/bin/bash # Быстрая проверка ключевых параметров echo "=== NGINX PERFORMANCE CHECKLIST ===" # 1. Worker processes WP=$(nginx -T 2>/dev/null | grep 'worker_processes' | tail -1 | awk '{print $2}') CORES=$(nproc) echo "Worker processes: $WP (cores: $CORES)" # 2. Worker connections WC=$(nginx -T 2>/dev/null | grep 'worker_connections' | tail -1 | awk '{print $2}') echo "Worker connections: $WC" # 3. File descriptors FD=$(cat /proc/$(cat /var/run/nginx.pid 2>/dev/null || echo 1)/limits \ 2>/dev/null | grep 'open files' | awk '{print $4}') echo "File descriptors limit: $FD" # 4. sendfile SF=$(nginx -T 2>/dev/null | grep -E '^\s+sendfile' | tail -1) echo "Sendfile: $SF" # 5. gzip GZ=$(nginx -T 2>/dev/null | grep -E '^\s+gzip ' | tail -1) echo "Gzip: $GZ" # 6. SSL session cache SSL=$(nginx -T 2>/dev/null | grep 'ssl_session_cache' | tail -1) echo "SSL session cache: $SSL" # 7. BBR echo "TCP congestion: $(sysctl -n net.ipv4.tcp_congestion_control)" # 8. Тест конфигурации nginx -t && echo "Config: OK" || echo "Config: ERROR!" echo "" echo "=== ТЕКУЩАЯ НАГРУЗКА ===" curl -s http://127.0.0.1:8080/nginx_status 2>/dev/null || echo "stub_status недоступен" Типичные ошибки и мифыМиф 1: "worker_processes 4096 увеличит производительность" Нет. Оптимум — по одному воркеру на ядро. Больше воркеров = больше переключений контекста = хуже. Миф 2: "worker_connections 65535 — максимум соединений" Нет. Это максимум на один воркер. Итого: worker_processes × worker_connections. При 4 воркерах и 10240 соединениях = 40960 одновременных соединений. Миф 3: "keepalive_timeout 0 ускорит сервер" Наоборот. Keepalive экономит TLS handshake и TCP установку соединения. Отключение keepalive нагрузит сервер больше. Миф 4: "gzip_comp_level 9 — лучше" Нет. Разница в размере между уровнями 6 и 9 — 1-3%. Разница в CPU — в 3-5 раз. Используйте gzip_comp_level 6. Ошибка: proxy_cache без proxy_cache_use_stale При недоступности upstream без use_stale клиенты получат 502. С use_stale error timeout — получат устаревший кэш пока upstream восстанавливается. Всегда включайте! Ошибка: не настроен upstream keepalive Без keepalive в блоке upstream каждый запрос создаёт новое TCP соединение к backend. При 1000 RPS — 1000 новых TCP handshake в секунду. С keepalive 64 — переиспользуются 64 соединения. ЗаключениеТюнинг Nginx — это итеративный процесс. Хороший порядок: Системный уровень: sysctl, ulimit, BBR — без этого упрётесь в ОС Workers и events: worker_processes auto, multi_accept on, epoll Буферы и таймауты: адаптируйте под характер трафика (размер ответов, скорость клиентов) Кэш: proxy_cache или fastcgi_cache — самый большой прирост производительности Upstream keepalive: критично для высоких RPS SSL оптимизация: session cache + stapling + HTTP/2 Сжатие: gzip + brotli_static для предкомпрессии Rate limiting: защита без ущерба для легитимного трафика Измеряйте до и после каждого изменения. Доверяйте цифрам, а не интуиции. И помните: лучший тюнинг — тот, который решает вашу конкретную проблему, а не скопированный из статьи.
С чего начинается тюнингNginx в дефолтной конфигурации — это как спортивный автомобиль с заводскими настройками для езды по бездорожью: едет, но не так быстро, как мог бы. Хорошая новость: большинство важных оптимизаций достигается правкой конфига, а не покупкой более мощного железа. Плохая новость: многие "гайды по тюнингу" в интернете — копипаста десятилетней давности, без понимания что и зачем. Параметры для Nginx 1.8 на 2-ядерном сервере копируют на 32-ядерный продакшен под highload — и удивляются что не помогает или становится хуже. Этот материал — о том, как думать о тюнинге Nginx: что делает каждый параметр, какие компромиссы он несёт, и как проверить что оптимизация действительно работает. Версии в статье: Nginx 1.24+ / 1.25+ (mainline). Большинство конфигов работают с 1.18+. Диагностика перед тюнингом: что измерятьТюнинг без метрик — гадание на кофейной гуще. Сначала измеряем, потом меняем, потом снова измеряем. Текущее состояние Nginx# Версия и скомпилированные модули nginx -V 2>&1 | tr ' ' '\n' | grep -E 'version|with-|without-' # Активная конфигурация (проверка синтаксиса) nginx -t # Рабочие процессы и их нагрузка ps aux | grep nginx top -p $(pgrep -d',' nginx) # Открытые соединения ss -s ss -tnp | grep nginx | wc -l # Статус (если включён stub_status) curl -s http://127.0.0.1/nginx_status # Active connections: 847 # server accepts handled requests # 12340582 12340582 28473910 # Reading: 12 Writing: 84 Waiting: 751 # Лимиты файловых дескрипторов cat /proc/$(pgrep -f 'nginx: master')/limits | grep 'open files' ulimit -n Нагрузочное тестирование# wrk — современный HTTP benchmarker # Установка: apt install wrk / brew install wrk wrk -t12 -c400 -d30s --latency http://your-server/api/endpoint # Параметры: # -t12 — 12 потоков (= число ядер) # -c400 — 400 конкурентных соединений # -d30s — 30 секунд # --latency — показать перцентили задержек # Вывод: # Running 30s test @ http://your-server/ # 12 threads and 400 connections # Thread Stats Avg Stdev Max +/- Stdev # Latency 23.45ms 8.12ms 890ms 92.34% # Req/Sec 1.45k 312.45 2.10k 68.23% # Latency Distribution # 50% 21.23ms # 75% 28.45ms # 90% 35.67ms # 99% 78.90ms ← 99-й перцентиль важнее среднего! # 521245 requests in 30.00s, 2.34GB read # Requests/sec: 17374.83 # Transfer/sec: 79.92MB # ab (Apache Benchmark) — встроен везде, но хуже wrk ab -n 10000 -c 100 http://your-server/ # hey — ещё один вариант (Go) hey -n 50000 -c 200 http://your-server/ Мониторинг в реальном времени# Топ запросов по времени ответа (из access_log) awk '{print $NF, $7}' /var/log/nginx/access.log | sort -rn | head -20 # Количество запросов в секунду (live) tail -f /var/log/nginx/access.log | pv -l -i 1 > /dev/null # Распределение кодов ответов за последний час awk -v d="$(date -d '1 hour ago' '+%d/%b/%Y:%H')" \ '$4 ~ d {print $9}' /var/log/nginx/access.log | sort | uniq -c | sort -rn # Топ IP по количеству запросов awk '{print $1}' /var/log/nginx/access.log | sort | uniq -c | sort -rn | head -20 Уровень 1: Системные настройки LinuxNginx ограничен операционной системой. Без правильной настройки Linux все оптимизации Nginx упрутся в системный потолок. Файловые дескрипторы# /etc/security/limits.conf nginx soft nofile 65535 nginx hard nofile 65535 root soft nofile 65535 root hard nofile 65535 # Для systemd (приоритет над limits.conf): # /etc/systemd/system/nginx.service.d/override.conf [Service] LimitNOFILE=65535 sudo systemctl daemon-reload sudo systemctl restart nginx # Проверка: cat /proc/$(cat /var/run/nginx.pid)/limits | grep 'open files' Сетевой стек (sysctl)# /etc/sysctl.d/99-nginx.conf # ===== TCP буферы ===== # Увеличиваем буферы приёма/передачи net.core.rmem_default = 262144 net.core.wmem_default = 262144 net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 87380 16777216 net.ipv4.tcp_wmem = 4096 65536 16777216 # ===== Очередь соединений ===== # Размер очереди для accept() — важно при всплесках трафика net.core.somaxconn = 65535 net.ipv4.tcp_max_syn_backlog = 65535 # ===== TCP оптимизации ===== # Быстрое переиспользование TIME_WAIT соединений net.ipv4.tcp_tw_reuse = 1 # Алгоритм управления перегрузкой # BBR — лучший выбор для большинства продакшен-сценариев (ядро 4.9+) net.core.default_qdisc = fq net.ipv4.tcp_congestion_control = bbr # Уменьшаем время FIN_WAIT2 (2 минуты по умолчанию — слишком долго) net.ipv4.tcp_fin_timeout = 15 # Максимальное число открытых TCP соединений net.ipv4.tcp_max_tw_buckets = 1440000 # Разрешаем bind на порт без TIME_WAIT net.ipv4.tcp_timestamps = 1 # ===== Очередь обработки пакетов ===== net.core.netdev_max_backlog = 65535 # ===== Локальный диапазон портов ===== # Для upstream keepalive нужно много эфемерных портов net.ipv4.ip_local_port_range = 1024 65535 # Применить: sudo sysctl -p /etc/sysctl.d/99-nginx.conf # Проверить BBR: sysctl net.ipv4.tcp_congestion_control # должно быть: net.ipv4.tcp_congestion_control = bbr Прозрачные hugepages и планировщик I/O# Для высоконагруженных серверов — отключить transparent hugepages # (могут вызывать latency spikes) echo never > /sys/kernel/mm/transparent_hugepage/enabled echo never > /sys/kernel/mm/transparent_hugepage/defrag # В /etc/rc.local для постоянства: echo 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' >> /etc/rc.local echo 'echo never > /sys/kernel/mm/transparent_hugepage/defrag' >> /etc/rc.local # Планировщик I/O для SSD (none или mq-deadline быстрее cfq) echo mq-deadline > /sys/block/sda/queue/scheduler # Проверить: cat /sys/block/sda/queue/scheduler Уровень 2: Базовый конфиг Nginx — Worker и Events# /etc/nginx/nginx.conf # ===== WORKER PROCESSES ===== # Правило: 1 воркер на 1 физическое ядро CPU # auto — Nginx сам определяет количество ядер (рекомендуется) worker_processes auto; # Привязка воркеров к ядрам (CPU affinity) # Уменьшает cache miss у процессора, повышает производительность ~5-10% # Для 4 ядер: # worker_cpu_affinity 0001 0010 0100 1000; # Для auto (Nginx 1.9+): worker_cpu_affinity auto; # Приоритет процесса (от -20 до 20, меньше = выше приоритет) # -5 даёт небольшое преимущество без ущерба системе worker_priority -5; # Файловые дескрипторы на воркер (должно совпадать с ulimit -n) worker_rlimit_nofile 65535; # PID файл pid /var/run/nginx.pid; # ===== ERROR LOG ===== # warn в продакшене (info/debug — слишком verbose для highload) error_log /var/log/nginx/error.log warn; # ===== EVENTS ===== events { # Максимум соединений на воркер # Итого соединений = worker_processes × worker_connections # Не ставьте больше 65535 — ограничение Linux # Реально для highload: 4096-16384 worker_connections 10240; # epoll — единственный правильный выбор на Linux # (Nginx выбирает автоматически, но явно лучше) use epoll; # Принимать все ожидающие соединения за один вызов accept() # ОБЯЗАТЕЛЬНО для highload! Без этого воркер обрабатывает по 1 соединению multi_accept on; # Принимать мьютекс для accept() (устарело в современных ядрах, # но оставляем для совместимости) # accept_mutex off; # Можно отключить на ядрах 3.9+ } Уровень 3: HTTP блок — основные оптимизацииhttp { # ===== БАЗОВЫЕ MIME ТИПЫ ===== include /etc/nginx/mime.types; default_type application/octet-stream; # ===== SENDFILE: ZERO-COPY ПЕРЕДАЧА ФАЙЛОВ ===== # Передаёт файлы напрямую из файловой системы в сокет # минуя user space — экономит копирование данных в памяти # ОБЯЗАТЕЛЬНО для статики! sendfile on; # Отправлять заголовки и начало файла в одном TCP-пакете # Работает только совместно с sendfile on tcp_nopush on; # Отключить алгоритм Nagle — не буферизировать маленькие пакеты # Уменьшает latency для интерактивных запросов # tcp_nopush и tcp_nodelay вместе: сначала накапливаем (nopush), # потом сразу отправляем последний пакет (nodelay) tcp_nodelay on; # ===== KEEPALIVE ===== # Время жизни keepalive соединения с клиентом # 65s стандарт, 75s — максимум до таймаута прокси (Cloudflare = 90s) keepalive_timeout 65; # Максимум запросов через одно keepalive соединение # После этого — закрываем и открываем новое # 1000 — хороший баланс между переиспользованием и памятью keepalive_requests 1000; # ===== БУФЕРЫ ===== # Эти настройки критически важны для производительности proxy! # Размер хэш-таблицы имён серверов server_names_hash_bucket_size 128; server_names_hash_max_size 1024; # Буфер для чтения заголовков запроса клиента # 16k достаточно для большинства запросов, включая большие cookie client_header_buffer_size 16k; large_client_header_buffers 4 32k; # Максимальный размер тела запроса (загрузка файлов) # 0 — отключить ограничение (не рекомендуется!) client_max_body_size 64m; # Таймаут на чтение тела запроса client_body_timeout 30s; # Таймаут на чтение заголовков запроса client_header_timeout 15s; # Таймаут на отправку ответа клиенту # (между двумя последовательными операциями send) send_timeout 30s; # Буфер для тела запроса в памяти (если больше — пишем на диск) client_body_buffer_size 256k; # ===== ТИПЫ ХЭШЕЙ ===== types_hash_max_size 4096; types_hash_bucket_size 128; # ===== БЕЗОПАСНОСТЬ: УБИРАЕМ ВЕРСИЮ NGINX ===== server_tokens off; # ===== ЛОГИ ===== # Формат логов с временем обработки запроса — важно для анализа! log_format main '$remote_addr - $remote_user [$time_local] ' '"$request" $status $body_bytes_sent ' '"$http_referer" "$http_user_agent" ' 'rt=$request_time uct=$upstream_connect_time ' 'uht=$upstream_header_time urt=$upstream_response_time'; # Расширенный формат для детальной диагностики: log_format detailed '$remote_addr - $remote_user [$time_local] ' '"$request" $status $body_bytes_sent ' 'rt=$request_time ' 'urt="$upstream_response_time" ' 'uct="$upstream_connect_time" ' 'uht="$upstream_header_time" ' 'cs=$upstream_cache_status ' 'host=$host ' 'xff="$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main buffer=64k flush=5s; # buffer=64k — буферизация логов (не пишем на диск каждую строку) # flush=5s — сбрасываем буфер каждые 5 секунд # Для максимальной производительности — отключить access_log на статике # (настраивается в location блоках) # ===== ВКЛЮЧАЕМ ПОДКОНФИГИ ===== include /etc/nginx/conf.d/*.conf; } Уровень 4: Gzip и Brotli — сжатие ответовhttp { # ===== GZIP ===== gzip on; # Не сжимать ответы для IE6 (исторический артефакт, можно убрать) gzip_disable "msie6"; # Сжимать ответы для всех клиентов, в т.ч. через прокси # any — сжимать независимо от заголовка Via gzip_proxied any; # Уровень сжатия: 1-9 # 1 — быстро, мало сжатие (~60%) # 6 — баланс (рекомендуется для продакшена ~70%) # 9 — максимум, но тратит значительно больше CPU (~72%, но в 3-5 раз медленнее 6) gzip_comp_level 6; # Минимальный размер для сжатия (не сжимать маленькие файлы — смысла нет) gzip_min_length 1024; # Буферы для сжатия gzip_buffers 16 8k; # HTTP версия (сжимать и для HTTP/1.0 клиентов — редко нужно) gzip_http_version 1.1; # Типы контента для сжатия # text/html сжимается всегда (по умолчанию) gzip_types text/plain text/css text/xml text/javascript application/json application/javascript application/xml application/xml+rss application/x-javascript application/x-font-ttf application/vnd.ms-fontobject font/opentype image/svg+xml image/x-icon; # Добавить заголовок Vary: Accept-Encoding # Указывает прокси-серверам хранить сжатые и несжатые версии отдельно gzip_vary on; # ===== BROTLI (требует модуль ngx_brotli) ===== # Brotli на 15-25% эффективнее gzip при тех же CPU-затратах # Поддерживается всеми современными браузерами # Установка модуля (Ubuntu/Debian): # apt install libnginx-mod-http-brotli-filter # Или из исходников: https://github.com/google/ngx_brotli # load_module modules/ngx_http_brotli_filter_module.so; # load_module modules/ngx_http_brotli_static_module.so; brotli on; brotli_comp_level 6; # 0-11, 6 — хороший баланс brotli_min_length 1024; brotli_types text/plain text/css text/xml text/javascript application/json application/javascript application/xml application/xml+rss image/svg+xml; # Brotli static — отдавать предкомпрессированные .br файлы # Нужно сгенерировать: find /var/www -name "*.js" | xargs -I{} brotli {} brotli_static on; # ===== GZIP STATIC — предкомпрессированные .gz файлы ===== # Если файл app.js.gz существует — отдаём его без CPU на сжатие gzip_static on; } Предварительное сжатие статики (экономит CPU)#!/bin/bash # Скрипт для предкомпрессии статических файлов STATIC_DIR="/var/www/html" find "$STATIC_DIR" \ \( -name "*.js" -o -name "*.css" -o -name "*.html" -o -name "*.json" \ -o -name "*.xml" -o -name "*.svg" \) \ -type f | while read file; do # gzip (только если .gz не существует или файл новее) if [ ! -f "${file}.gz" ] || [ "$file" -nt "${file}.gz" ]; then gzip -9 -k "$file" fi # brotli if command -v brotli &> /dev/null; then if [ ! -f "${file}.br" ] || [ "$file" -nt "${file}.br" ]; then brotli -q 11 -k "$file" fi fi done echo "Предкомпрессия завершена: $(find $STATIC_DIR -name '*.gz' | wc -l) gz файлов" Уровень 5: Кэширование — proxy_cache и FastCGI cacheProxy Cache (для проксирования на upstream)http { # ===== ЗОНА КЭША ===== # keys_zone=cache_name:10m — зона памяти для хранения ключей # levels=1:2 — структура директорий (более эффективный поиск) # inactive=60m — удалять неиспользуемые файлы через 60 минут # max_size=10g — максимальный размер кэша на диске # use_temp_path=off — не использовать временный путь (быстрее) proxy_cache_path /var/cache/nginx/proxy levels=1:2 keys_zone=proxy_cache:50m inactive=60m max_size=10g use_temp_path=off; server { location /api/ { proxy_pass http://backend; # ===== PROXY БУФЕРЫ ===== # Буферизировать ответ от upstream в памяти # Важно: без буферизации Nginx держит соединение с upstream # пока клиент не скачает весь ответ (медленные клиенты = занятые воркеры) proxy_buffering on; # Количество и размер буферов для тела ответа # proxy_buffers × proxy_buffer_size = RAM на соединение # 32 × 16k = 512k на соединение proxy_buffers 32 16k; proxy_buffer_size 16k; # Для заголовков ответа # Если ответ не помещается в proxy_buffers — пишем во временный файл proxy_max_temp_file_size 0; # 0 = отключить (пишем всё в память) # или установить лимит: proxy_max_temp_file_size 1024m; # Буфер для занятых соединений (busy = клиент читает медленно) proxy_busy_buffers_size 64k; # ===== PROXY ТАЙМАУТЫ ===== # Таймаут установки соединения с upstream proxy_connect_timeout 5s; # Таймаут между двумя последовательными операциями чтения от upstream proxy_read_timeout 60s; # Таймаут передачи данных к upstream proxy_send_timeout 60s; # ===== ЗАГОЛОВКИ К UPSTREAM ===== proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; proxy_http_version 1.1; # HTTP/1.1 для keepalive! proxy_set_header Connection ""; # Убрать заголовок Connection для keepalive # ===== КЭШИРОВАНИЕ ===== proxy_cache proxy_cache; proxy_cache_valid 200 302 10m; # Кэшировать 200/302 на 10 минут proxy_cache_valid 404 1m; # 404 — на 1 минуту proxy_cache_valid any 30s; # Остальное — 30 секунд # Ключ кэша (что уникально идентифицирует запрос) proxy_cache_key "$scheme$request_method$host$request_uri"; # Методы для кэширования (по умолчанию только GET и HEAD) proxy_cache_methods GET HEAD; # Кэшировать ответы с заголовком Set-Cookie # (осторожно — персональные данные!) # proxy_ignore_headers Set-Cookie; # Stale cache — отдавать устаревший кэш пока upstream недоступен # Спасает от "пятистотки" при временных проблемах с бэкендом proxy_cache_use_stale error timeout updating http_500 http_502 http_503 http_504; # Блокировка одновременных запросов к upstream (coalescing) # Один запрос идёт к upstream, остальные ждут результата в кэше proxy_cache_lock on; proxy_cache_lock_timeout 5s; proxy_cache_lock_age 5s; # Фоновое обновление кэша (stale-while-revalidate) # Отдаём устаревший кэш и одновременно запускаем фоновое обновление proxy_cache_background_update on; # Добавляем заголовок X-Cache-Status для отладки add_header X-Cache-Status $upstream_cache_status always; } # ===== СТАТИКА: МАКСИМАЛЬНЫЙ КЭШ ===== location ~* \.(jpg|jpeg|png|gif|ico|svg|webp|woff|woff2|ttf|eot)$ { expires 1y; add_header Cache-Control "public, immutable, max-age=31536000"; access_log off; # Не логировать статику (экономит I/O) tcp_nodelay off; # Для больших файлов nopush важнее nodelay sendfile on; aio on; # Асинхронный I/O для больших файлов } location ~* \.(js|css)$ { expires 1y; add_header Cache-Control "public, immutable, max-age=31536000"; access_log off; } location ~* \.(html|htm)$ { expires 1h; add_header Cache-Control "public, max-age=3600, must-revalidate"; } } } FastCGI Cache (для PHP-FPM)http { # Зона FastCGI кэша fastcgi_cache_path /var/cache/nginx/fastcgi levels=1:2 keys_zone=fastcgi_cache:20m inactive=60m max_size=5g use_temp_path=off; # Глобальная переменная для определения статуса кэша map $request_method $no_cache_method { default 0; POST 1; PUT 1; DELETE 1; PATCH 1; } server { set $skip_cache 0; # Не кэшировать авторизованных пользователей (например, WordPress) if ($http_cookie ~* "wordpress_logged_in|woocommerce_cart") { set $skip_cache 1; } # Не кэшировать POST запросы if ($request_method = POST) { set $skip_cache 1; } # Не кэшировать URL с query string (можно убрать если кэш по полному URL) # if ($query_string != "") { # set $skip_cache 1; # } # Не кэшировать admin/личный кабинет if ($request_uri ~* "^/admin|^/wp-admin|^/login") { set $skip_cache 1; } location ~ \.php$ { include fastcgi_params; fastcgi_pass unix:/run/php/php8.2-fpm.sock; fastcgi_index index.php; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; # ===== FastCGI БУФЕРЫ ===== fastcgi_buffers 16 16k; fastcgi_buffer_size 32k; fastcgi_busy_buffers_size 64k; # Таймауты fastcgi_connect_timeout 5s; fastcgi_read_timeout 60s; fastcgi_send_timeout 60s; # ===== КЭШ ===== fastcgi_cache fastcgi_cache; fastcgi_cache_key "$scheme$request_method$host$request_uri"; fastcgi_cache_valid 200 5m; fastcgi_cache_valid 301 302 1m; fastcgi_cache_valid 404 30s; fastcgi_cache_bypass $skip_cache; fastcgi_no_cache $skip_cache; fastcgi_cache_use_stale error timeout updating http_500 http_503; fastcgi_cache_lock on; fastcgi_cache_background_update on; add_header X-FastCGI-Cache $upstream_cache_status; } } } Инвалидация кэша# Очистить весь кэш proxy find /var/cache/nginx/proxy -type f -delete # Очистить конкретный URL (через модуль ngx_cache_purge): # location ~ /purge(/.*) { # fastcgi_cache_purge fastcgi_cache "$scheme$request_method$host$1"; # } # curl -X PURGE http://your-server/api/products/123 # Мониторинг кэша: # X-Cache-Status значения: # HIT — ответ из кэша ✅ # MISS — кэш не нашёл, запрос к upstream # BYPASS — кэш пропущен (skip_cache = 1) # EXPIRED — кэш устарел, запрошен свежий ответ # STALE — отдан устаревший кэш (upstream недоступен) # UPDATING — отдан устаревший кэш пока фоновое обновление # REVALIDATED — кэш подтверждён (304 от upstream) Уровень 6: Upstream Keepalive и балансировкаhttp { # ===== UPSTREAM С KEEPALIVE ===== upstream backend { # Алгоритм балансировки # least_conn — меньше соединений = меньше задержка (лучше для long-poll) # ip_hash — один клиент всегда на один сервер (сессии) # По умолчанию: round-robin least_conn; server 10.0.0.10:8080 weight=3; # Тройной вес (мощнее) server 10.0.0.11:8080 weight=1; server 10.0.0.12:8080 weight=1 backup; # Резервный (включается при падении основных) # Параметры health check (требует nginx plus или upstream_check_module): # server 10.0.0.10:8080 max_fails=3 fail_timeout=30s; # ===== KEEPALIVE ПУЛА К UPSTREAM ===== # Количество keepalive соединений в пуле (на воркер!) # НЕ максимальное число соединений — это пул переиспользуемых! # Правило: (RPS / worker_count) × avg_response_time_sec × 1.5 # При 10000 RPS, 4 воркерах, 20мс ответе: 10000/4 × 0.02 × 1.5 = 75 keepalive 128; # Таймаут keepalive соединения с upstream keepalive_timeout 60s; # Максимум запросов через одно keepalive соединение к upstream keepalive_requests 10000; } server { location / { proxy_pass http://backend; # КРИТИЧЕСКИ ВАЖНО для upstream keepalive! # HTTP/1.1 поддерживает keepalive (1.0 — нет) proxy_http_version 1.1; # Убираем заголовок Connection: close (стандарт для HTTP/1.0 прокси) proxy_set_header Connection ""; } } } Уровень 7: SSL/TLS — производительность без потери безопасностиhttp { # ===== SSL СЕССИИ ===== # Кэш SSL сессий (повторное использование TLS handshake) # 1m ≈ 4000 сессий. Для highload: 50m-100m ssl_session_cache shared:SSL:50m; # Время жизни кэшированной SSL сессии ssl_session_timeout 1d; # 24 часа — максимум рекомендуемый # SSL Session Tickets (альтернатива session cache, статeful у клиента) # Для идеальной forward secrecy — отключить # Для максимальной производительности — включить ssl_session_tickets off; # Безопаснее, но чуть медленнее # ===== ПРОТОКОЛЫ И ШИФРЫ ===== # Только TLS 1.2 и 1.3 (1.0 и 1.1 — уязвимы и устарели) ssl_protocols TLSv1.2 TLSv1.3; # Шифры (Mozilla Modern конфигурация) ssl_ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384; # Сервер выбирает шифр (не клиент) — важно для безопасности ssl_prefer_server_ciphers off; # off для TLS 1.3 (там нет выбора шифра) # ===== ECDH КРИВАЯ ===== ssl_ecdh_curve X25519:prime256v1:secp384r1; # ===== STAPLING ===== # OCSP Stapling: сервер сам проверяет сертификат и включает ответ в TLS handshake # Клиенту не нужно делать отдельный запрос к CA — быстрее! ssl_stapling on; ssl_stapling_verify on; resolver 8.8.8.8 8.8.4.4 1.1.1.1 valid=300s; resolver_timeout 5s; # ===== DH параметры (для DHE шифров) ===== # Генерировать: openssl dhparam -out /etc/nginx/dhparam.pem 2048 # ssl_dhparam /etc/nginx/dhparam.pem; server { listen 443 ssl; # ===== HTTP/2 ===== # Мультиплексирование запросов — один TCP для множества запросов # Сжатие заголовков (HPACK) — экономит трафик # Server Push — отправка ресурсов до запроса (редко нужен) listen 443 ssl http2; ssl_certificate /etc/nginx/ssl/fullchain.pem; ssl_certificate_key /etc/nginx/ssl/privkey.pem; # ===== HSTS ===== # Браузер не будет делать HTTP запросы — сразу HTTPS # Включать только когда уверены что HTTPS работает корректно! add_header Strict-Transport-Security "max-age=31536000; includeSubDomains; preload" always; # ===== SECURITY ЗАГОЛОВКИ ===== add_header X-Frame-Options "SAMEORIGIN" always; add_header X-Content-Type-Options "nosniff" always; add_header X-XSS-Protection "1; mode=block" always; add_header Referrer-Policy "strict-origin-when-cross-origin" always; add_header Permissions-Policy "geolocation=(), microphone=()" always; } # Редирект HTTP → HTTPS server { listen 80; server_name example.com www.example.com; # 301 для всего кроме .well-known (Let's Encrypt) location /.well-known/acme-challenge/ { root /var/www/html; } location / { return 301 https://$host$request_uri; } } } Измерение времени TLS handshake# Проверка SSL без кэша (первое соединение) curl -w "\n=== Timing ===\nDNS: %{time_namelookup}s\nConnect: %{time_connect}s\nTLS: %{time_appconnect}s\nTTFB: %{time_starttransfer}s\nTotal: %{time_total}s\n" \ --no-keepalive -s -o /dev/null https://your-server/ # С session resumption (второе соединение) curl -w "TLS Resumption Total: %{time_total}s\n" \ --no-keepalive -s -o /dev/null https://your-server/ \ --tls-session-info # Проверка OCSP Stapling: echo QUIT | openssl s_client -connect your-server:443 -status 2>/dev/null | \ grep -A 17 'OCSP response' Уровень 8: Rate Limiting — защита и QoShttp { # ===== ЗОНЫ RATE LIMITING ===== # Ограничение по IP адресу # zone=name:10m — 10МБ памяти (~160 000 IP адресов) # rate=100r/s — 100 запросов в секунду с одного IP limit_req_zone $binary_remote_addr zone=api_limit:20m rate=100r/s; # Ограничение для авторизации (жёстче!) limit_req_zone $binary_remote_addr zone=auth_limit:10m rate=5r/m; # Ограничение по URL + IP (для конкретных эндпоинтов) limit_req_zone "$binary_remote_addr$uri" zone=upload_limit:10m rate=5r/m; # Ограничение одновременных соединений limit_conn_zone $binary_remote_addr zone=conn_limit:10m; # Лог уровень для rejected запросов (warn — не засорять error.log) limit_req_log_level warn; # Код ответа при превышении лимита (429 = Too Many Requests) limit_req_status 429; limit_conn_status 429; server { # ===== API ENDPOINT ===== location /api/ { # burst=200 — разрешить всплески до 200 запросов сверх лимита # nodelay — не задерживать burst запросы, обрабатывать немедленно # (без nodelay — запросы ставятся в очередь и задерживаются) limit_req zone=api_limit burst=200 nodelay; # Максимум 100 одновременных соединений с одного IP limit_conn conn_limit 100; proxy_pass http://backend; } # ===== АВТОРИЗАЦИЯ: СТРОГИЙ ЛИМИТ ===== location /api/auth/ { limit_req zone=auth_limit burst=10 nodelay; limit_conn conn_limit 10; proxy_pass http://backend; } # ===== ЗАГРУЗКА ФАЙЛОВ ===== location /upload/ { limit_req zone=upload_limit burst=2 nodelay; limit_conn conn_limit 5; client_max_body_size 100m; proxy_pass http://backend; } } } Белые списки для rate limitinghttp { # Карта: 0 = применять limit, 1 = пропустить geo $limit { default 1; # Ограничивать всех 10.0.0.0/8 0; # Доверенная внутренняя сеть — без ограничений 192.168.0.0/16 0; # Локальная сеть — без ограничений 1.2.3.4 0; # Конкретный IP (мониторинг, партнёры) } # Если $limit = 0 — пустой ключ, limit_req не применяется map $limit $limit_key { 0 ""; 1 $binary_remote_addr; } limit_req_zone $limit_key zone=api_limit:20m rate=100r/s; } Уровень 9: Open File Cache и другие деталиhttp { # ===== OPEN FILE CACHE ===== # Кэшировать информацию об открытых файлах: # файловые дескрипторы, размеры, время модификации, ошибки # Особенно важно при большом количестве файлов статики! # max=10000 — максимум 10000 записей в кэше # inactive=30s — удалять если не обращались 30 секунд open_file_cache max=10000 inactive=30s; # Сколько раз файл должен быть запрошен за inactive период # чтобы остаться в кэше open_file_cache_min_uses 2; # Проверять актуальность кэша каждые 60 секунд open_file_cache_valid 60s; # Кэшировать ошибки (файл не найден, нет прав) open_file_cache_errors on; # ===== SENDFILE + AIO для больших файлов ===== # Для файлов > 8MB — асинхронный I/O эффективнее aio threads; # AIO через thread pool (Nginx 1.7.11+) # или aio on; # POSIX AIO (старый вариант, хуже) directio 8m; # Файлы > 8MB: читать напрямую, минуя page cache # Полезно для больших видеофайлов которые не нужно кэшировать # ===== OUTPUT BUFFERS ===== # Размер буфера вывода (используется с sendfile) output_buffers 2 512k; # ===== ПЕРЕМЕННЫЕ ===== # Кэш переменных (для complex map и geo директив) variables_hash_max_size 2048; variables_hash_bucket_size 128; # ===== MAP HASH ===== map_hash_max_size 2048; map_hash_bucket_size 128; } Уровень 10: Полный production конфиг сервера# /etc/nginx/conf.d/example.com.conf server { listen 443 ssl http2; listen [::]:443 ssl http2; server_name example.com www.example.com; root /var/www/html; index index.html index.php; # SSL ssl_certificate /etc/letsencrypt/live/example.com/fullchain.pem; ssl_certificate_key /etc/letsencrypt/live/example.com/privkey.pem; # Логи с детальным форматом access_log /var/log/nginx/example.com.access.log detailed buffer=64k flush=5s; error_log /var/log/nginx/example.com.error.log warn; # Скрываем .git, .env и другие служебные файлы location ~ /\. { deny all; access_log off; log_not_found off; } location ~* \.(env|log|sh|sql|conf|config|bak|backup|swp|tmp)$ { deny all; } # ===== СТАТИКА: МАКСИМАЛЬНАЯ ОТДАЧА ===== location ~* \.(jpg|jpeg|png|gif|ico|svg|webp|avif|woff|woff2|ttf|eot|otf)$ { expires 1y; add_header Cache-Control "public, immutable"; add_header Vary Accept-Encoding; access_log off; log_not_found off; gzip_static on; brotli_static on; } location ~* \.(js|css|map)$ { expires 1y; add_header Cache-Control "public, immutable"; access_log off; gzip_static on; brotli_static on; } # ===== FAVICON И ROBOTS ===== location = /favicon.ico { access_log off; log_not_found off; expires 1y; } location = /robots.txt { access_log off; log_not_found off; } # ===== API ===== location /api/ { limit_req zone=api_limit burst=200 nodelay; limit_conn conn_limit 100; proxy_pass http://backend; proxy_http_version 1.1; proxy_set_header Connection ""; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; proxy_cache proxy_cache; proxy_cache_valid 200 5m; proxy_cache_valid 404 30s; proxy_cache_use_stale error timeout updating http_500 http_502 http_503 http_504; proxy_cache_lock on; proxy_cache_background_update on; add_header X-Cache-Status $upstream_cache_status always; } # ===== PHP ===== location ~ \.php$ { try_files $uri =404; fastcgi_split_path_info ^(.+\.php)(/.+)$; fastcgi_pass unix:/run/php/php8.2-fpm.sock; fastcgi_index index.php; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; include fastcgi_params; fastcgi_buffers 16 16k; fastcgi_buffer_size 32k; fastcgi_read_timeout 60s; fastcgi_cache fastcgi_cache; fastcgi_cache_valid 200 5m; fastcgi_cache_bypass $skip_cache; fastcgi_no_cache $skip_cache; fastcgi_cache_use_stale error timeout updating http_500 http_503; fastcgi_cache_lock on; add_header X-FastCGI-Cache $upstream_cache_status; } # ===== КОРЕНЬ ===== location / { try_files $uri $uri/ /index.php?$query_string; } } Диагностика и мониторинг в продакшенеStub Status модульserver { listen 127.0.0.1:8080; location /nginx_status { stub_status; allow 127.0.0.1; allow 10.0.0.0/8; # Сеть мониторинга deny all; } } # Парсинг nginx_status: curl -s http://127.0.0.1:8080/nginx_status # Active connections: 1247 # server accepts handled requests # 87354291 87354291 245912847 # Reading: 12 Writing: 847 Waiting: 388 # Интерпретация: # Active = Reading + Writing + Waiting # Waiting = keepalive соединения (ждут следующего запроса) # Writing = активно пишем ответ клиенту # Reading = читаем запрос от клиента # Если Waiting >> Writing — много keepalive соединений, это нормально # Если Reading >> 0 постоянно — клиенты медленно отправляют запросы # Если Writing = worker_processes × worker_connections — всё занято! # accepts == handled — нет dropped connections. Если differs — проблема! Анализ логов# Медленные запросы (> 1 секунды) awk '$NF > 1' /var/log/nginx/access.log | \ awk '{print $NF, $7}' | sort -rn | head -20 # HIT rate кэша grep -o 'cs=[A-Z]*' /var/log/nginx/access.log | \ sort | uniq -c | sort -rn # 94521 cs=HIT ← 87% HIT rate — хорошо! # 12305 cs=MISS # 1823 cs=BYPASS # 289 cs=EXPIRED # Ошибки upstream grep 'upstream timed out\|connect() failed\|upstream prematurely' \ /var/log/nginx/error.log | tail -50 # Топ 5xx ошибок awk '$9 ~ /^5/' /var/log/nginx/access.log | \ awk '{print $9, $7}' | sort | uniq -c | sort -rn | head -20 Чеклист тюнинга: финальная проверка#!/bin/bash # Быстрая проверка ключевых параметров echo "=== NGINX PERFORMANCE CHECKLIST ===" # 1. Worker processes WP=$(nginx -T 2>/dev/null | grep 'worker_processes' | tail -1 | awk '{print $2}') CORES=$(nproc) echo "Worker processes: $WP (cores: $CORES)" # 2. Worker connections WC=$(nginx -T 2>/dev/null | grep 'worker_connections' | tail -1 | awk '{print $2}') echo "Worker connections: $WC" # 3. File descriptors FD=$(cat /proc/$(cat /var/run/nginx.pid 2>/dev/null || echo 1)/limits \ 2>/dev/null | grep 'open files' | awk '{print $4}') echo "File descriptors limit: $FD" # 4. sendfile SF=$(nginx -T 2>/dev/null | grep -E '^\s+sendfile' | tail -1) echo "Sendfile: $SF" # 5. gzip GZ=$(nginx -T 2>/dev/null | grep -E '^\s+gzip ' | tail -1) echo "Gzip: $GZ" # 6. SSL session cache SSL=$(nginx -T 2>/dev/null | grep 'ssl_session_cache' | tail -1) echo "SSL session cache: $SSL" # 7. BBR echo "TCP congestion: $(sysctl -n net.ipv4.tcp_congestion_control)" # 8. Тест конфигурации nginx -t && echo "Config: OK" || echo "Config: ERROR!" echo "" echo "=== ТЕКУЩАЯ НАГРУЗКА ===" curl -s http://127.0.0.1:8080/nginx_status 2>/dev/null || echo "stub_status недоступен" Типичные ошибки и мифыМиф 1: "worker_processes 4096 увеличит производительность" Нет. Оптимум — по одному воркеру на ядро. Больше воркеров = больше переключений контекста = хуже. Миф 2: "worker_connections 65535 — максимум соединений" Нет. Это максимум на один воркер. Итого: worker_processes × worker_connections. При 4 воркерах и 10240 соединениях = 40960 одновременных соединений. Миф 3: "keepalive_timeout 0 ускорит сервер" Наоборот. Keepalive экономит TLS handshake и TCP установку соединения. Отключение keepalive нагрузит сервер больше. Миф 4: "gzip_comp_level 9 — лучше" Нет. Разница в размере между уровнями 6 и 9 — 1-3%. Разница в CPU — в 3-5 раз. Используйте gzip_comp_level 6. Ошибка: proxy_cache без proxy_cache_use_stale При недоступности upstream без use_stale клиенты получат 502. С use_stale error timeout — получат устаревший кэш пока upstream восстанавливается. Всегда включайте! Ошибка: не настроен upstream keepalive Без keepalive в блоке upstream каждый запрос создаёт новое TCP соединение к backend. При 1000 RPS — 1000 новых TCP handshake в секунду. С keepalive 64 — переиспользуются 64 соединения. ЗаключениеТюнинг Nginx — это итеративный процесс. Хороший порядок: Системный уровень: sysctl, ulimit, BBR — без этого упрётесь в ОС Workers и events: worker_processes auto, multi_accept on, epoll Буферы и таймауты: адаптируйте под характер трафика (размер ответов, скорость клиентов) Кэш: proxy_cache или fastcgi_cache — самый большой прирост производительности Upstream keepalive: критично для высоких RPS SSL оптимизация: session cache + stapling + HTTP/2 Сжатие: gzip + brotli_static для предкомпрессии Rate limiting: защита без ущерба для легитимного трафика Измеряйте до и после каждого изменения. Доверяйте цифрам, а не интуиции. И помните: лучший тюнинг — тот, который решает вашу конкретную проблему, а не скопированный из статьи. -
 Введение: PostgreSQL в продакшене — другой зверьПоднять PostgreSQL локально — просто. Запустить его в продакшене под реальной нагрузкой так, чтобы он не падал, не тормозил и не раздувался до потери диска — это уже инженерия. PostgreSQL 16, 17 и 18 принесли серьёзные улучшения производительности: логическая репликация стала намного мощнее, параллельные запросы умнее, планировщик научился большему. Но дефолтная конфигурация по-прежнему рассчитана на «запустить на ноутбуке с 256 МБ RAM», а не на production-сервер с 128 ГБ памяти. Эта статья — системный разбор всего, что нужно сделать, чтобы PostgreSQL работал быстро, надёжно и предсказуемо. Никакой воды: только параметры, SQL, реальные кейсы. Глава 1. Конфигурация: postgresql.conf с нуляПамять: самые важные параметры# postgresql.conf # shared_buffers — основной кэш PostgreSQL в памяти. # Правило: 25-40% от RAM сервера. # На 64 ГБ RAM: 16 ГБ shared_buffers = 16GB # effective_cache_size — подсказка планировщику, сколько памяти # доступно для кэширования (shared_buffers + OS page cache). # Правило: 50-75% от RAM. # На 64 ГБ RAM: 48 ГБ effective_cache_size = 48GB # work_mem — память для одной операции сортировки/хэширования # ВНИМАНИЕ: умножается на число параллельных запросов × число операций в плане! # На сервере с 500 соединениями и work_mem=256MB → потенциально 128 ГБ! # Разумно: 4-64 МБ для OLTP, 256 МБ-1 ГБ для аналитики work_mem = 32MB # maintenance_work_mem — для VACUUM, CREATE INDEX, ALTER TABLE # Больше = быстрее индексы и вакуум. Безопасно давать больше, чем work_mem. maintenance_work_mem = 2GB # huge_pages — используем hugepages Linux для shared_buffers # Обязательно для shared_buffers > 8 ГБ huge_pages = on WAL и checkpoint: баланс между скоростью и надёжностью# wal_level — минимальный уровень для репликации # replica — для физической репликации # logical — для логической репликации (больше overhead) wal_level = replica # Размер WAL буфера (с PostgreSQL 16 wal_buffers=auto работает хорошо) wal_buffers = 64MB # checkpoint_completion_target — размазываем запись checkpoint во времени # 0.9 означает: записать грязные страницы за 90% интервала между checkpoint checkpoint_completion_target = 0.9 # max_wal_size — максимальный объём WAL между checkpoint # При большой нагрузке на запись увеличьте до 4-16 ГБ # Это НЕ размер хранилища WAL, а порог для инициации checkpoint max_wal_size = 4GB # min_wal_size — минимальный резерв WAL файлов min_wal_size = 1GB # wal_compression — сжатие WAL (PostgreSQL 15+: поддержка lz4, zstd) # Снижает I/O, небольшой CPU overhead wal_compression = lz4 Параллелизм (PostgreSQL 16+)# max_worker_processes — общий пул фоновых процессов max_worker_processes = 16 # max_parallel_workers_per_gather — параллельные воркеры на один запрос # Правило: не более числа физических ядер / 2 max_parallel_workers_per_gather = 4 # max_parallel_workers — суммарно параллельных воркеров max_parallel_workers = 8 # max_parallel_maintenance_workers — для CREATE INDEX CONCURRENTLY, VACUUM max_parallel_maintenance_workers = 4 # parallel_tuple_cost, parallel_setup_cost — влияют на решение планировщика # использовать параллельность. Снизить если параллельные планы не строятся. parallel_tuple_cost = 0.1 parallel_setup_cost = 100 Соединения# max_connections — ОСТОРОЖНО! Каждое соединение ≈ 5-10 МБ памяти. # При PgBouncer: достаточно 100-200 серверных соединений. # Без пула: реальное число ≤ 200-300 max_connections = 200 # superuser_reserved_connections — резерв для DBA superuser_reserved_connections = 5 Планировщик: тонкая настройка# random_page_cost — стоимость случайного чтения страницы. # Для SSD: 1.1-1.5 (против дефолта 4.0 для HDD). # Занижение → планировщик чаще выбирает Index Scan. random_page_cost = 1.1 # seq_page_cost — стоимость последовательного чтения (база = 1.0) seq_page_cost = 1.0 # effective_io_concurrency — параллельных I/O для Bitmap Heap Scan # SSD: 200-300, HDD: 2-4, NVMe: 500+ effective_io_concurrency = 200 # default_statistics_target — точность статистики для планировщика # Дефолт 100. Для колонок с высокой кардинальностью — до 500. default_statistics_target = 200 # enable_partitionwise_join — важно для партиционированных таблиц enable_partitionwise_join = on enable_partitionwise_aggregate = on Глава 2. Индексная стратегияПравильные индексы — половина успеха. Неправильные — гарантированный bloat и тормоза на INSERT/UPDATE. Типы индексов: когда что использоватьB-Tree — дефолт, для равенства и диапазонов: -- Стандартный случай CREATE INDEX idx_orders_user_id ON orders(user_id); -- Частичный индекс — только активные записи -- Занимает меньше места, быстрее обновляется CREATE INDEX idx_orders_active ON orders(created_at) WHERE status = 'active'; -- Покрывающий индекс (INCLUDE) — избегаем обращения к таблице -- PostgreSQL 11+, активно улучшен в 16/17 CREATE INDEX idx_orders_cover ON orders(user_id) INCLUDE (total_amount, status, created_at); -- Составной: порядок имеет значение! -- Ставьте впереди колонки с высокой кардинальностью -- и те, по которым фильтрация точнее CREATE INDEX idx_orders_composite ON orders(user_id, status, created_at); GIN — для массивов, JSONB, полнотекстового поиска: -- JSONB поиск CREATE INDEX idx_products_attrs ON products USING GIN(attributes); -- Полнотекстовый поиск CREATE INDEX idx_articles_fts ON articles USING GIN(to_tsvector('russian', title || ' ' || body)); -- Поиск в массивах CREATE INDEX idx_tags ON posts USING GIN(tags); BRIN — для очень больших таблиц с естественной сортировкой: -- Для таблиц логов, временных рядов — экономия места 99%+ -- BRIN не хранит каждое значение, только мин/макс по блокам CREATE INDEX idx_events_time_brin ON events USING BRIN(created_at) WITH (pages_per_range = 128); -- PostgreSQL 14+: bloom filter в BRIN CREATE INDEX idx_events_bloom ON events USING BRIN(device_id, created_at) WITH (pages_per_range = 64); Hash — только для точного равенства, быстрее B-Tree: CREATE INDEX idx_sessions_token ON sessions USING HASH(session_token); Найти неиспользуемые и дублирующие индексы-- Неиспользуемые индексы (кандидаты на удаление) SELECT schemaname, tablename, indexname, pg_size_pretty(pg_relation_size(indexrelid)) AS index_size, idx_scan, idx_tup_read, idx_tup_fetch FROM pg_stat_user_indexes WHERE idx_scan = 0 AND indexrelname NOT LIKE 'pg_%' ORDER BY pg_relation_size(indexrelid) DESC; -- Дублирующие индексы SELECT indrelid::regclass AS table_name, array_agg(indexrelid::regclass) AS indexes, array_agg(indkey) AS index_keys FROM pg_index GROUP BY indrelid, indkey HAVING count(*) > 1; -- Индексы vs размер таблицы: раздутые индексы SELECT t.tablename, pg_size_pretty(pg_total_relation_size(t.tablename::regclass)) AS total, pg_size_pretty(pg_relation_size(t.tablename::regclass)) AS table_size, pg_size_pretty( pg_total_relation_size(t.tablename::regclass) - pg_relation_size(t.tablename::regclass) ) AS indexes_size, round( (pg_total_relation_size(t.tablename::regclass) - pg_relation_size(t.tablename::regclass))::numeric / nullif(pg_total_relation_size(t.tablename::regclass), 0) * 100, 1 ) AS index_ratio_pct FROM pg_tables t WHERE t.schemaname = 'public' ORDER BY pg_total_relation_size(t.tablename::regclass) DESC LIMIT 30; Глава 3. EXPLAIN ANALYZE: читаем план запроса как профессионалEXPLAIN ANALYZE — главный инструмент оптимизации. Без него — гадание на кофейной гуще. -- Всегда используйте все опции EXPLAIN ( ANALYZE, -- Реально выполнить и показать время BUFFERS, -- Показать попадания/промахи кэша FORMAT TEXT, -- или JSON для авто-анализа TIMING ON, -- Время каждого узла SETTINGS ON, -- Показать изменённые параметры WAL ON -- PostgreSQL 13+: WAL активность ) SELECT ...; Анатомия плана: на что смотретьEXPLAIN (ANALYZE, BUFFERS) SELECT o.id, o.total, u.email FROM orders o JOIN users u ON u.id = o.user_id WHERE o.created_at > NOW() - INTERVAL '7 days' AND o.status = 'completed'; -- Типичный вывод: -- QUERY PLAN -- Hash Join (cost=1250.00..8934.21 rows=1523 width=48) (actual time=45.231..189.443 rows=1287 loops=1) -- Buffers: shared hit=4521 read=2341 ← read > 0 = данных нет в кэше -- Hash Cond: (o.user_id = u.id) -- -> Bitmap Heap Scan on orders o (cost=87.3..7512.4 rows=1523 width=32) -- (actual time=2.341..145.231 rows=1287 loops=1) -- Recheck Cond: (created_at > (now() - '7 days'::interval)) -- Filter: (status = 'completed') -- Rows Removed by Filter: 4521 ← КРАСНЫЙ ФЛАГ: фильтруем 4521 строк! -- Heap Blocks: exact=1823 -- Buffers: shared hit=123 read=1823 -- -> Bitmap Index Scan on idx_orders_created_at -- Index Cond: (created_at > (now() - '7 days'::interval)) -- -> Hash (cost=890.00..890.00 rows=21000 width=24) (actual time=42.3..42.3 rows=21000 loops=1) -- Buckets: 32768 Batches: 1 Memory Usage: 1856kB -- Buffers: shared hit=4398 read=518 -- -> Seq Scan on users u (cost=0.00..890.00 rows=21000 width=24) -- Planning Time: 1.234 ms -- Execution Time: 190.123 ms ← Реальное время! Красные флаги в плане: Признак Проблема Решение Rows Removed by Filter >> возвращаемых строк Индекс не покрывает все условия Добавить колонку status в индекс actual rows >> estimated rows (×10+) Устаревшая статистика ANALYZE table или повысить default_statistics_target Seq Scan на большой таблице Нет подходящего индекса Создать индекс Batches: N (N > 1) в Hash Join Хэш-таблица не помещается в work_mem Увеличить work_mem или оптимизировать запрос loops=N при N×cost = огромно Вложенный цикл на большом наборе Рассмотреть Hash Join / Merge Join shared read >> shared hit Данные не в кэше Увеличить shared_buffers или прогреть кэш Автоматический поиск медленных запросов-- pg_stat_statements: топ-20 самых дорогих запросов -- Требует: shared_preload_libraries = 'pg_stat_statements' -- postgresql.conf: pg_stat_statements.track = all SELECT round(total_exec_time::numeric, 2) AS total_ms, calls, round(mean_exec_time::numeric, 2) AS mean_ms, round(stddev_exec_time::numeric, 2) AS stddev_ms, round((total_exec_time / sum(total_exec_time) OVER () * 100)::numeric, 2) AS pct_total, round(rows::numeric / calls, 1) AS avg_rows, -- Соотношение кэш-попаданий round( 100.0 * shared_blks_hit / nullif(shared_blks_hit + shared_blks_read, 0), 2 ) AS cache_hit_pct, -- Нормализованный текст запроса (без значений параметров) left(query, 100) AS query_snippet FROM pg_stat_statements WHERE calls > 10 ORDER BY total_exec_time DESC LIMIT 20; -- Запросы с самым высоким среднем временем (не суммарным!) SELECT calls, round(mean_exec_time::numeric, 2) AS mean_ms, round(max_exec_time::numeric, 2) AS max_ms, round(stddev_exec_time::numeric, 2) AS stddev_ms, left(query, 120) AS query FROM pg_stat_statements WHERE calls > 5 AND mean_exec_time > 100 -- Больше 100 мс в среднем ORDER BY mean_exec_time DESC LIMIT 20; -- Запросы с плохим cache hit ratio (много disk reads) SELECT calls, round(mean_exec_time::numeric, 2) AS mean_ms, shared_blks_read, shared_blks_hit, round(100.0 * shared_blks_hit / nullif(shared_blks_hit + shared_blks_read, 0), 2) AS cache_hit_pct, left(query, 120) AS query FROM pg_stat_statements WHERE calls > 10 AND (shared_blks_hit + shared_blks_read) > 0 AND shared_blks_read > shared_blks_hit -- Больше промахов чем попаданий ORDER BY shared_blks_read DESC LIMIT 20; Глава 4. Autovacuum: настройка, а не молитваAutovacuum — не враг, а друг. Но дефолтные настройки рассчитаны на небольшие таблицы. На больших таблицах он либо не успевает, либо тормозит рабочую нагрузку. Понять текущее состояние vacuum-- Таблицы с наибольшим dead tuple bloat SELECT schemaname, relname AS tablename, n_live_tup, n_dead_tup, round(n_dead_tup::numeric / nullif(n_live_tup + n_dead_tup, 0) * 100, 2) AS dead_pct, last_vacuum, last_autovacuum, last_analyze, last_autoanalyze, autovacuum_count, pg_size_pretty(pg_total_relation_size(schemaname||'.'||relname)) AS total_size FROM pg_stat_user_tables WHERE n_dead_tup > 1000 ORDER BY n_dead_tup DESC LIMIT 20; -- Таблицы, которым скоро нужен vacuum (по счётчику транзакций) -- age() показывает сколько транзакций прошло с последнего freeze SELECT schemaname, relname, pg_size_pretty(pg_total_relation_size(oid)) AS size, age(relfrozenxid) AS xid_age, round(age(relfrozenxid)::numeric / 2000000000 * 100, 2) AS freeze_pct, -- Когда автовакуум сделает freeze (по умолчанию при 150M транзакций) (200000000 - age(relfrozenxid)) AS txids_until_freeze FROM pg_class JOIN pg_namespace ON pg_namespace.oid = pg_class.relnamespace WHERE relkind = 'r' AND nspname NOT IN ('pg_catalog', 'information_schema') ORDER BY age(relfrozenxid) DESC LIMIT 20; -- Текущие процессы autovacuum SELECT pid, now() - xact_start AS duration, query, state, wait_event_type, wait_event FROM pg_stat_activity WHERE query LIKE 'autovacuum:%' ORDER BY duration DESC; Оптимальная настройка autovacuum# postgresql.conf — глобальные настройки autovacuum # Число процессов autovacuum autovacuum_max_workers = 6 # Дефолт 3; на активном сервере — 4-8 # Стоимостной лимит для autovacuum (throttling) # Дефолт 200 — очень агрессивное ограничение скорости. # На SSD можно поднять до 800-2000. autovacuum_vacuum_cost_limit = 800 # Задержка между "порциями" vacuum (cooldown) # При cost_limit=800 и delay=2ms → ~400 МБ/с максимальная скорость vacuum autovacuum_vacuum_cost_delay = 2ms # Порог запуска VACUUM: n_dead_tup > autovacuum_vacuum_threshold + n_live_tup * scale_factor autovacuum_vacuum_threshold = 50 autovacuum_vacuum_scale_factor = 0.02 # 2% от таблицы (дефолт 20%) # Порог запуска ANALYZE autovacuum_analyze_threshold = 50 autovacuum_analyze_scale_factor = 0.01 # 1% (дефолт 20%) # Для больших таблиц scale_factor делает vacuum очень редким: # Таблица 100M строк × 0.02 = 2M dead tuples до запуска vacuum — МНОГО Настройка per-table (лучше глобальных для горячих таблиц):-- Для высокоактивных таблиц: vacuum чаще, агрессивнее ALTER TABLE orders SET ( autovacuum_vacuum_scale_factor = 0.005, -- Запуск при 0.5% dead tuples autovacuum_analyze_scale_factor = 0.002, -- Analyze при 0.2% autovacuum_vacuum_cost_limit = 1600, -- Более высокий лимит I/O autovacuum_vacuum_cost_delay = 1 -- Меньше пауз ); -- Для append-only таблиц (логи, временные ряды): -- Vacuum не нужен часто, но freeze — важен ALTER TABLE event_log SET ( autovacuum_vacuum_scale_factor = 0.2, -- Редкий vacuum (мало UPDATE/DELETE) autovacuum_freeze_max_age = 500000000, -- Freeze через 500M транзакций autovacuum_vacuum_cost_limit = 2000 -- Быстрый когда запустился ); -- Проверить что настройки применились: SELECT relname, reloptions FROM pg_class WHERE relname IN ('orders', 'event_log'); Обнаружение table bloat (раздутых таблиц)-- Скрипт оценки bloat (не требует сторонних расширений) WITH constants AS ( SELECT current_setting('block_size')::numeric AS bs, 23 AS hdr, 8 AS ma ), columns_per_table AS ( SELECT att.attrelid, count(*) AS cols, -- Байт nullmap на строку (count(*) + 7) / 8 AS nullhdr FROM pg_attribute att WHERE att.attnum > 0 AND NOT att.attisdropped GROUP BY 1 ), rows_estimate AS ( SELECT c.oid, CASE WHEN c.reltuples < 0 THEN 0 ELSE c.reltuples END AS est_rows, c.relpages, c.relname, n.nspname FROM pg_class c JOIN pg_namespace n ON n.oid = c.relnamespace WHERE c.relkind = 'r' AND n.nspname NOT IN ('pg_catalog', 'information_schema') ) SELECT re.nspname || '.' || re.relname AS table_name, re.est_rows, re.relpages AS current_pages, pg_size_pretty(re.relpages * 8192) AS current_size, -- Оценочный реальный размер pg_size_pretty( ceil(re.est_rows * 30 / 8192.0)::bigint * 8192 ) AS estimated_real_size, round( 100.0 * (re.relpages - ceil(re.est_rows * 30 / 8192.0)) / nullif(re.relpages, 0), 1 ) AS bloat_pct FROM rows_estimate re WHERE re.relpages > 100 ORDER BY (re.relpages - ceil(re.est_rows * 30 / 8192.0)) DESC LIMIT 20; -- Для точного bloat используйте расширение pgstattuple: -- CREATE EXTENSION pgstattuple; SELECT * FROM pgstattuple('orders'); -- Поля: table_len, live_tuple_count, dead_tuple_count, dead_tuple_percent, free_space Глава 5. Connection Pooling с PgBouncerКаждое соединение с PostgreSQL — это отдельный процесс (~5 МБ памяти + overhead планировщика). 1000 соединений = 5 ГБ памяти только на процессы. PgBouncer решает эту проблему. Режимы PgBouncerРежим Как работает Подходит для Ограничения session 1 клиент = 1 серверное соединение на всю сессию Совместимость Нет экономии transaction Серверное соединение занято только на время транзакции OLTP, большинство приложений SET, LISTEN, prepared statements statement Одно серверное соединение на один SQL-оператор Агрессивная экономия Нет транзакций! Конфигурация PgBouncer# /etc/pgbouncer/pgbouncer.ini [databases] # Синтаксис: alias = host=... dbname=... port=... user=... myapp = host=127.0.0.1 port=5432 dbname=myapp_db # Для чтения — отдельный пул на реплику myapp_ro = host=replica.internal port=5432 dbname=myapp_db [pgbouncer] # Режим пула pool_mode = transaction # Адрес и порт PgBouncer listen_addr = 0.0.0.0 listen_port = 5432 # Максимум клиентских соединений (к PgBouncer) max_client_conn = 2000 # Размер серверного пула на базу (к PostgreSQL) # PostgreSQL: max_connections = 200 # PgBouncer: default_pool_size = 80 (на каждую базу) default_pool_size = 80 # Минимальный пул (держим готовые соединения) min_pool_size = 10 # Резерв для суперпользователя (аналог reserved_connections) reserve_pool_size = 5 reserve_pool_timeout = 3 # Таймауты server_idle_timeout = 600 # Закрыть серверное соединение через 10 мин idle client_idle_timeout = 0 # Не закрывать клиентские (0 = infinite) server_connect_timeout = 5 # Таймаут подключения к PostgreSQL query_timeout = 0 # 0 = нет лимита на запрос (лучше ставить в app) query_wait_timeout = 120 # Ждать свободного соединения до 120 с # Проверка соединений server_check_query = select 1 server_check_delay = 30 # Аутентификация (scram-sha-256 — стандарт PG 14+) auth_type = scram-sha-256 auth_file = /etc/pgbouncer/userlist.txt # Логирование (не слишком подробное — влияет на производительность) log_connections = 0 log_disconnections = 0 log_pooler_errors = 1 # Admin интерфейс admin_users = pgbouncer_admin stats_users = monitoring_user # Производительность tcp_keepalive = 1 tcp_keepidle = 60 tcp_keepintvl = 10 tcp_keepcnt = 5 Мониторинг PgBouncer-- Подключиться к admin БД PgBouncer: -- psql -h localhost -p 5432 -U pgbouncer_admin pgbouncer -- Состояние пулов SHOW POOLS; -- cl_active — клиентов с активным серверным соединением -- cl_waiting — клиентов в очереди (ждут свободного соединения!) -- sv_active — серверных соединений в работе -- sv_idle — серверных соединений в ожидании (пул) -- sv_used — только что освобождённые (не проверены ещё) -- maxwait — максимальное время ожидания клиента (критический параметр!) -- Статистика SHOW STATS; -- total_query_time — суммарное время выполнения запросов -- avg_query_time — среднее время запроса -- total_wait_time — суммарное время ожидания в очереди -- Список клиентов SHOW CLIENTS; -- Перезагрузить конфиг без перезапуска RELOAD; -- Сбросить статистику RESET STATS; Интеграция с PostgreSQL 17: встроенный connection shardPostgreSQL 17 улучшил max_connections по производительности и добавил механизм connection_obeys_lc_messages — мелочь, но полезная. Работа над встроенным пулингом (connection pooling) ведётся активно, следите за PostgreSQL 18. Глава 6. Партиционирование: когда таблица растёт до сотен ГБПартиционирование делит одну логическую таблицу на несколько физических. PostgreSQL 16/17 значительно улучшили работу с партициями: умный pruning, параллельные операции, partition-wise joins. RANGE партиционирование (самое частое — по дате)-- Создание партиционированной таблицы CREATE TABLE events ( id BIGSERIAL, created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(), device_id INT NOT NULL, event_type TEXT NOT NULL, payload JSONB, PRIMARY KEY (id, created_at) -- created_at обязательна в PK для партиций! ) PARTITION BY RANGE (created_at); -- Создание партиций (вручную или автоматически) CREATE TABLE events_2024_01 PARTITION OF events FOR VALUES FROM ('2024-01-01') TO ('2024-02-01'); CREATE TABLE events_2024_02 PARTITION OF events FOR VALUES FROM ('2024-02-01') TO ('2024-03-01'); -- DEFAULT партиция для данных вне диапазона CREATE TABLE events_default PARTITION OF events DEFAULT; -- Индексы создаются на каждой партиции отдельно -- (или глобально через CREATE INDEX на родительской — PG 11+) CREATE INDEX idx_events_device ON events(device_id, created_at); -- Автоматически создаст индекс на каждой партиции! Автоматическое создание партиций (pg_partman)Ручное создание партиций — путь к ошибкам. Используйте pg_partman: -- Установка pg_partman -- Добавить в postgresql.conf: shared_preload_libraries = 'pg_partman_bgw' -- Настройка автоматического управления партициями SELECT partman.create_parent( p_parent_table => 'public.events', p_control => 'created_at', p_interval => 'monthly', -- или 'weekly', 'daily', 'yearly' p_premake => 3, -- Создавать 3 будущих партиции заранее p_start_partition => '2024-01-01' ); -- Настройка retention (удаление старых партиций) UPDATE partman.part_config SET retention = '12 months', -- Хранить 12 месяцев retention_keep_table = false, -- Удалять партицию физически retention_keep_index = false -- Удалять и индексы WHERE parent_table = 'public.events'; -- Запуск обслуживания вручную (обычно pg_partman_bgw делает это сам) CALL partman.run_maintenance_proc(); Partition Pruning: проверяем что планировщик умный-- Планировщик должен сканировать только нужные партиции EXPLAIN SELECT count(*) FROM events WHERE created_at BETWEEN '2024-03-01' AND '2024-03-31'; -- Ищем в плане: "Partitions: events_2024_03" -- НЕ должно быть: "Append (всех партиций)" -- Если pruning не работает — проверьте что условие на колонку партиционирования -- и её тип совпадают (нет неявных каст) -- Partition pruning во время выполнения (runtime pruning, PG 11+) -- Работает даже для параметров ($1, $2) если enable_partition_pruning = on SET enable_partition_pruning = on; -- Дефолт on в PG 16+ LIST партиционирование (по типу/региону)CREATE TABLE orders ( id BIGSERIAL, region TEXT NOT NULL, created_at TIMESTAMPTZ DEFAULT NOW(), total DECIMAL(10,2) ) PARTITION BY LIST (region); CREATE TABLE orders_eu PARTITION OF orders FOR VALUES IN ('DE', 'FR', 'NL', 'PL'); CREATE TABLE orders_us PARTITION OF orders FOR VALUES IN ('US', 'CA', 'MX'); CREATE TABLE orders_asia PARTITION OF orders FOR VALUES IN ('CN', 'JP', 'KR', 'IN'); CREATE TABLE orders_rest PARTITION OF orders DEFAULT; HASH партиционирование (равномерное распределение)-- Для таблиц без естественного ключа партиционирования -- Гарантирует примерно равный размер партиций CREATE TABLE sessions ( id UUID DEFAULT gen_random_uuid(), user_id INT NOT NULL, data JSONB ) PARTITION BY HASH (user_id); -- Создаём N партиций (степень двойки — хорошая практика) CREATE TABLE sessions_0 PARTITION OF sessions FOR VALUES WITH (MODULUS 8, REMAINDER 0); CREATE TABLE sessions_1 PARTITION OF sessions FOR VALUES WITH (MODULUS 8, REMAINDER 1); -- ... и т.д. до sessions_7 Глава 7. Репликация: PostgreSQL 16/17/18Физическая репликация (Streaming Replication)# На Primary: postgresql.conf wal_level = replica max_wal_senders = 10 # Максимум одновременных реплик wal_keep_size = 1GB # Буфер WAL для реплик (PG 13+, заменил wal_keep_segments) hot_standby = on # Разрешить запросы на реплике hot_standby_feedback = on # Реплика сообщает Primary о своих транзакциях # pg_hba.conf на Primary — разрешаем репликацию с адреса реплики: # host replication replicator 10.0.0.2/32 scram-sha-256 # На Standby: создание базовой копии pg_basebackup \ -h primary.host \ -U replicator \ -D /var/lib/postgresql/17/main \ -P \ --wal-method=stream \ --checkpoint=fast \ --write-recovery-conf # Создаёт standby.signal и postgresql.auto.conf # postgresql.auto.conf на Standby (создаётся pg_basebackup): # primary_conninfo = 'host=primary.host port=5432 user=replicator password=...' -- Мониторинг репликации на Primary: SELECT client_addr, usename, application_name, state, sent_lsn, write_lsn, flush_lsn, replay_lsn, -- Лаг в байтах pg_wal_lsn_diff(sent_lsn, replay_lsn) AS replay_lag_bytes, -- Лаг во времени (PG 10+) write_lag, flush_lag, replay_lag, sync_state FROM pg_stat_replication ORDER BY replay_lag DESC; -- На Standby — проверка своего лага: SELECT now() - pg_last_xact_replay_timestamp() AS replication_lag, pg_is_in_recovery() AS is_replica, pg_last_wal_receive_lsn() AS received_lsn, pg_last_wal_replay_lsn() AS replayed_lsn; Логическая репликация (PostgreSQL 16/17: серьёзно улучшена)Логическая репликация в PostgreSQL 16 получила: Двунаправленная (bidirectional) репликация — обе стороны могут принимать запись Streaming больших транзакций в реальном времени (без ожидания COMMIT) Параллельное применение изменений на подписчике -- На Publisher (источник): -- postgresql.conf: wal_level = logical -- Создание публикации CREATE PUBLICATION my_pub FOR TABLE orders, users, products WITH (publish = 'insert, update, delete', publish_via_partition_root = true); -- Для всех таблиц: CREATE PUBLICATION all_tables FOR ALL TABLES; -- На Subscriber (назначение): -- Создание подписки CREATE SUBSCRIPTION my_sub CONNECTION 'host=primary.host port=5432 dbname=mydb user=replicator password=secret' PUBLICATION my_pub WITH ( connect = true, slot_name = 'my_sub_slot', synchronous_commit = 'off', -- Более быстрая репликация streaming = on -- PG 14+: stream больших транзакций ); -- Мониторинг логической репликации на Publisher: SELECT slot_name, plugin, slot_type, database, active, active_pid, -- КРИТИЧНО: wal_status = 'lost' означает что слот отстал и WAL удалён wal_status, pg_size_pretty(pg_wal_lsn_diff(pg_current_wal_lsn(), confirmed_flush_lsn)) AS subscriber_lag FROM pg_replication_slots; -- ОПАСНОСТЬ: неактивный logical slot держит WAL! Диск кончится. -- Если слот не используется > 24ч — проверить и при необходимости удалить: -- SELECT pg_drop_replication_slot('my_sub_slot'); Глава 8. Мониторинг: что смотреть в продакшенеСистемные вьюшки — источник правды-- ===== АКТИВНЫЕ ЗАПРОСЫ И БЛОКИРОВКИ ===== -- Запросы дольше 30 секунд — потенциальные проблемы SELECT pid, now() - pg_stat_activity.query_start AS duration, query, state, wait_event_type, wait_event, client_addr, usename, application_name FROM pg_stat_activity WHERE (now() - pg_stat_activity.query_start) > INTERVAL '30 seconds' AND state != 'idle' ORDER BY duration DESC; -- Граф блокировок: кто кого блокирует WITH RECURSIVE lock_graph AS ( -- Базовый случай: запросы, ожидающие блокировку SELECT blocked.pid AS blocked_pid, blocked.query AS blocked_query, blocked.query_start AS blocked_start, blocker.pid AS blocker_pid, blocker.query AS blocker_query, 0 AS depth FROM pg_stat_activity blocked JOIN pg_stat_activity blocker ON blocker.pid = ANY(pg_blocking_pids(blocked.pid)) WHERE blocked.wait_event_type = 'Lock' UNION ALL -- Рекурсивный случай: цепочки блокировок SELECT lg.blocked_pid, lg.blocked_query, lg.blocked_start, blocker.pid, blocker.query, lg.depth + 1 FROM lock_graph lg JOIN pg_stat_activity blocker ON blocker.pid = ANY(pg_blocking_pids(lg.blocker_pid)) WHERE lg.depth < 10 ) SELECT blocked_pid, left(blocked_query, 80) AS blocked_query, now() - blocked_start AS wait_duration, blocker_pid, left(blocker_query, 80) AS blocker_query, depth FROM lock_graph ORDER BY wait_duration DESC; -- Если нужно убить зависший запрос (мягко): -- SELECT pg_cancel_backend(pid); -- Отмена запроса, транзакция откатывается -- Если не реагирует (жёстко): -- SELECT pg_terminate_backend(pid); -- Завершение процесса -- ===== КЭШ И I/O ===== -- Cache hit ratio (цель: > 99%) SELECT sum(heap_blks_hit) AS heap_hit, sum(heap_blks_read) AS heap_read, round( sum(heap_blks_hit)::numeric / nullif(sum(heap_blks_hit) + sum(heap_blks_read), 0) * 100, 3 ) AS cache_hit_ratio FROM pg_statio_user_tables; -- По каждой таблице: SELECT relname AS table_name, heap_blks_hit, heap_blks_read, round(heap_blks_hit::numeric / nullif(heap_blks_hit + heap_blks_read, 0) * 100, 2) AS cache_hit_pct, idx_blks_hit, idx_blks_read, round(idx_blks_hit::numeric / nullif(idx_blks_hit + idx_blks_read, 0) * 100, 2) AS idx_cache_hit_pct FROM pg_statio_user_tables WHERE heap_blks_read + heap_blks_hit > 0 ORDER BY heap_blks_read DESC LIMIT 20; -- ===== CHECKPOINT СТАТИСТИКА ===== SELECT checkpoints_timed, checkpoints_req, -- Если часто req >> timed: увеличить max_wal_size checkpoint_write_time / 1000 AS write_sec, checkpoint_sync_time / 1000 AS sync_sec, buffers_checkpoint, buffers_clean, buffers_backend, -- Если много: bgwriter не успевает → тюнинг bgwriter buffers_backend_fsync, -- НЕ ноль = ПРОБЛЕМА: backend делает fsync сам buffers_alloc FROM pg_stat_bgwriter; -- Если buffers_backend > 0 — увеличить bgwriter_lru_maxpages: -- bgwriter_lru_maxpages = 200 (дефолт 100) -- bgwriter_lru_multiplier = 4.0 (дефолт 2.0) -- bgwriter_delay = 50ms (дефолт 200ms) Скрипт ежедневного health-check-- Сохранить как daily_healthcheck.sql и запускать через cron \echo '=== PostgreSQL Daily Health Check ===' \echo '' \echo '--- Database Sizes ---' SELECT datname, pg_size_pretty(pg_database_size(datname)) AS size FROM pg_database WHERE datname NOT IN ('postgres', 'template0', 'template1') ORDER BY pg_database_size(datname) DESC; \echo '' \echo '--- Top 10 Largest Tables ---' SELECT schemaname || '.' || tablename AS table, pg_size_pretty(pg_total_relation_size(schemaname||'.'||tablename)) AS total_size FROM pg_tables WHERE schemaname = 'public' ORDER BY pg_total_relation_size(schemaname||'.'||tablename) DESC LIMIT 10; \echo '' \echo '--- Tables with High Dead Tuple Ratio (> 10%) ---' SELECT relname, n_live_tup, n_dead_tup, round(n_dead_tup::numeric / nullif(n_live_tup + n_dead_tup, 0) * 100, 1) AS dead_pct, last_autovacuum FROM pg_stat_user_tables WHERE n_dead_tup::numeric / nullif(n_live_tup + n_dead_tup, 0) > 0.1 AND n_live_tup > 1000 ORDER BY dead_pct DESC; \echo '' \echo '--- Replication Lag ---' SELECT application_name, replay_lag, sync_state FROM pg_stat_replication; \echo '' \echo '--- Long-Running Transactions (> 1 hour) ---' SELECT pid, usename, now() - xact_start AS duration, left(query, 100) AS query FROM pg_stat_activity WHERE xact_start IS NOT NULL AND now() - xact_start > INTERVAL '1 hour' AND pid != pg_backend_pid() ORDER BY duration DESC; \echo '' \echo '--- Unused Indexes (0 scans) ---' SELECT schemaname, tablename, indexname, pg_size_pretty(pg_relation_size(indexrelid)) AS size FROM pg_stat_user_indexes WHERE idx_scan = 0 AND pg_relation_size(indexrelid) > 10 * 1024 * 1024 -- > 10 МБ ORDER BY pg_relation_size(indexrelid) DESC LIMIT 10; Глава 9. Новинки PostgreSQL 16/17/18PostgreSQL 16 (2023)Логическая репликация от standby — теперь можно публиковать изменения не только с primary, разгружая мастер. Параллельный COPY — загрузка данных через COPY стала параллельной. Улучшения планировщика для GROUP BY с параллелизмом. pg_stat_io — новая системная вьюшка для детальной статистики I/O: -- PostgreSQL 16+: детальная I/O статистика SELECT backend_type, object, context, reads, writes, extends, op_bytes, hits, evictions, reuses, fsyncs, read_time, write_time FROM pg_stat_io ORDER BY reads + writes DESC; -- Особенно полезно: сравнить hits vs reads для разных backend_type COPY FROM ... WHERE — фильтрация при загрузке данных: -- Загружаем только нужные строки COPY orders FROM '/tmp/orders.csv' CSV HEADER WHERE status = 'completed' AND total > 100; PostgreSQL 17 (2024)MERGE стал намного мощнее — поддержка RETURNING, DO NOTHING: -- PostgreSQL 17: MERGE с RETURNING MERGE INTO inventory AS target USING incoming_stock AS source ON target.product_id = source.product_id WHEN MATCHED THEN UPDATE SET quantity = target.quantity + source.quantity WHEN NOT MATCHED THEN INSERT (product_id, quantity) VALUES (source.product_id, source.quantity) RETURNING target.product_id, target.quantity, merge_action(); -- merge_action() → 'INSERT' или 'UPDATE' Incremental sorting улучшен — быстрее для DISTINCT и ORDER BY. pg_stat_statements получил toplevel — разделение top-level vs вложенных запросов. Vacuum improvements — улучшена скорость заморозки (freeze), меньше I/O. VACUUM (SKIP_DATABASE_STATS) — ускорение вакуума многих мелких таблиц. Размер WAL записей уменьшен — меньше I/O при интенсивной записи. PostgreSQL 18 (2025, в разработке / ранние беты)Встроенный асинхронный I/O (io_method = io_uring) — огромный прирост для NVMe SSD, особенно при высоком параллелизме: # postgresql.conf (PostgreSQL 18 при использовании Linux io_uring) io_method = io_uring # Дефолт: sync; альтернатива: worker Планировщик с ML-hints — работа над улучшением кардинальности оценок. GRANT/REVOKE для роли по умолчанию — улучшена система безопасности. Глава 10. Практические кейсы: реальные проблемы и их решенияКейс 1: «Запросы стали медленнее после VACUUM»-- Симптом: autovacuum отработал, но запросы стали медленнее. -- Причина: устаревшая статистика. VACUUM не обновляет статистику! -- Решение 1: Принудительный ANALYZE ANALYZE VERBOSE orders; -- Или для всей БД: -- vacuumdb --analyze-only --all -- Решение 2: Увеличить точность статистики для проблемных колонок ALTER TABLE orders ALTER COLUMN status SET STATISTICS 500, ALTER COLUMN region SET STATISTICS 500; ANALYZE orders; -- Проверить статистику после: SELECT attname, n_distinct, correlation FROM pg_stats WHERE tablename = 'orders' AND attname IN ('status', 'region', 'created_at'); Кейс 2: «Диск заполнился WAL файлами»-- Причина 1: Зависший логический слот репликации SELECT slot_name, active, wal_status, pg_size_pretty( pg_wal_lsn_diff(pg_current_wal_lsn(), restart_lsn) ) AS retained_wal FROM pg_replication_slots WHERE wal_status != 'reserved'; -- Если слот неактивен и держит WAL — удалить после согласования с командой: SELECT pg_drop_replication_slot('stale_slot_name'); -- Причина 2: archive_command не успевает -- Проверить: SELECT last_archived_wal, last_failed_wal, last_failed_time FROM pg_stat_archiver; -- Временная мера: уменьшить max_wal_size -- Постоянная: починить archive_command или увеличить место -- Причина 3: Слишком агрессивные checkpoint -- Уменьшить wal_keep_size если репликация живая Кейс 3: «Connection pool переполнен, приложение не может подключиться»-- Диагноз: смотрим pg_stat_activity SELECT state, count(*), left(query, 50) AS sample_query FROM pg_stat_activity WHERE datname = 'myapp_db' GROUP BY state, left(query, 50) ORDER BY count(*) DESC; -- Частая причина: idle in transaction (транзакция открыта и забыта) SELECT pid, now() - xact_start AS idle_duration, query FROM pg_stat_activity WHERE state = 'idle in transaction' AND now() - xact_start > INTERVAL '5 minutes' ORDER BY idle_duration DESC; -- Быстрое решение: убить зависшие idle in transaction SELECT pg_terminate_backend(pid) FROM pg_stat_activity WHERE state = 'idle in transaction' AND now() - xact_start > INTERVAL '10 minutes'; -- Постоянное решение: idle_in_transaction_session_timeout -- postgresql.conf: -- idle_in_transaction_session_timeout = 5min -- idle_session_timeout = 30min (PG 14+) Кейс 4: «Таблица растёт несмотря на DELETE»-- Table bloat: место от удалённых строк не возвращается OS. -- PostgreSQL помечает строки как "мёртвые", VACUUM освобождает их -- для ПОВТОРНОГО ИСПОЛЬЗОВАНИЯ, но не возвращает OS (кроме pg_toast). -- Проверить bloat: SELECT relname, pg_size_pretty(pg_total_relation_size(oid)) AS total_size, n_dead_tup, n_live_tup FROM pg_stat_user_tables JOIN pg_class USING (relid) WHERE relname = 'your_table'; -- Решение 1: VACUUM FULL (блокирует таблицу! Используйте в окно обслуживания) VACUUM FULL ANALYZE your_table; -- Решение 2: pg_repack (без блокировки!) -- Устанавливается отдельно: https://github.com/reorg/pg_repack -- pg_repack -d mydb -t your_table -- Решение 3: для партиционированных таблиц — просто удалить старую партицию -- ALTER TABLE events DETACH PARTITION events_2022_01; -- DROP TABLE events_2022_01; -- Мгновенное освобождение места! Заключение: чеклист production PostgreSQLКОНФИГУРАЦИЯ □ shared_buffers = 25-40% RAM □ effective_cache_size = 50-75% RAM □ work_mem настроен с учётом max_connections × parallel_workers □ random_page_cost = 1.1-1.5 для SSD/NVMe □ huge_pages = on (при shared_buffers > 8 ГБ, настроен в Linux) □ max_wal_size = 2-8 ГБ (зависит от нагрузки) □ wal_compression = lz4 (PG 15+) □ idle_in_transaction_session_timeout = 5min □ statement_timeout = установлен разумный лимит МОНИТОРИНГ □ pg_stat_statements включён и регулярно анализируется □ Алерт на cache hit ratio < 95% □ Алерт на replication lag > 60s □ Алерт на bloat > 30% для критичных таблиц □ Алерт на неактивные replication slots □ Ежедневный health check запрос AUTOVACUUM □ autovacuum_max_workers = 4-6 □ autovacuum_vacuum_cost_delay = 2ms (SSD) □ autovacuum_vacuum_cost_limit = 800-2000 □ Scale factor снижен для горячих таблиц □ Мониторинг n_dead_tup и xid_age СОЕДИНЕНИЯ □ PgBouncer в transaction mode □ max_connections ≤ 300 (больше — через пул) □ Настроен pool_size в PgBouncer □ Мониторинг cl_waiting в PgBouncer ИНДЕКСЫ □ Аудит неиспользуемых индексов (pg_stat_user_indexes) □ Составные индексы с правильным порядком колонок □ INCLUDE для покрывающих индексов □ BRIN для append-only больших таблиц РЕПЛИКАЦИЯ □ Мониторинг replay_lag □ Мониторинг pg_replication_slots на утечку WAL □ Проверка wal_status всех слотов □ hot_standby_feedback = on на репликах БЕЗОПАСНОСТЬ □ scram-sha-256 в pg_hba.conf □ Минимальные привилегии для каждого пользователя □ ssl = on + проверка сертификатов □ log_connections/log_disconnections для аудита PostgreSQL — невероятно мощная система, которая «из коробки» даёт примерно 20% своего потенциала. Правильная конфигурация, индексная стратегия и мониторинг превращают её в продукт, который выдерживает тысячи транзакций в секунду на десятках терабайт данных — без дорогостоящих «облачных» альтернатив.
Введение: PostgreSQL в продакшене — другой зверьПоднять PostgreSQL локально — просто. Запустить его в продакшене под реальной нагрузкой так, чтобы он не падал, не тормозил и не раздувался до потери диска — это уже инженерия. PostgreSQL 16, 17 и 18 принесли серьёзные улучшения производительности: логическая репликация стала намного мощнее, параллельные запросы умнее, планировщик научился большему. Но дефолтная конфигурация по-прежнему рассчитана на «запустить на ноутбуке с 256 МБ RAM», а не на production-сервер с 128 ГБ памяти. Эта статья — системный разбор всего, что нужно сделать, чтобы PostgreSQL работал быстро, надёжно и предсказуемо. Никакой воды: только параметры, SQL, реальные кейсы. Глава 1. Конфигурация: postgresql.conf с нуляПамять: самые важные параметры# postgresql.conf # shared_buffers — основной кэш PostgreSQL в памяти. # Правило: 25-40% от RAM сервера. # На 64 ГБ RAM: 16 ГБ shared_buffers = 16GB # effective_cache_size — подсказка планировщику, сколько памяти # доступно для кэширования (shared_buffers + OS page cache). # Правило: 50-75% от RAM. # На 64 ГБ RAM: 48 ГБ effective_cache_size = 48GB # work_mem — память для одной операции сортировки/хэширования # ВНИМАНИЕ: умножается на число параллельных запросов × число операций в плане! # На сервере с 500 соединениями и work_mem=256MB → потенциально 128 ГБ! # Разумно: 4-64 МБ для OLTP, 256 МБ-1 ГБ для аналитики work_mem = 32MB # maintenance_work_mem — для VACUUM, CREATE INDEX, ALTER TABLE # Больше = быстрее индексы и вакуум. Безопасно давать больше, чем work_mem. maintenance_work_mem = 2GB # huge_pages — используем hugepages Linux для shared_buffers # Обязательно для shared_buffers > 8 ГБ huge_pages = on WAL и checkpoint: баланс между скоростью и надёжностью# wal_level — минимальный уровень для репликации # replica — для физической репликации # logical — для логической репликации (больше overhead) wal_level = replica # Размер WAL буфера (с PostgreSQL 16 wal_buffers=auto работает хорошо) wal_buffers = 64MB # checkpoint_completion_target — размазываем запись checkpoint во времени # 0.9 означает: записать грязные страницы за 90% интервала между checkpoint checkpoint_completion_target = 0.9 # max_wal_size — максимальный объём WAL между checkpoint # При большой нагрузке на запись увеличьте до 4-16 ГБ # Это НЕ размер хранилища WAL, а порог для инициации checkpoint max_wal_size = 4GB # min_wal_size — минимальный резерв WAL файлов min_wal_size = 1GB # wal_compression — сжатие WAL (PostgreSQL 15+: поддержка lz4, zstd) # Снижает I/O, небольшой CPU overhead wal_compression = lz4 Параллелизм (PostgreSQL 16+)# max_worker_processes — общий пул фоновых процессов max_worker_processes = 16 # max_parallel_workers_per_gather — параллельные воркеры на один запрос # Правило: не более числа физических ядер / 2 max_parallel_workers_per_gather = 4 # max_parallel_workers — суммарно параллельных воркеров max_parallel_workers = 8 # max_parallel_maintenance_workers — для CREATE INDEX CONCURRENTLY, VACUUM max_parallel_maintenance_workers = 4 # parallel_tuple_cost, parallel_setup_cost — влияют на решение планировщика # использовать параллельность. Снизить если параллельные планы не строятся. parallel_tuple_cost = 0.1 parallel_setup_cost = 100 Соединения# max_connections — ОСТОРОЖНО! Каждое соединение ≈ 5-10 МБ памяти. # При PgBouncer: достаточно 100-200 серверных соединений. # Без пула: реальное число ≤ 200-300 max_connections = 200 # superuser_reserved_connections — резерв для DBA superuser_reserved_connections = 5 Планировщик: тонкая настройка# random_page_cost — стоимость случайного чтения страницы. # Для SSD: 1.1-1.5 (против дефолта 4.0 для HDD). # Занижение → планировщик чаще выбирает Index Scan. random_page_cost = 1.1 # seq_page_cost — стоимость последовательного чтения (база = 1.0) seq_page_cost = 1.0 # effective_io_concurrency — параллельных I/O для Bitmap Heap Scan # SSD: 200-300, HDD: 2-4, NVMe: 500+ effective_io_concurrency = 200 # default_statistics_target — точность статистики для планировщика # Дефолт 100. Для колонок с высокой кардинальностью — до 500. default_statistics_target = 200 # enable_partitionwise_join — важно для партиционированных таблиц enable_partitionwise_join = on enable_partitionwise_aggregate = on Глава 2. Индексная стратегияПравильные индексы — половина успеха. Неправильные — гарантированный bloat и тормоза на INSERT/UPDATE. Типы индексов: когда что использоватьB-Tree — дефолт, для равенства и диапазонов: -- Стандартный случай CREATE INDEX idx_orders_user_id ON orders(user_id); -- Частичный индекс — только активные записи -- Занимает меньше места, быстрее обновляется CREATE INDEX idx_orders_active ON orders(created_at) WHERE status = 'active'; -- Покрывающий индекс (INCLUDE) — избегаем обращения к таблице -- PostgreSQL 11+, активно улучшен в 16/17 CREATE INDEX idx_orders_cover ON orders(user_id) INCLUDE (total_amount, status, created_at); -- Составной: порядок имеет значение! -- Ставьте впереди колонки с высокой кардинальностью -- и те, по которым фильтрация точнее CREATE INDEX idx_orders_composite ON orders(user_id, status, created_at); GIN — для массивов, JSONB, полнотекстового поиска: -- JSONB поиск CREATE INDEX idx_products_attrs ON products USING GIN(attributes); -- Полнотекстовый поиск CREATE INDEX idx_articles_fts ON articles USING GIN(to_tsvector('russian', title || ' ' || body)); -- Поиск в массивах CREATE INDEX idx_tags ON posts USING GIN(tags); BRIN — для очень больших таблиц с естественной сортировкой: -- Для таблиц логов, временных рядов — экономия места 99%+ -- BRIN не хранит каждое значение, только мин/макс по блокам CREATE INDEX idx_events_time_brin ON events USING BRIN(created_at) WITH (pages_per_range = 128); -- PostgreSQL 14+: bloom filter в BRIN CREATE INDEX idx_events_bloom ON events USING BRIN(device_id, created_at) WITH (pages_per_range = 64); Hash — только для точного равенства, быстрее B-Tree: CREATE INDEX idx_sessions_token ON sessions USING HASH(session_token); Найти неиспользуемые и дублирующие индексы-- Неиспользуемые индексы (кандидаты на удаление) SELECT schemaname, tablename, indexname, pg_size_pretty(pg_relation_size(indexrelid)) AS index_size, idx_scan, idx_tup_read, idx_tup_fetch FROM pg_stat_user_indexes WHERE idx_scan = 0 AND indexrelname NOT LIKE 'pg_%' ORDER BY pg_relation_size(indexrelid) DESC; -- Дублирующие индексы SELECT indrelid::regclass AS table_name, array_agg(indexrelid::regclass) AS indexes, array_agg(indkey) AS index_keys FROM pg_index GROUP BY indrelid, indkey HAVING count(*) > 1; -- Индексы vs размер таблицы: раздутые индексы SELECT t.tablename, pg_size_pretty(pg_total_relation_size(t.tablename::regclass)) AS total, pg_size_pretty(pg_relation_size(t.tablename::regclass)) AS table_size, pg_size_pretty( pg_total_relation_size(t.tablename::regclass) - pg_relation_size(t.tablename::regclass) ) AS indexes_size, round( (pg_total_relation_size(t.tablename::regclass) - pg_relation_size(t.tablename::regclass))::numeric / nullif(pg_total_relation_size(t.tablename::regclass), 0) * 100, 1 ) AS index_ratio_pct FROM pg_tables t WHERE t.schemaname = 'public' ORDER BY pg_total_relation_size(t.tablename::regclass) DESC LIMIT 30; Глава 3. EXPLAIN ANALYZE: читаем план запроса как профессионалEXPLAIN ANALYZE — главный инструмент оптимизации. Без него — гадание на кофейной гуще. -- Всегда используйте все опции EXPLAIN ( ANALYZE, -- Реально выполнить и показать время BUFFERS, -- Показать попадания/промахи кэша FORMAT TEXT, -- или JSON для авто-анализа TIMING ON, -- Время каждого узла SETTINGS ON, -- Показать изменённые параметры WAL ON -- PostgreSQL 13+: WAL активность ) SELECT ...; Анатомия плана: на что смотретьEXPLAIN (ANALYZE, BUFFERS) SELECT o.id, o.total, u.email FROM orders o JOIN users u ON u.id = o.user_id WHERE o.created_at > NOW() - INTERVAL '7 days' AND o.status = 'completed'; -- Типичный вывод: -- QUERY PLAN -- Hash Join (cost=1250.00..8934.21 rows=1523 width=48) (actual time=45.231..189.443 rows=1287 loops=1) -- Buffers: shared hit=4521 read=2341 ← read > 0 = данных нет в кэше -- Hash Cond: (o.user_id = u.id) -- -> Bitmap Heap Scan on orders o (cost=87.3..7512.4 rows=1523 width=32) -- (actual time=2.341..145.231 rows=1287 loops=1) -- Recheck Cond: (created_at > (now() - '7 days'::interval)) -- Filter: (status = 'completed') -- Rows Removed by Filter: 4521 ← КРАСНЫЙ ФЛАГ: фильтруем 4521 строк! -- Heap Blocks: exact=1823 -- Buffers: shared hit=123 read=1823 -- -> Bitmap Index Scan on idx_orders_created_at -- Index Cond: (created_at > (now() - '7 days'::interval)) -- -> Hash (cost=890.00..890.00 rows=21000 width=24) (actual time=42.3..42.3 rows=21000 loops=1) -- Buckets: 32768 Batches: 1 Memory Usage: 1856kB -- Buffers: shared hit=4398 read=518 -- -> Seq Scan on users u (cost=0.00..890.00 rows=21000 width=24) -- Planning Time: 1.234 ms -- Execution Time: 190.123 ms ← Реальное время! Красные флаги в плане: Признак Проблема Решение Rows Removed by Filter >> возвращаемых строк Индекс не покрывает все условия Добавить колонку status в индекс actual rows >> estimated rows (×10+) Устаревшая статистика ANALYZE table или повысить default_statistics_target Seq Scan на большой таблице Нет подходящего индекса Создать индекс Batches: N (N > 1) в Hash Join Хэш-таблица не помещается в work_mem Увеличить work_mem или оптимизировать запрос loops=N при N×cost = огромно Вложенный цикл на большом наборе Рассмотреть Hash Join / Merge Join shared read >> shared hit Данные не в кэше Увеличить shared_buffers или прогреть кэш Автоматический поиск медленных запросов-- pg_stat_statements: топ-20 самых дорогих запросов -- Требует: shared_preload_libraries = 'pg_stat_statements' -- postgresql.conf: pg_stat_statements.track = all SELECT round(total_exec_time::numeric, 2) AS total_ms, calls, round(mean_exec_time::numeric, 2) AS mean_ms, round(stddev_exec_time::numeric, 2) AS stddev_ms, round((total_exec_time / sum(total_exec_time) OVER () * 100)::numeric, 2) AS pct_total, round(rows::numeric / calls, 1) AS avg_rows, -- Соотношение кэш-попаданий round( 100.0 * shared_blks_hit / nullif(shared_blks_hit + shared_blks_read, 0), 2 ) AS cache_hit_pct, -- Нормализованный текст запроса (без значений параметров) left(query, 100) AS query_snippet FROM pg_stat_statements WHERE calls > 10 ORDER BY total_exec_time DESC LIMIT 20; -- Запросы с самым высоким среднем временем (не суммарным!) SELECT calls, round(mean_exec_time::numeric, 2) AS mean_ms, round(max_exec_time::numeric, 2) AS max_ms, round(stddev_exec_time::numeric, 2) AS stddev_ms, left(query, 120) AS query FROM pg_stat_statements WHERE calls > 5 AND mean_exec_time > 100 -- Больше 100 мс в среднем ORDER BY mean_exec_time DESC LIMIT 20; -- Запросы с плохим cache hit ratio (много disk reads) SELECT calls, round(mean_exec_time::numeric, 2) AS mean_ms, shared_blks_read, shared_blks_hit, round(100.0 * shared_blks_hit / nullif(shared_blks_hit + shared_blks_read, 0), 2) AS cache_hit_pct, left(query, 120) AS query FROM pg_stat_statements WHERE calls > 10 AND (shared_blks_hit + shared_blks_read) > 0 AND shared_blks_read > shared_blks_hit -- Больше промахов чем попаданий ORDER BY shared_blks_read DESC LIMIT 20; Глава 4. Autovacuum: настройка, а не молитваAutovacuum — не враг, а друг. Но дефолтные настройки рассчитаны на небольшие таблицы. На больших таблицах он либо не успевает, либо тормозит рабочую нагрузку. Понять текущее состояние vacuum-- Таблицы с наибольшим dead tuple bloat SELECT schemaname, relname AS tablename, n_live_tup, n_dead_tup, round(n_dead_tup::numeric / nullif(n_live_tup + n_dead_tup, 0) * 100, 2) AS dead_pct, last_vacuum, last_autovacuum, last_analyze, last_autoanalyze, autovacuum_count, pg_size_pretty(pg_total_relation_size(schemaname||'.'||relname)) AS total_size FROM pg_stat_user_tables WHERE n_dead_tup > 1000 ORDER BY n_dead_tup DESC LIMIT 20; -- Таблицы, которым скоро нужен vacuum (по счётчику транзакций) -- age() показывает сколько транзакций прошло с последнего freeze SELECT schemaname, relname, pg_size_pretty(pg_total_relation_size(oid)) AS size, age(relfrozenxid) AS xid_age, round(age(relfrozenxid)::numeric / 2000000000 * 100, 2) AS freeze_pct, -- Когда автовакуум сделает freeze (по умолчанию при 150M транзакций) (200000000 - age(relfrozenxid)) AS txids_until_freeze FROM pg_class JOIN pg_namespace ON pg_namespace.oid = pg_class.relnamespace WHERE relkind = 'r' AND nspname NOT IN ('pg_catalog', 'information_schema') ORDER BY age(relfrozenxid) DESC LIMIT 20; -- Текущие процессы autovacuum SELECT pid, now() - xact_start AS duration, query, state, wait_event_type, wait_event FROM pg_stat_activity WHERE query LIKE 'autovacuum:%' ORDER BY duration DESC; Оптимальная настройка autovacuum# postgresql.conf — глобальные настройки autovacuum # Число процессов autovacuum autovacuum_max_workers = 6 # Дефолт 3; на активном сервере — 4-8 # Стоимостной лимит для autovacuum (throttling) # Дефолт 200 — очень агрессивное ограничение скорости. # На SSD можно поднять до 800-2000. autovacuum_vacuum_cost_limit = 800 # Задержка между "порциями" vacuum (cooldown) # При cost_limit=800 и delay=2ms → ~400 МБ/с максимальная скорость vacuum autovacuum_vacuum_cost_delay = 2ms # Порог запуска VACUUM: n_dead_tup > autovacuum_vacuum_threshold + n_live_tup * scale_factor autovacuum_vacuum_threshold = 50 autovacuum_vacuum_scale_factor = 0.02 # 2% от таблицы (дефолт 20%) # Порог запуска ANALYZE autovacuum_analyze_threshold = 50 autovacuum_analyze_scale_factor = 0.01 # 1% (дефолт 20%) # Для больших таблиц scale_factor делает vacuum очень редким: # Таблица 100M строк × 0.02 = 2M dead tuples до запуска vacuum — МНОГО Настройка per-table (лучше глобальных для горячих таблиц):-- Для высокоактивных таблиц: vacuum чаще, агрессивнее ALTER TABLE orders SET ( autovacuum_vacuum_scale_factor = 0.005, -- Запуск при 0.5% dead tuples autovacuum_analyze_scale_factor = 0.002, -- Analyze при 0.2% autovacuum_vacuum_cost_limit = 1600, -- Более высокий лимит I/O autovacuum_vacuum_cost_delay = 1 -- Меньше пауз ); -- Для append-only таблиц (логи, временные ряды): -- Vacuum не нужен часто, но freeze — важен ALTER TABLE event_log SET ( autovacuum_vacuum_scale_factor = 0.2, -- Редкий vacuum (мало UPDATE/DELETE) autovacuum_freeze_max_age = 500000000, -- Freeze через 500M транзакций autovacuum_vacuum_cost_limit = 2000 -- Быстрый когда запустился ); -- Проверить что настройки применились: SELECT relname, reloptions FROM pg_class WHERE relname IN ('orders', 'event_log'); Обнаружение table bloat (раздутых таблиц)-- Скрипт оценки bloat (не требует сторонних расширений) WITH constants AS ( SELECT current_setting('block_size')::numeric AS bs, 23 AS hdr, 8 AS ma ), columns_per_table AS ( SELECT att.attrelid, count(*) AS cols, -- Байт nullmap на строку (count(*) + 7) / 8 AS nullhdr FROM pg_attribute att WHERE att.attnum > 0 AND NOT att.attisdropped GROUP BY 1 ), rows_estimate AS ( SELECT c.oid, CASE WHEN c.reltuples < 0 THEN 0 ELSE c.reltuples END AS est_rows, c.relpages, c.relname, n.nspname FROM pg_class c JOIN pg_namespace n ON n.oid = c.relnamespace WHERE c.relkind = 'r' AND n.nspname NOT IN ('pg_catalog', 'information_schema') ) SELECT re.nspname || '.' || re.relname AS table_name, re.est_rows, re.relpages AS current_pages, pg_size_pretty(re.relpages * 8192) AS current_size, -- Оценочный реальный размер pg_size_pretty( ceil(re.est_rows * 30 / 8192.0)::bigint * 8192 ) AS estimated_real_size, round( 100.0 * (re.relpages - ceil(re.est_rows * 30 / 8192.0)) / nullif(re.relpages, 0), 1 ) AS bloat_pct FROM rows_estimate re WHERE re.relpages > 100 ORDER BY (re.relpages - ceil(re.est_rows * 30 / 8192.0)) DESC LIMIT 20; -- Для точного bloat используйте расширение pgstattuple: -- CREATE EXTENSION pgstattuple; SELECT * FROM pgstattuple('orders'); -- Поля: table_len, live_tuple_count, dead_tuple_count, dead_tuple_percent, free_space Глава 5. Connection Pooling с PgBouncerКаждое соединение с PostgreSQL — это отдельный процесс (~5 МБ памяти + overhead планировщика). 1000 соединений = 5 ГБ памяти только на процессы. PgBouncer решает эту проблему. Режимы PgBouncerРежим Как работает Подходит для Ограничения session 1 клиент = 1 серверное соединение на всю сессию Совместимость Нет экономии transaction Серверное соединение занято только на время транзакции OLTP, большинство приложений SET, LISTEN, prepared statements statement Одно серверное соединение на один SQL-оператор Агрессивная экономия Нет транзакций! Конфигурация PgBouncer# /etc/pgbouncer/pgbouncer.ini [databases] # Синтаксис: alias = host=... dbname=... port=... user=... myapp = host=127.0.0.1 port=5432 dbname=myapp_db # Для чтения — отдельный пул на реплику myapp_ro = host=replica.internal port=5432 dbname=myapp_db [pgbouncer] # Режим пула pool_mode = transaction # Адрес и порт PgBouncer listen_addr = 0.0.0.0 listen_port = 5432 # Максимум клиентских соединений (к PgBouncer) max_client_conn = 2000 # Размер серверного пула на базу (к PostgreSQL) # PostgreSQL: max_connections = 200 # PgBouncer: default_pool_size = 80 (на каждую базу) default_pool_size = 80 # Минимальный пул (держим готовые соединения) min_pool_size = 10 # Резерв для суперпользователя (аналог reserved_connections) reserve_pool_size = 5 reserve_pool_timeout = 3 # Таймауты server_idle_timeout = 600 # Закрыть серверное соединение через 10 мин idle client_idle_timeout = 0 # Не закрывать клиентские (0 = infinite) server_connect_timeout = 5 # Таймаут подключения к PostgreSQL query_timeout = 0 # 0 = нет лимита на запрос (лучше ставить в app) query_wait_timeout = 120 # Ждать свободного соединения до 120 с # Проверка соединений server_check_query = select 1 server_check_delay = 30 # Аутентификация (scram-sha-256 — стандарт PG 14+) auth_type = scram-sha-256 auth_file = /etc/pgbouncer/userlist.txt # Логирование (не слишком подробное — влияет на производительность) log_connections = 0 log_disconnections = 0 log_pooler_errors = 1 # Admin интерфейс admin_users = pgbouncer_admin stats_users = monitoring_user # Производительность tcp_keepalive = 1 tcp_keepidle = 60 tcp_keepintvl = 10 tcp_keepcnt = 5 Мониторинг PgBouncer-- Подключиться к admin БД PgBouncer: -- psql -h localhost -p 5432 -U pgbouncer_admin pgbouncer -- Состояние пулов SHOW POOLS; -- cl_active — клиентов с активным серверным соединением -- cl_waiting — клиентов в очереди (ждут свободного соединения!) -- sv_active — серверных соединений в работе -- sv_idle — серверных соединений в ожидании (пул) -- sv_used — только что освобождённые (не проверены ещё) -- maxwait — максимальное время ожидания клиента (критический параметр!) -- Статистика SHOW STATS; -- total_query_time — суммарное время выполнения запросов -- avg_query_time — среднее время запроса -- total_wait_time — суммарное время ожидания в очереди -- Список клиентов SHOW CLIENTS; -- Перезагрузить конфиг без перезапуска RELOAD; -- Сбросить статистику RESET STATS; Интеграция с PostgreSQL 17: встроенный connection shardPostgreSQL 17 улучшил max_connections по производительности и добавил механизм connection_obeys_lc_messages — мелочь, но полезная. Работа над встроенным пулингом (connection pooling) ведётся активно, следите за PostgreSQL 18. Глава 6. Партиционирование: когда таблица растёт до сотен ГБПартиционирование делит одну логическую таблицу на несколько физических. PostgreSQL 16/17 значительно улучшили работу с партициями: умный pruning, параллельные операции, partition-wise joins. RANGE партиционирование (самое частое — по дате)-- Создание партиционированной таблицы CREATE TABLE events ( id BIGSERIAL, created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(), device_id INT NOT NULL, event_type TEXT NOT NULL, payload JSONB, PRIMARY KEY (id, created_at) -- created_at обязательна в PK для партиций! ) PARTITION BY RANGE (created_at); -- Создание партиций (вручную или автоматически) CREATE TABLE events_2024_01 PARTITION OF events FOR VALUES FROM ('2024-01-01') TO ('2024-02-01'); CREATE TABLE events_2024_02 PARTITION OF events FOR VALUES FROM ('2024-02-01') TO ('2024-03-01'); -- DEFAULT партиция для данных вне диапазона CREATE TABLE events_default PARTITION OF events DEFAULT; -- Индексы создаются на каждой партиции отдельно -- (или глобально через CREATE INDEX на родительской — PG 11+) CREATE INDEX idx_events_device ON events(device_id, created_at); -- Автоматически создаст индекс на каждой партиции! Автоматическое создание партиций (pg_partman)Ручное создание партиций — путь к ошибкам. Используйте pg_partman: -- Установка pg_partman -- Добавить в postgresql.conf: shared_preload_libraries = 'pg_partman_bgw' -- Настройка автоматического управления партициями SELECT partman.create_parent( p_parent_table => 'public.events', p_control => 'created_at', p_interval => 'monthly', -- или 'weekly', 'daily', 'yearly' p_premake => 3, -- Создавать 3 будущих партиции заранее p_start_partition => '2024-01-01' ); -- Настройка retention (удаление старых партиций) UPDATE partman.part_config SET retention = '12 months', -- Хранить 12 месяцев retention_keep_table = false, -- Удалять партицию физически retention_keep_index = false -- Удалять и индексы WHERE parent_table = 'public.events'; -- Запуск обслуживания вручную (обычно pg_partman_bgw делает это сам) CALL partman.run_maintenance_proc(); Partition Pruning: проверяем что планировщик умный-- Планировщик должен сканировать только нужные партиции EXPLAIN SELECT count(*) FROM events WHERE created_at BETWEEN '2024-03-01' AND '2024-03-31'; -- Ищем в плане: "Partitions: events_2024_03" -- НЕ должно быть: "Append (всех партиций)" -- Если pruning не работает — проверьте что условие на колонку партиционирования -- и её тип совпадают (нет неявных каст) -- Partition pruning во время выполнения (runtime pruning, PG 11+) -- Работает даже для параметров ($1, $2) если enable_partition_pruning = on SET enable_partition_pruning = on; -- Дефолт on в PG 16+ LIST партиционирование (по типу/региону)CREATE TABLE orders ( id BIGSERIAL, region TEXT NOT NULL, created_at TIMESTAMPTZ DEFAULT NOW(), total DECIMAL(10,2) ) PARTITION BY LIST (region); CREATE TABLE orders_eu PARTITION OF orders FOR VALUES IN ('DE', 'FR', 'NL', 'PL'); CREATE TABLE orders_us PARTITION OF orders FOR VALUES IN ('US', 'CA', 'MX'); CREATE TABLE orders_asia PARTITION OF orders FOR VALUES IN ('CN', 'JP', 'KR', 'IN'); CREATE TABLE orders_rest PARTITION OF orders DEFAULT; HASH партиционирование (равномерное распределение)-- Для таблиц без естественного ключа партиционирования -- Гарантирует примерно равный размер партиций CREATE TABLE sessions ( id UUID DEFAULT gen_random_uuid(), user_id INT NOT NULL, data JSONB ) PARTITION BY HASH (user_id); -- Создаём N партиций (степень двойки — хорошая практика) CREATE TABLE sessions_0 PARTITION OF sessions FOR VALUES WITH (MODULUS 8, REMAINDER 0); CREATE TABLE sessions_1 PARTITION OF sessions FOR VALUES WITH (MODULUS 8, REMAINDER 1); -- ... и т.д. до sessions_7 Глава 7. Репликация: PostgreSQL 16/17/18Физическая репликация (Streaming Replication)# На Primary: postgresql.conf wal_level = replica max_wal_senders = 10 # Максимум одновременных реплик wal_keep_size = 1GB # Буфер WAL для реплик (PG 13+, заменил wal_keep_segments) hot_standby = on # Разрешить запросы на реплике hot_standby_feedback = on # Реплика сообщает Primary о своих транзакциях # pg_hba.conf на Primary — разрешаем репликацию с адреса реплики: # host replication replicator 10.0.0.2/32 scram-sha-256 # На Standby: создание базовой копии pg_basebackup \ -h primary.host \ -U replicator \ -D /var/lib/postgresql/17/main \ -P \ --wal-method=stream \ --checkpoint=fast \ --write-recovery-conf # Создаёт standby.signal и postgresql.auto.conf # postgresql.auto.conf на Standby (создаётся pg_basebackup): # primary_conninfo = 'host=primary.host port=5432 user=replicator password=...' -- Мониторинг репликации на Primary: SELECT client_addr, usename, application_name, state, sent_lsn, write_lsn, flush_lsn, replay_lsn, -- Лаг в байтах pg_wal_lsn_diff(sent_lsn, replay_lsn) AS replay_lag_bytes, -- Лаг во времени (PG 10+) write_lag, flush_lag, replay_lag, sync_state FROM pg_stat_replication ORDER BY replay_lag DESC; -- На Standby — проверка своего лага: SELECT now() - pg_last_xact_replay_timestamp() AS replication_lag, pg_is_in_recovery() AS is_replica, pg_last_wal_receive_lsn() AS received_lsn, pg_last_wal_replay_lsn() AS replayed_lsn; Логическая репликация (PostgreSQL 16/17: серьёзно улучшена)Логическая репликация в PostgreSQL 16 получила: Двунаправленная (bidirectional) репликация — обе стороны могут принимать запись Streaming больших транзакций в реальном времени (без ожидания COMMIT) Параллельное применение изменений на подписчике -- На Publisher (источник): -- postgresql.conf: wal_level = logical -- Создание публикации CREATE PUBLICATION my_pub FOR TABLE orders, users, products WITH (publish = 'insert, update, delete', publish_via_partition_root = true); -- Для всех таблиц: CREATE PUBLICATION all_tables FOR ALL TABLES; -- На Subscriber (назначение): -- Создание подписки CREATE SUBSCRIPTION my_sub CONNECTION 'host=primary.host port=5432 dbname=mydb user=replicator password=secret' PUBLICATION my_pub WITH ( connect = true, slot_name = 'my_sub_slot', synchronous_commit = 'off', -- Более быстрая репликация streaming = on -- PG 14+: stream больших транзакций ); -- Мониторинг логической репликации на Publisher: SELECT slot_name, plugin, slot_type, database, active, active_pid, -- КРИТИЧНО: wal_status = 'lost' означает что слот отстал и WAL удалён wal_status, pg_size_pretty(pg_wal_lsn_diff(pg_current_wal_lsn(), confirmed_flush_lsn)) AS subscriber_lag FROM pg_replication_slots; -- ОПАСНОСТЬ: неактивный logical slot держит WAL! Диск кончится. -- Если слот не используется > 24ч — проверить и при необходимости удалить: -- SELECT pg_drop_replication_slot('my_sub_slot'); Глава 8. Мониторинг: что смотреть в продакшенеСистемные вьюшки — источник правды-- ===== АКТИВНЫЕ ЗАПРОСЫ И БЛОКИРОВКИ ===== -- Запросы дольше 30 секунд — потенциальные проблемы SELECT pid, now() - pg_stat_activity.query_start AS duration, query, state, wait_event_type, wait_event, client_addr, usename, application_name FROM pg_stat_activity WHERE (now() - pg_stat_activity.query_start) > INTERVAL '30 seconds' AND state != 'idle' ORDER BY duration DESC; -- Граф блокировок: кто кого блокирует WITH RECURSIVE lock_graph AS ( -- Базовый случай: запросы, ожидающие блокировку SELECT blocked.pid AS blocked_pid, blocked.query AS blocked_query, blocked.query_start AS blocked_start, blocker.pid AS blocker_pid, blocker.query AS blocker_query, 0 AS depth FROM pg_stat_activity blocked JOIN pg_stat_activity blocker ON blocker.pid = ANY(pg_blocking_pids(blocked.pid)) WHERE blocked.wait_event_type = 'Lock' UNION ALL -- Рекурсивный случай: цепочки блокировок SELECT lg.blocked_pid, lg.blocked_query, lg.blocked_start, blocker.pid, blocker.query, lg.depth + 1 FROM lock_graph lg JOIN pg_stat_activity blocker ON blocker.pid = ANY(pg_blocking_pids(lg.blocker_pid)) WHERE lg.depth < 10 ) SELECT blocked_pid, left(blocked_query, 80) AS blocked_query, now() - blocked_start AS wait_duration, blocker_pid, left(blocker_query, 80) AS blocker_query, depth FROM lock_graph ORDER BY wait_duration DESC; -- Если нужно убить зависший запрос (мягко): -- SELECT pg_cancel_backend(pid); -- Отмена запроса, транзакция откатывается -- Если не реагирует (жёстко): -- SELECT pg_terminate_backend(pid); -- Завершение процесса -- ===== КЭШ И I/O ===== -- Cache hit ratio (цель: > 99%) SELECT sum(heap_blks_hit) AS heap_hit, sum(heap_blks_read) AS heap_read, round( sum(heap_blks_hit)::numeric / nullif(sum(heap_blks_hit) + sum(heap_blks_read), 0) * 100, 3 ) AS cache_hit_ratio FROM pg_statio_user_tables; -- По каждой таблице: SELECT relname AS table_name, heap_blks_hit, heap_blks_read, round(heap_blks_hit::numeric / nullif(heap_blks_hit + heap_blks_read, 0) * 100, 2) AS cache_hit_pct, idx_blks_hit, idx_blks_read, round(idx_blks_hit::numeric / nullif(idx_blks_hit + idx_blks_read, 0) * 100, 2) AS idx_cache_hit_pct FROM pg_statio_user_tables WHERE heap_blks_read + heap_blks_hit > 0 ORDER BY heap_blks_read DESC LIMIT 20; -- ===== CHECKPOINT СТАТИСТИКА ===== SELECT checkpoints_timed, checkpoints_req, -- Если часто req >> timed: увеличить max_wal_size checkpoint_write_time / 1000 AS write_sec, checkpoint_sync_time / 1000 AS sync_sec, buffers_checkpoint, buffers_clean, buffers_backend, -- Если много: bgwriter не успевает → тюнинг bgwriter buffers_backend_fsync, -- НЕ ноль = ПРОБЛЕМА: backend делает fsync сам buffers_alloc FROM pg_stat_bgwriter; -- Если buffers_backend > 0 — увеличить bgwriter_lru_maxpages: -- bgwriter_lru_maxpages = 200 (дефолт 100) -- bgwriter_lru_multiplier = 4.0 (дефолт 2.0) -- bgwriter_delay = 50ms (дефолт 200ms) Скрипт ежедневного health-check-- Сохранить как daily_healthcheck.sql и запускать через cron \echo '=== PostgreSQL Daily Health Check ===' \echo '' \echo '--- Database Sizes ---' SELECT datname, pg_size_pretty(pg_database_size(datname)) AS size FROM pg_database WHERE datname NOT IN ('postgres', 'template0', 'template1') ORDER BY pg_database_size(datname) DESC; \echo '' \echo '--- Top 10 Largest Tables ---' SELECT schemaname || '.' || tablename AS table, pg_size_pretty(pg_total_relation_size(schemaname||'.'||tablename)) AS total_size FROM pg_tables WHERE schemaname = 'public' ORDER BY pg_total_relation_size(schemaname||'.'||tablename) DESC LIMIT 10; \echo '' \echo '--- Tables with High Dead Tuple Ratio (> 10%) ---' SELECT relname, n_live_tup, n_dead_tup, round(n_dead_tup::numeric / nullif(n_live_tup + n_dead_tup, 0) * 100, 1) AS dead_pct, last_autovacuum FROM pg_stat_user_tables WHERE n_dead_tup::numeric / nullif(n_live_tup + n_dead_tup, 0) > 0.1 AND n_live_tup > 1000 ORDER BY dead_pct DESC; \echo '' \echo '--- Replication Lag ---' SELECT application_name, replay_lag, sync_state FROM pg_stat_replication; \echo '' \echo '--- Long-Running Transactions (> 1 hour) ---' SELECT pid, usename, now() - xact_start AS duration, left(query, 100) AS query FROM pg_stat_activity WHERE xact_start IS NOT NULL AND now() - xact_start > INTERVAL '1 hour' AND pid != pg_backend_pid() ORDER BY duration DESC; \echo '' \echo '--- Unused Indexes (0 scans) ---' SELECT schemaname, tablename, indexname, pg_size_pretty(pg_relation_size(indexrelid)) AS size FROM pg_stat_user_indexes WHERE idx_scan = 0 AND pg_relation_size(indexrelid) > 10 * 1024 * 1024 -- > 10 МБ ORDER BY pg_relation_size(indexrelid) DESC LIMIT 10; Глава 9. Новинки PostgreSQL 16/17/18PostgreSQL 16 (2023)Логическая репликация от standby — теперь можно публиковать изменения не только с primary, разгружая мастер. Параллельный COPY — загрузка данных через COPY стала параллельной. Улучшения планировщика для GROUP BY с параллелизмом. pg_stat_io — новая системная вьюшка для детальной статистики I/O: -- PostgreSQL 16+: детальная I/O статистика SELECT backend_type, object, context, reads, writes, extends, op_bytes, hits, evictions, reuses, fsyncs, read_time, write_time FROM pg_stat_io ORDER BY reads + writes DESC; -- Особенно полезно: сравнить hits vs reads для разных backend_type COPY FROM ... WHERE — фильтрация при загрузке данных: -- Загружаем только нужные строки COPY orders FROM '/tmp/orders.csv' CSV HEADER WHERE status = 'completed' AND total > 100; PostgreSQL 17 (2024)MERGE стал намного мощнее — поддержка RETURNING, DO NOTHING: -- PostgreSQL 17: MERGE с RETURNING MERGE INTO inventory AS target USING incoming_stock AS source ON target.product_id = source.product_id WHEN MATCHED THEN UPDATE SET quantity = target.quantity + source.quantity WHEN NOT MATCHED THEN INSERT (product_id, quantity) VALUES (source.product_id, source.quantity) RETURNING target.product_id, target.quantity, merge_action(); -- merge_action() → 'INSERT' или 'UPDATE' Incremental sorting улучшен — быстрее для DISTINCT и ORDER BY. pg_stat_statements получил toplevel — разделение top-level vs вложенных запросов. Vacuum improvements — улучшена скорость заморозки (freeze), меньше I/O. VACUUM (SKIP_DATABASE_STATS) — ускорение вакуума многих мелких таблиц. Размер WAL записей уменьшен — меньше I/O при интенсивной записи. PostgreSQL 18 (2025, в разработке / ранние беты)Встроенный асинхронный I/O (io_method = io_uring) — огромный прирост для NVMe SSD, особенно при высоком параллелизме: # postgresql.conf (PostgreSQL 18 при использовании Linux io_uring) io_method = io_uring # Дефолт: sync; альтернатива: worker Планировщик с ML-hints — работа над улучшением кардинальности оценок. GRANT/REVOKE для роли по умолчанию — улучшена система безопасности. Глава 10. Практические кейсы: реальные проблемы и их решенияКейс 1: «Запросы стали медленнее после VACUUM»-- Симптом: autovacuum отработал, но запросы стали медленнее. -- Причина: устаревшая статистика. VACUUM не обновляет статистику! -- Решение 1: Принудительный ANALYZE ANALYZE VERBOSE orders; -- Или для всей БД: -- vacuumdb --analyze-only --all -- Решение 2: Увеличить точность статистики для проблемных колонок ALTER TABLE orders ALTER COLUMN status SET STATISTICS 500, ALTER COLUMN region SET STATISTICS 500; ANALYZE orders; -- Проверить статистику после: SELECT attname, n_distinct, correlation FROM pg_stats WHERE tablename = 'orders' AND attname IN ('status', 'region', 'created_at'); Кейс 2: «Диск заполнился WAL файлами»-- Причина 1: Зависший логический слот репликации SELECT slot_name, active, wal_status, pg_size_pretty( pg_wal_lsn_diff(pg_current_wal_lsn(), restart_lsn) ) AS retained_wal FROM pg_replication_slots WHERE wal_status != 'reserved'; -- Если слот неактивен и держит WAL — удалить после согласования с командой: SELECT pg_drop_replication_slot('stale_slot_name'); -- Причина 2: archive_command не успевает -- Проверить: SELECT last_archived_wal, last_failed_wal, last_failed_time FROM pg_stat_archiver; -- Временная мера: уменьшить max_wal_size -- Постоянная: починить archive_command или увеличить место -- Причина 3: Слишком агрессивные checkpoint -- Уменьшить wal_keep_size если репликация живая Кейс 3: «Connection pool переполнен, приложение не может подключиться»-- Диагноз: смотрим pg_stat_activity SELECT state, count(*), left(query, 50) AS sample_query FROM pg_stat_activity WHERE datname = 'myapp_db' GROUP BY state, left(query, 50) ORDER BY count(*) DESC; -- Частая причина: idle in transaction (транзакция открыта и забыта) SELECT pid, now() - xact_start AS idle_duration, query FROM pg_stat_activity WHERE state = 'idle in transaction' AND now() - xact_start > INTERVAL '5 minutes' ORDER BY idle_duration DESC; -- Быстрое решение: убить зависшие idle in transaction SELECT pg_terminate_backend(pid) FROM pg_stat_activity WHERE state = 'idle in transaction' AND now() - xact_start > INTERVAL '10 minutes'; -- Постоянное решение: idle_in_transaction_session_timeout -- postgresql.conf: -- idle_in_transaction_session_timeout = 5min -- idle_session_timeout = 30min (PG 14+) Кейс 4: «Таблица растёт несмотря на DELETE»-- Table bloat: место от удалённых строк не возвращается OS. -- PostgreSQL помечает строки как "мёртвые", VACUUM освобождает их -- для ПОВТОРНОГО ИСПОЛЬЗОВАНИЯ, но не возвращает OS (кроме pg_toast). -- Проверить bloat: SELECT relname, pg_size_pretty(pg_total_relation_size(oid)) AS total_size, n_dead_tup, n_live_tup FROM pg_stat_user_tables JOIN pg_class USING (relid) WHERE relname = 'your_table'; -- Решение 1: VACUUM FULL (блокирует таблицу! Используйте в окно обслуживания) VACUUM FULL ANALYZE your_table; -- Решение 2: pg_repack (без блокировки!) -- Устанавливается отдельно: https://github.com/reorg/pg_repack -- pg_repack -d mydb -t your_table -- Решение 3: для партиционированных таблиц — просто удалить старую партицию -- ALTER TABLE events DETACH PARTITION events_2022_01; -- DROP TABLE events_2022_01; -- Мгновенное освобождение места! Заключение: чеклист production PostgreSQLКОНФИГУРАЦИЯ □ shared_buffers = 25-40% RAM □ effective_cache_size = 50-75% RAM □ work_mem настроен с учётом max_connections × parallel_workers □ random_page_cost = 1.1-1.5 для SSD/NVMe □ huge_pages = on (при shared_buffers > 8 ГБ, настроен в Linux) □ max_wal_size = 2-8 ГБ (зависит от нагрузки) □ wal_compression = lz4 (PG 15+) □ idle_in_transaction_session_timeout = 5min □ statement_timeout = установлен разумный лимит МОНИТОРИНГ □ pg_stat_statements включён и регулярно анализируется □ Алерт на cache hit ratio < 95% □ Алерт на replication lag > 60s □ Алерт на bloat > 30% для критичных таблиц □ Алерт на неактивные replication slots □ Ежедневный health check запрос AUTOVACUUM □ autovacuum_max_workers = 4-6 □ autovacuum_vacuum_cost_delay = 2ms (SSD) □ autovacuum_vacuum_cost_limit = 800-2000 □ Scale factor снижен для горячих таблиц □ Мониторинг n_dead_tup и xid_age СОЕДИНЕНИЯ □ PgBouncer в transaction mode □ max_connections ≤ 300 (больше — через пул) □ Настроен pool_size в PgBouncer □ Мониторинг cl_waiting в PgBouncer ИНДЕКСЫ □ Аудит неиспользуемых индексов (pg_stat_user_indexes) □ Составные индексы с правильным порядком колонок □ INCLUDE для покрывающих индексов □ BRIN для append-only больших таблиц РЕПЛИКАЦИЯ □ Мониторинг replay_lag □ Мониторинг pg_replication_slots на утечку WAL □ Проверка wal_status всех слотов □ hot_standby_feedback = on на репликах БЕЗОПАСНОСТЬ □ scram-sha-256 в pg_hba.conf □ Минимальные привилегии для каждого пользователя □ ssl = on + проверка сертификатов □ log_connections/log_disconnections для аудита PostgreSQL — невероятно мощная система, которая «из коробки» даёт примерно 20% своего потенциала. Правильная конфигурация, индексная стратегия и мониторинг превращают её в продукт, который выдерживает тысячи транзакций в секунду на десятках терабайт данных — без дорогостоящих «облачных» альтернатив. -
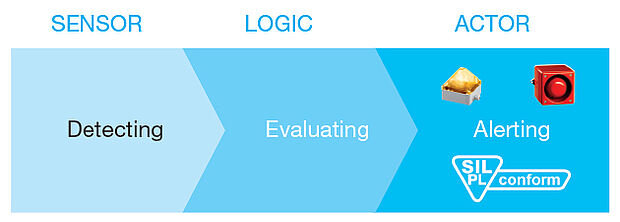 Почему функциональная безопасность — не формальностьТехасский Сити, 2005 год. Взрыв на нефтеперерабатывающем заводе BP. 15 погибших, 180 раненых, $1.5 млрд ущерба. Причина: переполнение ректификационной колонны — датчик уровня дал неверные показания, система безопасности не сработала. Бхопал, 1984 год. Утечка метилизоцианата. 3 787 погибших (официально), десятки тысяч раненых. Системы безопасности были отключены для экономии. Функциональная безопасность — это не бюрократия и не документация ради документации. Это инженерная дисциплина, которая систематически снижает вероятность того, что отказ автоматики приведёт к катастрофе. Базовые концепцииОпасность, риск, допустимый рискОпасность (Hazard): потенциальный источник вреда (горючий газ, высокое давление, токсичное вещество). Риск (Risk): комбинация вероятности события и его последствий: Риск = Вероятность × Тяжесть последствий Допустимый риск (Tolerable Risk): уровень риска, который общество считает приемлемым. Для промышленных объектов — обычно ≤10⁻⁵/год (один раз в 100 000 лет) для смертельного события. Независимые защитные слои (IPL — Independent Protection Layer)Принцип швейцарского сыра: ни один слой защиты не идеален, но несколько слоёв с отверстиями в разных местах надёжно блокируют опасность. Слой 1: Базовая система управления (BPCS) — ПЛК основной автоматики ↓ не сработала Слой 2: SIS (Safety Instrumented System) — независимая система безопасности ↓ не сработала Слой 3: Механические защиты — предохранительный клапан, разрывной диск ↓ не сработала Слой 4: Физические барьеры — обвалование, газоулавливающая система ↓ Катастрофа Каждый слой снижает риск в 10–1000 раз. Задача: снизить суммарный риск до допустимого уровня. Стандарты: IEC 61508 и его отраслевые производныеIEC 61508 — базовый стандарт функциональной безопасности для электрических/электронных/программируемых систем безопасности. 7 частей, охватывает весь жизненный цикл. Отраслевые стандарты (выводятся из 61508): IEC 61511 — нефтехимия, газ, химия (процессные установки) IEC 62061 — машиностроение EN 50128 / EN 50129 — железнодорожный транспорт IEC 60601 — медицинское оборудование DO-178C — авиационное ПО Уровни полноты безопасности (SIL)SIL (Safety Integrity Level) — дискретная мера целостности функции безопасности. Определяется вероятностью отказа при выполнении функции по требованию: SIL PFDavg (в режиме по требованию) PFH (в непрерывном режиме) Примеры SIL 1 10⁻² ... 10⁻¹ 10⁻⁶ ... 10⁻⁵ Простые защиты, блокировки SIL 2 10⁻³ ... 10⁻² 10⁻⁷ ... 10⁻⁶ Большинство промышленных SIS SIL 3 10⁻⁴ ... 10⁻³ 10⁻⁸ ... 10⁻⁷ Нефтегаз, ядерная энергетика SIL 4 10⁻⁵ ... 10⁻⁴ 10⁻⁹ ... 10⁻⁸ Ядерная энергетика (редко) PFDavg — средняя вероятность отказа в режиме ожидания (датчик не сработал когда нужно). PFH — частота опасных отказов в час (для непрерывных защит). Расчёт SIL: упрощённый подходОпределение требуемого SIL — через LOPA (Layer of Protection Analysis): Пример: высокое давление в реакторе может привести к взрыву Частота инициирующего события: 0.1 /год (раз в 10 лет, типично для BPCS) Вероятность последствий без защит: 1.0 (взрыв неизбежен) Тяжесть: катастрофическая (несколько погибших) Допустимый риск: 10⁻⁵ /год Требуемое снижение риска: RRF = Частота × Вероятность / Допустимый риск RRF = 0.1 × 1.0 / 10⁻⁵ = 10 000 LOPA уже учитывает другие IPL (предохранительный клапан, оператор): - Предохранительный клапан: снижение в 100 раз (PFD = 0.01) - Независимый алярм оператора: снижение в 10 раз Оставшийся RRF для SIS: 10 000 / (100 × 10) = 10 PFD_SIS = 1/10 = 0.1 → SIL 1 (10⁻² ... 10⁻¹) Если предохранительного клапана нет: PFD_SIS = 0.001 → SIL 2 Архитектура Safety Instrumented SystemТиповая SIS архитектура для SIL 2: Датчики (1oo2 или 2oo3) │ [Логический решатель — Safety PLC] │ Исполнительные устройства (финальные элементы) 1oo1: один из одного — нет резервирования (SIL 1) 1oo2: один из двух — высокая готовность, ложные срабатывания 2oo2: два из двух — низкая доступность к опасности, ложные отказы 2oo3: два из трёх — оптимальный баланс (SIL 2-3) Для SIL 2 часто используют: - Датчики: 1oo2D (один из двух с диагностикой) или 2oo3 - Logic Solver: 1oo1D (один с диагностикой) или 1oo2 - Финальные элементы: 1oo1 (один клапан) или 1oo2 (два параллельных) Safety PLC: ключевые отличия от обычных ПЛКSafety PLC (FS-PLC — Fail-Safe PLC) — это не просто обычный ПЛК с "безопасным" лейблом. Конструктивные отличия: Аппаратные: Двойное/тройное резервирование процессора Непрерывная взаимная проверка процессоров (cross-checking) Ошибка → переход в безопасное состояние (обычно: все выходы = 0) Диагностика: обнаружение > 99% опасных отказов (DC — Diagnostic Coverage) Специальные I/O модули с самодиагностикой Программные: Память программы верифицирована (CRC/хэш) Данные хранятся дважды или с кодом исправления ошибок Принцип fail-safe: при любой неопределённости → безопасное состояние Ограниченный набор инструкций (только сертифицированные блоки) Популярные Safety PLC: Siemens SIMATIC S7-300F / S7-400F / S7-1500F Rockwell Allen-Bradley GuardLogix 5580 Schneider Modicon M580 Safety ABB AC500-S Pilz PSS 4000 Программирование Safety PLC: особенностиНа примере Siemens S7-1500F + TIA Portal Safety: Ключевые принципы программирования Safety: 1. Fail-safe блоки (FB) vs Standard блоки - Безопасный код должен использовать ТОЛЬКО сертифицированные F-блоки - Смешивание: Standard → F OK; F → Standard НЕЛЬЗЯ без копирования 2. F-Signature: каждый F-блок имеет уникальную подпись - Изменение любого бита → другая подпись → требует повторной верификации 3. Consistent data transfer: - При передаче данных между F и Standard зонами — специальная процедура - Данные защищены от случайного изменения 4. Passivation: при ошибке датчика — F-код устанавливает безопасное значение (0 или FALSE) - Программа должна обрабатывать пассивацию явно! (* Пример F-программы на Structured Text (S7-1500F / TIA Portal) *) (* Функция безопасности: аварийная остановка при высоком давлении *) FUNCTION_BLOCK FB_PressureShutdown VAR_INPUT PressureHigh_1 : BOOL; // Датчик высокого давления 1 (активен = HIGH) PressureHigh_2 : BOOL; // Датчик высокого давления 2 (резервный) EStop_1 : BOOL; // Кнопка аварийной остановки 1 EStop_2 : BOOL; // Кнопка аварийной остановки 2 Reset : BOOL; // Сброс защиты (после устранения причины) // Каналы датчиков (после F_DI блока) CH_Pressure_1 : BOOL; // TRUE = канал исправен CH_Pressure_2 : BOOL; CH_EStop_1 : BOOL; CH_EStop_2 : BOOL; END_VAR VAR_OUTPUT ShutdownCommand : BOOL; // TRUE = закрыть клапан, остановить насосы AlarmActive : BOOL; // TRUE = авария активна AlarmCode : INT; // Код аварии ReadyToReset : BOOL; // Можно сбросить (причина устранена) END_VAR VAR Trip_Pressure : BOOL; Trip_EStop : BOOL; Trip_ChannelFault : BOOL; TripLatch : SR; // SR-триггер (Set-Reset) END_VAR (* Анализ датчиков давления (1oo2 логика) *) (* Срабатывание при ЛЮБОМ из двух датчиков *) Trip_Pressure := (PressureHigh_1 AND CH_Pressure_1) OR (PressureHigh_2 AND CH_Pressure_2); (* Кнопка аварийной остановки (2oo2 логика для предотвращения ложных срабатываний) *) (* Исправный канал при нажатой кнопке EStop: NC контакт → LOW *) Trip_EStop := (NOT EStop_1 AND CH_EStop_1) OR (NOT EStop_2 AND CH_EStop_2); (* Отказ канала датчика = безопасное состояние (принцип fail-safe) *) Trip_ChannelFault := NOT CH_Pressure_1 OR NOT CH_Pressure_2 OR NOT CH_EStop_1 OR NOT CH_EStop_2; (* Защёлка аварии: Set при любой причине, Reset только при явном сбросе *) TripLatch( SET1 := Trip_Pressure OR Trip_EStop OR Trip_ChannelFault, RESET := Reset AND NOT (Trip_Pressure OR Trip_EStop OR Trip_ChannelFault) (* Нельзя сбросить пока причина активна! *) ); ShutdownCommand := TripLatch.Q1; AlarmActive := ShutdownCommand; (* Определяем код аварии *) IF Trip_ChannelFault THEN AlarmCode := 3; (* Наивысший приоритет: отказ диагностики *) ELSIF Trip_EStop THEN AlarmCode := 2; ELSIF Trip_Pressure THEN AlarmCode := 1; ELSE AlarmCode := 0; END_IF; (* Условие готовности к сбросу *) ReadyToReset := AlarmActive AND NOT Trip_Pressure AND NOT Trip_EStop AND NOT Trip_ChannelFault; END_FUNCTION_BLOCK Финальные элементы: клапаны и их диагностикаФинальный элемент (обычно отсечной клапан) — самое слабое место SIS. Клапан может "прикипеть" в открытом положении — и не закроется по команде. Диагностика финальных элементов: Частичное хождение клапана (Partial Valve Stroke Test, PVST): - Раз в 3-6 месяцев в рабочем режиме - Клапан закрывается на 10-15% от полного хода - Проверяется отклик (позиционер, время отклика) - Полное закрытие не происходит → нет нарушения производства - Сокращает интервал плановой проверки → снижает PFD Полная проверка (Full Stroke Test): - При плановом останове (раз в год или реже) - Полное закрытие, замер времени - Проверка концевых выключателей def calculate_pfd_valve_with_pvst( pfd_full_stroke: float, # PFD без диагностики pvst_coverage: float, # Покрытие диагностикой PVST (обычно 0.6-0.8) pvst_interval_months: int, # Интервал PVST full_test_interval_years: int # Интервал полной проверки ) -> dict: """ Расчёт PFD финального элемента с учётом PVST. Упрощённая модель (для точного расчёта — IEC 61511-1 Annex K). """ # Частота опасных отказов (из datasheet производителя или OREDA) # Например, для шарового клапана DN100: lambda_D ≈ 1e-6 /час lambda_d = pfd_full_stroke / (full_test_interval_years * 8760 / 2) # PFD без PVST (только полная проверка раз в год) pfd_no_pvst = lambda_d * full_test_interval_years * 8760 / 2 # PFD с PVST: диагностика снижает эффективный интервал # PFD_pvst ≈ PFD_full × (1 - DC_pvst) + PFD_full × DC_pvst × (Ti_pvst/Ti_full) pvst_interval_years = pvst_interval_months / 12 pfd_with_pvst = (pfd_no_pvst * (1 - pvst_coverage) + pfd_no_pvst * pvst_coverage * (pvst_interval_years / full_test_interval_years)) reduction_factor = pfd_no_pvst / pfd_with_pvst if pfd_with_pvst > 0 else 1 return { 'pfd_without_pvst': round(pfd_no_pvst, 6), 'pfd_with_pvst': round(pfd_with_pvst, 6), 'reduction_factor': round(reduction_factor, 1), 'sil_without_pvst': 1 if pfd_no_pvst >= 1e-2 else 2 if pfd_no_pvst >= 1e-3 else 3, 'sil_with_pvst': 1 if pfd_with_pvst >= 1e-2 else 2 if pfd_with_pvst >= 1e-3 else 3, } # Пример расчёта: result = calculate_pfd_valve_with_pvst( pfd_full_stroke = 0.01, # PFD при ежегодном тестировании = SIL 1 pvst_coverage = 0.7, # PVST выявляет 70% опасных отказов pvst_interval_months = 3, # PVST раз в квартал full_test_interval_years = 1 ) print(f"PFD без PVST: {result['pfd_without_pvst']} (SIL {result['sil_without_pvst']})") print(f"PFD с PVST: {result['pfd_with_pvst']} (SIL {result['sil_with_pvst']})") print(f"Снижение PFD: в {result['reduction_factor']} раз") Жизненный цикл SIS: от концепции до вывода из эксплуатацииПо IEC 61511, жизненный цикл SIS включает 16 фаз: Фаза 1-4: Анализ 1. Анализ опасностей (HAZOP) 2. Оценка рисков (SIL Determination / LOPA) 3. Концепция безопасности 4. Требования к SIS (SRS — Safety Requirements Specification) Фаза 5-9: Проектирование 5. Архитектура SIS 6. Выбор оборудования 7. Проектирование F-программы 8. Factory Acceptance Test (FAT) 9. Site Acceptance Test (SAT) Фаза 10-13: Эксплуатация 10. Ввод в эксплуатацию 11. Плановое техническое обслуживание 12. Периодическое функциональное тестирование (Proof Test) 13. Управление изменениями (MOC — Management of Change) Фаза 14-16: Завершение 14. Вывод из эксплуатации 15. Оценка соответствия (SIL Verification) 16. Функциональная оценка (Functional Safety Assessment) HAZOP: анализ опасностей и работоспособностиHAZOP (Hazard and Operability Study) — методология анализа, где команда экспертов применяет "направляющие слова" к каждому параметру процесса: Направляющие слова × Параметры → Отклонения → Последствия → Защиты Параметры: расход, температура, давление, уровень, состав, время Направляющие слова: Нет, Больше, Меньше, Другое, Обратное, Часть Примеры: "Нет расхода" → охладитель не подаётся → перегрев реактора → взрыв Защита: датчик расхода + BPCS блокировка; SIS ESD; предохранительный клапан "Больше давления" → разрыв оборудования → утечка газа → взрыв/пожар Защита: HS датчик давления + SIS; предохранительный клапан на 120% рабочего "Обратный поток" → смешение несовместимых реагентов Защита: обратный клапан; двойная задвижка с блоком (Double Block & Bleed) Практические советы по SIS-проектам1. Независимость — не просто разные ПЛК Датчики SIS и BPCS должны быть на РАЗНЫХ отборах давления/температуры, разных кабелях, разных шинах питания. Один кабельный канал для обоих = нет независимости. 2. Воздействие оператора — только через стандартный HMI Обход (bypass) защиты — только физический (байпасный выключатель), с аудитом и процедурой. Никакого программного обхода через меню! 3. Документируйте каждое изменение через MOC Изменение уставки датчика, замена компонента, изменение программы — всё через официальную процедуру управления изменениями. Иначе следующий HAZOP или audit найдёт несоответствие. 4. Proof Test — проводите регулярно и документируйте PFD рассчитан на конкретный интервал тестирования. Пропустили proof test — ваш SIL больше не действителен формально (и реально выше PFD). ЗаключениеФункциональная безопасность — это та область, где нет места импровизации. Стандарты IEC 61508/61511 написаны на основе реальных промышленных катастроф и содержат выверенные методологии. Для старта: изучите IEC 61511 (он ориентирован на процессные установки и более практичный, чем базовый 61508). Пройдите курс TÜV Rheinland или TÜV SÜD по Functional Safety Engineer — они дают систематическое понимание и признаваемый сертификат. И помните: в функциональной безопасности "достаточно хорошо" и "почти правильно" не существует. Либо соответствует SIL, либо нет. Промежуточных значений нет.
Почему функциональная безопасность — не формальностьТехасский Сити, 2005 год. Взрыв на нефтеперерабатывающем заводе BP. 15 погибших, 180 раненых, $1.5 млрд ущерба. Причина: переполнение ректификационной колонны — датчик уровня дал неверные показания, система безопасности не сработала. Бхопал, 1984 год. Утечка метилизоцианата. 3 787 погибших (официально), десятки тысяч раненых. Системы безопасности были отключены для экономии. Функциональная безопасность — это не бюрократия и не документация ради документации. Это инженерная дисциплина, которая систематически снижает вероятность того, что отказ автоматики приведёт к катастрофе. Базовые концепцииОпасность, риск, допустимый рискОпасность (Hazard): потенциальный источник вреда (горючий газ, высокое давление, токсичное вещество). Риск (Risk): комбинация вероятности события и его последствий: Риск = Вероятность × Тяжесть последствий Допустимый риск (Tolerable Risk): уровень риска, который общество считает приемлемым. Для промышленных объектов — обычно ≤10⁻⁵/год (один раз в 100 000 лет) для смертельного события. Независимые защитные слои (IPL — Independent Protection Layer)Принцип швейцарского сыра: ни один слой защиты не идеален, но несколько слоёв с отверстиями в разных местах надёжно блокируют опасность. Слой 1: Базовая система управления (BPCS) — ПЛК основной автоматики ↓ не сработала Слой 2: SIS (Safety Instrumented System) — независимая система безопасности ↓ не сработала Слой 3: Механические защиты — предохранительный клапан, разрывной диск ↓ не сработала Слой 4: Физические барьеры — обвалование, газоулавливающая система ↓ Катастрофа Каждый слой снижает риск в 10–1000 раз. Задача: снизить суммарный риск до допустимого уровня. Стандарты: IEC 61508 и его отраслевые производныеIEC 61508 — базовый стандарт функциональной безопасности для электрических/электронных/программируемых систем безопасности. 7 частей, охватывает весь жизненный цикл. Отраслевые стандарты (выводятся из 61508): IEC 61511 — нефтехимия, газ, химия (процессные установки) IEC 62061 — машиностроение EN 50128 / EN 50129 — железнодорожный транспорт IEC 60601 — медицинское оборудование DO-178C — авиационное ПО Уровни полноты безопасности (SIL)SIL (Safety Integrity Level) — дискретная мера целостности функции безопасности. Определяется вероятностью отказа при выполнении функции по требованию: SIL PFDavg (в режиме по требованию) PFH (в непрерывном режиме) Примеры SIL 1 10⁻² ... 10⁻¹ 10⁻⁶ ... 10⁻⁵ Простые защиты, блокировки SIL 2 10⁻³ ... 10⁻² 10⁻⁷ ... 10⁻⁶ Большинство промышленных SIS SIL 3 10⁻⁴ ... 10⁻³ 10⁻⁸ ... 10⁻⁷ Нефтегаз, ядерная энергетика SIL 4 10⁻⁵ ... 10⁻⁴ 10⁻⁹ ... 10⁻⁸ Ядерная энергетика (редко) PFDavg — средняя вероятность отказа в режиме ожидания (датчик не сработал когда нужно). PFH — частота опасных отказов в час (для непрерывных защит). Расчёт SIL: упрощённый подходОпределение требуемого SIL — через LOPA (Layer of Protection Analysis): Пример: высокое давление в реакторе может привести к взрыву Частота инициирующего события: 0.1 /год (раз в 10 лет, типично для BPCS) Вероятность последствий без защит: 1.0 (взрыв неизбежен) Тяжесть: катастрофическая (несколько погибших) Допустимый риск: 10⁻⁵ /год Требуемое снижение риска: RRF = Частота × Вероятность / Допустимый риск RRF = 0.1 × 1.0 / 10⁻⁵ = 10 000 LOPA уже учитывает другие IPL (предохранительный клапан, оператор): - Предохранительный клапан: снижение в 100 раз (PFD = 0.01) - Независимый алярм оператора: снижение в 10 раз Оставшийся RRF для SIS: 10 000 / (100 × 10) = 10 PFD_SIS = 1/10 = 0.1 → SIL 1 (10⁻² ... 10⁻¹) Если предохранительного клапана нет: PFD_SIS = 0.001 → SIL 2 Архитектура Safety Instrumented SystemТиповая SIS архитектура для SIL 2: Датчики (1oo2 или 2oo3) │ [Логический решатель — Safety PLC] │ Исполнительные устройства (финальные элементы) 1oo1: один из одного — нет резервирования (SIL 1) 1oo2: один из двух — высокая готовность, ложные срабатывания 2oo2: два из двух — низкая доступность к опасности, ложные отказы 2oo3: два из трёх — оптимальный баланс (SIL 2-3) Для SIL 2 часто используют: - Датчики: 1oo2D (один из двух с диагностикой) или 2oo3 - Logic Solver: 1oo1D (один с диагностикой) или 1oo2 - Финальные элементы: 1oo1 (один клапан) или 1oo2 (два параллельных) Safety PLC: ключевые отличия от обычных ПЛКSafety PLC (FS-PLC — Fail-Safe PLC) — это не просто обычный ПЛК с "безопасным" лейблом. Конструктивные отличия: Аппаратные: Двойное/тройное резервирование процессора Непрерывная взаимная проверка процессоров (cross-checking) Ошибка → переход в безопасное состояние (обычно: все выходы = 0) Диагностика: обнаружение > 99% опасных отказов (DC — Diagnostic Coverage) Специальные I/O модули с самодиагностикой Программные: Память программы верифицирована (CRC/хэш) Данные хранятся дважды или с кодом исправления ошибок Принцип fail-safe: при любой неопределённости → безопасное состояние Ограниченный набор инструкций (только сертифицированные блоки) Популярные Safety PLC: Siemens SIMATIC S7-300F / S7-400F / S7-1500F Rockwell Allen-Bradley GuardLogix 5580 Schneider Modicon M580 Safety ABB AC500-S Pilz PSS 4000 Программирование Safety PLC: особенностиНа примере Siemens S7-1500F + TIA Portal Safety: Ключевые принципы программирования Safety: 1. Fail-safe блоки (FB) vs Standard блоки - Безопасный код должен использовать ТОЛЬКО сертифицированные F-блоки - Смешивание: Standard → F OK; F → Standard НЕЛЬЗЯ без копирования 2. F-Signature: каждый F-блок имеет уникальную подпись - Изменение любого бита → другая подпись → требует повторной верификации 3. Consistent data transfer: - При передаче данных между F и Standard зонами — специальная процедура - Данные защищены от случайного изменения 4. Passivation: при ошибке датчика — F-код устанавливает безопасное значение (0 или FALSE) - Программа должна обрабатывать пассивацию явно! (* Пример F-программы на Structured Text (S7-1500F / TIA Portal) *) (* Функция безопасности: аварийная остановка при высоком давлении *) FUNCTION_BLOCK FB_PressureShutdown VAR_INPUT PressureHigh_1 : BOOL; // Датчик высокого давления 1 (активен = HIGH) PressureHigh_2 : BOOL; // Датчик высокого давления 2 (резервный) EStop_1 : BOOL; // Кнопка аварийной остановки 1 EStop_2 : BOOL; // Кнопка аварийной остановки 2 Reset : BOOL; // Сброс защиты (после устранения причины) // Каналы датчиков (после F_DI блока) CH_Pressure_1 : BOOL; // TRUE = канал исправен CH_Pressure_2 : BOOL; CH_EStop_1 : BOOL; CH_EStop_2 : BOOL; END_VAR VAR_OUTPUT ShutdownCommand : BOOL; // TRUE = закрыть клапан, остановить насосы AlarmActive : BOOL; // TRUE = авария активна AlarmCode : INT; // Код аварии ReadyToReset : BOOL; // Можно сбросить (причина устранена) END_VAR VAR Trip_Pressure : BOOL; Trip_EStop : BOOL; Trip_ChannelFault : BOOL; TripLatch : SR; // SR-триггер (Set-Reset) END_VAR (* Анализ датчиков давления (1oo2 логика) *) (* Срабатывание при ЛЮБОМ из двух датчиков *) Trip_Pressure := (PressureHigh_1 AND CH_Pressure_1) OR (PressureHigh_2 AND CH_Pressure_2); (* Кнопка аварийной остановки (2oo2 логика для предотвращения ложных срабатываний) *) (* Исправный канал при нажатой кнопке EStop: NC контакт → LOW *) Trip_EStop := (NOT EStop_1 AND CH_EStop_1) OR (NOT EStop_2 AND CH_EStop_2); (* Отказ канала датчика = безопасное состояние (принцип fail-safe) *) Trip_ChannelFault := NOT CH_Pressure_1 OR NOT CH_Pressure_2 OR NOT CH_EStop_1 OR NOT CH_EStop_2; (* Защёлка аварии: Set при любой причине, Reset только при явном сбросе *) TripLatch( SET1 := Trip_Pressure OR Trip_EStop OR Trip_ChannelFault, RESET := Reset AND NOT (Trip_Pressure OR Trip_EStop OR Trip_ChannelFault) (* Нельзя сбросить пока причина активна! *) ); ShutdownCommand := TripLatch.Q1; AlarmActive := ShutdownCommand; (* Определяем код аварии *) IF Trip_ChannelFault THEN AlarmCode := 3; (* Наивысший приоритет: отказ диагностики *) ELSIF Trip_EStop THEN AlarmCode := 2; ELSIF Trip_Pressure THEN AlarmCode := 1; ELSE AlarmCode := 0; END_IF; (* Условие готовности к сбросу *) ReadyToReset := AlarmActive AND NOT Trip_Pressure AND NOT Trip_EStop AND NOT Trip_ChannelFault; END_FUNCTION_BLOCK Финальные элементы: клапаны и их диагностикаФинальный элемент (обычно отсечной клапан) — самое слабое место SIS. Клапан может "прикипеть" в открытом положении — и не закроется по команде. Диагностика финальных элементов: Частичное хождение клапана (Partial Valve Stroke Test, PVST): - Раз в 3-6 месяцев в рабочем режиме - Клапан закрывается на 10-15% от полного хода - Проверяется отклик (позиционер, время отклика) - Полное закрытие не происходит → нет нарушения производства - Сокращает интервал плановой проверки → снижает PFD Полная проверка (Full Stroke Test): - При плановом останове (раз в год или реже) - Полное закрытие, замер времени - Проверка концевых выключателей def calculate_pfd_valve_with_pvst( pfd_full_stroke: float, # PFD без диагностики pvst_coverage: float, # Покрытие диагностикой PVST (обычно 0.6-0.8) pvst_interval_months: int, # Интервал PVST full_test_interval_years: int # Интервал полной проверки ) -> dict: """ Расчёт PFD финального элемента с учётом PVST. Упрощённая модель (для точного расчёта — IEC 61511-1 Annex K). """ # Частота опасных отказов (из datasheet производителя или OREDA) # Например, для шарового клапана DN100: lambda_D ≈ 1e-6 /час lambda_d = pfd_full_stroke / (full_test_interval_years * 8760 / 2) # PFD без PVST (только полная проверка раз в год) pfd_no_pvst = lambda_d * full_test_interval_years * 8760 / 2 # PFD с PVST: диагностика снижает эффективный интервал # PFD_pvst ≈ PFD_full × (1 - DC_pvst) + PFD_full × DC_pvst × (Ti_pvst/Ti_full) pvst_interval_years = pvst_interval_months / 12 pfd_with_pvst = (pfd_no_pvst * (1 - pvst_coverage) + pfd_no_pvst * pvst_coverage * (pvst_interval_years / full_test_interval_years)) reduction_factor = pfd_no_pvst / pfd_with_pvst if pfd_with_pvst > 0 else 1 return { 'pfd_without_pvst': round(pfd_no_pvst, 6), 'pfd_with_pvst': round(pfd_with_pvst, 6), 'reduction_factor': round(reduction_factor, 1), 'sil_without_pvst': 1 if pfd_no_pvst >= 1e-2 else 2 if pfd_no_pvst >= 1e-3 else 3, 'sil_with_pvst': 1 if pfd_with_pvst >= 1e-2 else 2 if pfd_with_pvst >= 1e-3 else 3, } # Пример расчёта: result = calculate_pfd_valve_with_pvst( pfd_full_stroke = 0.01, # PFD при ежегодном тестировании = SIL 1 pvst_coverage = 0.7, # PVST выявляет 70% опасных отказов pvst_interval_months = 3, # PVST раз в квартал full_test_interval_years = 1 ) print(f"PFD без PVST: {result['pfd_without_pvst']} (SIL {result['sil_without_pvst']})") print(f"PFD с PVST: {result['pfd_with_pvst']} (SIL {result['sil_with_pvst']})") print(f"Снижение PFD: в {result['reduction_factor']} раз") Жизненный цикл SIS: от концепции до вывода из эксплуатацииПо IEC 61511, жизненный цикл SIS включает 16 фаз: Фаза 1-4: Анализ 1. Анализ опасностей (HAZOP) 2. Оценка рисков (SIL Determination / LOPA) 3. Концепция безопасности 4. Требования к SIS (SRS — Safety Requirements Specification) Фаза 5-9: Проектирование 5. Архитектура SIS 6. Выбор оборудования 7. Проектирование F-программы 8. Factory Acceptance Test (FAT) 9. Site Acceptance Test (SAT) Фаза 10-13: Эксплуатация 10. Ввод в эксплуатацию 11. Плановое техническое обслуживание 12. Периодическое функциональное тестирование (Proof Test) 13. Управление изменениями (MOC — Management of Change) Фаза 14-16: Завершение 14. Вывод из эксплуатации 15. Оценка соответствия (SIL Verification) 16. Функциональная оценка (Functional Safety Assessment) HAZOP: анализ опасностей и работоспособностиHAZOP (Hazard and Operability Study) — методология анализа, где команда экспертов применяет "направляющие слова" к каждому параметру процесса: Направляющие слова × Параметры → Отклонения → Последствия → Защиты Параметры: расход, температура, давление, уровень, состав, время Направляющие слова: Нет, Больше, Меньше, Другое, Обратное, Часть Примеры: "Нет расхода" → охладитель не подаётся → перегрев реактора → взрыв Защита: датчик расхода + BPCS блокировка; SIS ESD; предохранительный клапан "Больше давления" → разрыв оборудования → утечка газа → взрыв/пожар Защита: HS датчик давления + SIS; предохранительный клапан на 120% рабочего "Обратный поток" → смешение несовместимых реагентов Защита: обратный клапан; двойная задвижка с блоком (Double Block & Bleed) Практические советы по SIS-проектам1. Независимость — не просто разные ПЛК Датчики SIS и BPCS должны быть на РАЗНЫХ отборах давления/температуры, разных кабелях, разных шинах питания. Один кабельный канал для обоих = нет независимости. 2. Воздействие оператора — только через стандартный HMI Обход (bypass) защиты — только физический (байпасный выключатель), с аудитом и процедурой. Никакого программного обхода через меню! 3. Документируйте каждое изменение через MOC Изменение уставки датчика, замена компонента, изменение программы — всё через официальную процедуру управления изменениями. Иначе следующий HAZOP или audit найдёт несоответствие. 4. Proof Test — проводите регулярно и документируйте PFD рассчитан на конкретный интервал тестирования. Пропустили proof test — ваш SIL больше не действителен формально (и реально выше PFD). ЗаключениеФункциональная безопасность — это та область, где нет места импровизации. Стандарты IEC 61508/61511 написаны на основе реальных промышленных катастроф и содержат выверенные методологии. Для старта: изучите IEC 61511 (он ориентирован на процессные установки и более практичный, чем базовый 61508). Пройдите курс TÜV Rheinland или TÜV SÜD по Functional Safety Engineer — они дают систематическое понимание и признаваемый сертификат. И помните: в функциональной безопасности "достаточно хорошо" и "почти правильно" не существует. Либо соответствует SIL, либо нет. Промежуточных значений нет. -
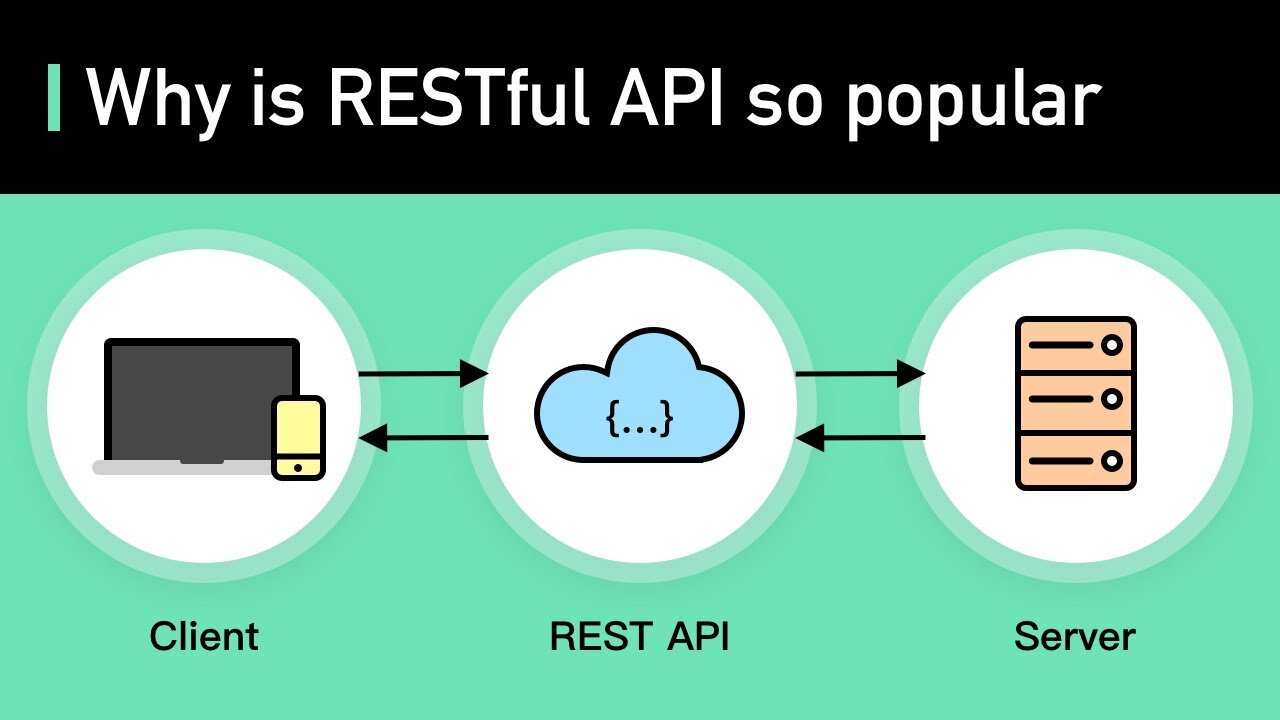 REST: не просто "HTTP + JSON"REST (Representational State Transfer) — архитектурный стиль, описанный Роем Филдингом в 2000 году. Большинство "REST API" в реальности — это RPC поверх HTTP (CRUD по URL). Настоящий REST имеет шесть ограничений, из которых на практике применяют три-четыре. Но это не важно. Важно проектировать API, которым приятно пользоваться: предсказуемым, документированным, обрабатывающим ошибки правильно, безопасным и масштабируемым. Дизайн URL: основные принципыПринципы именования ресурсов:✅ Существительные во множественном числе: /api/v1/devices /api/v1/devices/42 /api/v1/devices/42/sensors /api/v1/devices/42/sensors/7/readings ❌ Глаголы в URL: /api/v1/getDevices ← нет! /api/v1/createDevice ← нет! /api/v1/device/42/delete ← нет! Действие выражается HTTP-методом: GET /devices → список устройств POST /devices → создать устройство GET /devices/42 → получить устройство 42 PUT /devices/42 → полностью заменить устройство 42 PATCH /devices/42 → частично обновить устройство 42 DELETE /devices/42 → удалить устройство 42 Вложенность — для зависимых ресурсов: GET /devices/42/sensors → датчики устройства 42 POST /devices/42/sensors → добавить датчик к устройству 42 GET /devices/42/sensors/7 → конкретный датчик DELETE /devices/42/sensors/7 → удалить датчик Максимум 3 уровня вложенности! Глубже — smell. HTTP методы и их семантикаМетод Идемпотентный Безопасный Применение GET ✅ ✅ Получение данных POST ❌ ❌ Создание, не-идемпотентные действия PUT ✅ ❌ Полная замена ресурса PATCH ❌* ❌ Частичное обновление DELETE ✅ ❌ Удаление HEAD ✅ ✅ Получение заголовков без тела OPTIONS ✅ ✅ CORS preflight, capabilities Идемпотентность: повторный вызов даёт тот же результат. PUT /devices/42 с одними данными можно вызвать 100 раз — результат одинаковый. DELETE /devices/42 — тоже (второй вызов: 404, но ресурс всё равно удалён). Коды состояния HTTP: правильное использование2xx — Успех: 200 OK — GET, PUT, PATCH успешно 201 Created — POST создал ресурс; Location: /api/v1/devices/43 204 No Content — DELETE, PATCH без возврата данных 3xx — Перенаправление: 301 Moved Permanently — ресурс переехал навсегда 304 Not Modified — кешированный ответ актуален (ETag/If-None-Match) 4xx — Ошибка клиента: 400 Bad Request — невалидные данные запроса 401 Unauthorized — не аутентифицирован (нет или неверный токен) 403 Forbidden — аутентифицирован, но нет прав 404 Not Found — ресурс не существует 405 Method Not Allowed— метод не поддерживается для этого URL 409 Conflict — конфликт (дубликат, версионирование) 422 Unprocessable — синтаксически корректный JSON, но семантически неверный 429 Too Many Requests — rate limit превышен 5xx — Ошибка сервера: 500 Internal Server Error — непредвиденная ошибка 503 Service Unavailable — временно недоступен (maintenance, overload) Структура ответов: единообразие обязательно# Стандартизированный формат ответа # Успешный список с пагинацией: { "data": [ {"id": 1, "name": "Насос 1", "status": "active"}, {"id": 2, "name": "Насос 2", "status": "fault"} ], "meta": { "total": 48, "page": 2, "page_size": 10, "pages": 5, "next": "/api/v1/devices?page=3&page_size=10", "prev": "/api/v1/devices?page=1&page_size=10" } } # Единичный объект: { "data": { "id": 42, "name": "Насос холодной воды", "location": "Котельная", "created_at": "2024-01-15T10:30:00Z", "updated_at": "2024-03-10T08:45:22Z" } } # Ошибка (ВСЕГДА одна структура!): { "error": { "code": "VALIDATION_ERROR", "message": "Ошибка валидации входных данных", "details": [ { "field": "temperature_max", "message": "Значение должно быть больше temperature_min" }, { "field": "device_id", "message": "Устройство с таким ID не существует" } ], "request_id": "req_abc123xyz", "timestamp": "2024-03-15T14:22:33Z" } } FastAPI: production-ready API за минуты# main.py from fastapi import FastAPI, HTTPException, Depends, Query, Path, status from fastapi.middleware.cors import CORSMiddleware from fastapi.middleware.gzip import GZipMiddleware from fastapi.responses import JSONResponse from pydantic import BaseModel, Field, validator from typing import Optional, List from datetime import datetime import uuid app = FastAPI( title="Industrial IoT API", description="API управления промышленными устройствами", version="1.0.0", docs_url="/api/docs", # Swagger UI redoc_url="/api/redoc", # ReDoc openapi_url="/api/openapi.json" ) # Middleware app.add_middleware(GZipMiddleware, minimum_size=1000) app.add_middleware( CORSMiddleware, allow_origins=["https://dashboard.factory.com"], allow_methods=["GET", "POST", "PUT", "PATCH", "DELETE"], allow_headers=["Authorization", "Content-Type", "X-Request-ID"], ) # ===== МОДЕЛИ ===== class DeviceStatus(str): ACTIVE = "active" INACTIVE = "inactive" FAULT = "fault" MAINTENANCE = "maintenance" class DeviceBase(BaseModel): name: str = Field(..., min_length=1, max_length=100, example="Насос 1") location: str = Field(..., example="Котельная") model: str = Field(..., example="Grundfos CM5-5") tags: List[str] = Field(default=[], example=["pump", "cooling"]) class DeviceCreate(DeviceBase): pass class DeviceUpdate(BaseModel): name: Optional[str] = Field(None, min_length=1, max_length=100) location: Optional[str] = None status: Optional[str] = None tags: Optional[List[str]] = None class DeviceResponse(DeviceBase): id: int status: str = "active" created_at: datetime updated_at: datetime class Config: from_attributes = True class PaginatedResponse(BaseModel): data: List[DeviceResponse] meta: dict # ===== ЗАВИСИМОСТИ ===== # Имитация БД fake_db = {} device_counter = 0 def get_device_or_404(device_id: int = Path(..., ge=1)) -> dict: device = fake_db.get(device_id) if not device: raise HTTPException( status_code=status.HTTP_404_NOT_FOUND, detail={ "error": { "code": "DEVICE_NOT_FOUND", "message": f"Устройство с ID {device_id} не найдено", "request_id": str(uuid.uuid4()) } } ) return device # ===== ENDPOINTS ===== @app.get( "/api/v1/devices", response_model=PaginatedResponse, summary="Список устройств", tags=["Devices"] ) async def list_devices( page: int = Query(default=1, ge=1, description="Номер страницы"), page_size: int = Query(default=20, ge=1, le=100, description="Размер страницы"), status: Optional[str] = Query(default=None, description="Фильтр по статусу"), search: Optional[str] = Query(default=None, description="Поиск по имени"), sort_by: str = Query(default="created_at", description="Поле сортировки"), sort_desc: bool = Query(default=True, description="По убыванию"), ): """ Возвращает список устройств с пагинацией и фильтрацией. - **page**: страница (начиная с 1) - **page_size**: количество на странице (макс. 100) - **status**: фильтр по статусу (active, inactive, fault, maintenance) - **search**: поиск по имени и местоположению """ # Имитация запроса к БД all_devices = list(fake_db.values()) if status: all_devices = [d for d in all_devices if d.get("status") == status] if search: q = search.lower() all_devices = [d for d in all_devices if q in d.get("name", "").lower() or q in d.get("location", "").lower()] total = len(all_devices) pages = (total + page_size - 1) // page_size start = (page - 1) * page_size items = all_devices[start:start + page_size] base_url = f"/api/v1/devices?page_size={page_size}" return { "data": items, "meta": { "total": total, "page": page, "page_size": page_size, "pages": pages, "next": f"{base_url}&page={page+1}" if page < pages else None, "prev": f"{base_url}&page={page-1}" if page > 1 else None, } } @app.get( "/api/v1/devices/{device_id}", response_model=DeviceResponse, summary="Получить устройство", tags=["Devices"], responses={404: {"description": "Устройство не найдено"}} ) async def get_device(device: dict = Depends(get_device_or_404)): return device @app.post( "/api/v1/devices", response_model=DeviceResponse, status_code=status.HTTP_201_CREATED, summary="Создать устройство", tags=["Devices"] ) async def create_device(device_data: DeviceCreate): global device_counter device_counter += 1 now = datetime.utcnow() device = { "id": device_counter, "status": "active", "created_at": now, "updated_at": now, **device_data.dict() } fake_db[device_counter] = device return device @app.patch( "/api/v1/devices/{device_id}", response_model=DeviceResponse, summary="Обновить устройство", tags=["Devices"] ) async def update_device( update_data: DeviceUpdate, device: dict = Depends(get_device_or_404) ): # PATCH — обновляем только переданные поля updates = update_data.dict(exclude_unset=True) # Только явно переданные поля! device.update(updates) device["updated_at"] = datetime.utcnow() return device @app.delete( "/api/v1/devices/{device_id}", status_code=status.HTTP_204_NO_CONTENT, summary="Удалить устройство", tags=["Devices"] ) async def delete_device(device: dict = Depends(get_device_or_404)): fake_db.pop(device["id"]) # 204 — нет тела ответа # ===== ОБРАБОТЧИКИ ОШИБОК ===== @app.exception_handler(404) async def not_found_handler(request, exc): return JSONResponse( status_code=404, content={"error": {"code": "NOT_FOUND", "message": "Ресурс не найден"}} ) @app.exception_handler(500) async def server_error_handler(request, exc): # Логируем, но не раскрываем детали клиенту! import logging logging.exception(f"Unhandled error: {exc}") return JSONResponse( status_code=500, content={ "error": { "code": "INTERNAL_ERROR", "message": "Внутренняя ошибка сервера", "request_id": str(uuid.uuid4()) } } ) JWT авторизацияfrom fastapi import Depends, HTTPException, status from fastapi.security import HTTPBearer, HTTPAuthorizationCredentials import jwt from datetime import datetime, timedelta SECRET_KEY = "super-secret-key-change-in-production" ALGORITHM = "HS256" TOKEN_EXPIRE = 60 * 24 # минуты security = HTTPBearer() def create_access_token(data: dict, expire_minutes: int = TOKEN_EXPIRE) -> str: payload = { **data, "exp": datetime.utcnow() + timedelta(minutes=expire_minutes), "iat": datetime.utcnow(), "type": "access" } return jwt.encode(payload, SECRET_KEY, algorithm=ALGORITHM) def verify_token(credentials: HTTPAuthorizationCredentials = Depends(security)) -> dict: try: payload = jwt.decode(credentials.credentials, SECRET_KEY, algorithms=[ALGORITHM]) return payload except jwt.ExpiredSignatureError: raise HTTPException(status_code=401, detail={ "error": {"code": "TOKEN_EXPIRED", "message": "Токен истёк"} }) except jwt.InvalidTokenError: raise HTTPException(status_code=401, detail={ "error": {"code": "INVALID_TOKEN", "message": "Неверный токен"} }) # Использование: @app.get("/api/v1/protected") async def protected_route(current_user: dict = Depends(verify_token)): return {"user_id": current_user["sub"], "message": "OK"} @app.post("/api/v1/auth/login") async def login(username: str, password: str): # Проверка пользователя (в реальности — из БД) if username != "admin" or password != "secret": raise HTTPException(status_code=401, detail={"error": {"code": "INVALID_CREDENTIALS"}}) token = create_access_token({"sub": username, "role": "admin"}) return {"access_token": token, "token_type": "bearer", "expires_in": TOKEN_EXPIRE * 60} Rate Limitingfrom fastapi import Request from collections import defaultdict import time class InMemoryRateLimiter: """Простой rate limiter (для production используйте Redis)""" def __init__(self, requests_per_minute: int = 60): self.rpm = requests_per_minute self.store = defaultdict(list) def is_allowed(self, key: str) -> tuple[bool, dict]: now = time.time() window = 60.0 # Очищаем устаревшие записи self.store[key] = [t for t in self.store[key] if now - t < window] count = len(self.store[key]) headers = { "X-RateLimit-Limit": str(self.rpm), "X-RateLimit-Remaining": str(max(0, self.rpm - count - 1)), "X-RateLimit-Reset": str(int(now + window)), } if count >= self.rpm: return False, headers self.store[key].append(now) return True, headers rate_limiter = InMemoryRateLimiter(requests_per_minute=100) @app.middleware("http") async def rate_limit_middleware(request: Request, call_next): # Ключ: IP + User-Agent (или user_id после авторизации) client_ip = request.client.host key = f"{client_ip}:{request.headers.get('user-agent', '')[:50]}" allowed, headers = rate_limiter.is_allowed(key) if not allowed: return JSONResponse( status_code=429, content={"error": {"code": "RATE_LIMIT_EXCEEDED", "message": "Слишком много запросов. Повторите через 60 секунд."}}, headers={**headers, "Retry-After": "60"} ) response = await call_next(request) response.headers.update(headers) return response Версионирование API# Способ 1: В URL (самый простой и видимый) # /api/v1/devices # /api/v2/devices # Способ 2: В заголовке # Accept: application/vnd.myapi.v2+json # Способ 3: В параметре запроса # /api/devices?version=2 # Рекомендуется: URL-версионирование для публичных API # Правила обратной совместимости: # ✅ МОЖНО добавлять новые поля в ответ (клиент игнорирует незнакомые) # ✅ МОЖНО добавлять новые необязательные параметры # ✅ МОЖНО добавлять новые endpoints # ❌ НЕЛЬЗЯ удалять поля из ответа # ❌ НЕЛЬЗЯ менять тип поля # ❌ НЕЛЬЗЯ делать необязательный параметр обязательным # ❌ НЕЛЬЗЯ менять семантику существующих полей # Любое из запрещённого → новая мажорная версия! from fastapi import APIRouter # v1 router v1_router = APIRouter(prefix="/api/v1", tags=["v1"]) @v1_router.get("/devices") async def list_devices_v1(): return {"version": "v1", "data": []} # v2 router (новая логика, breaking changes) v2_router = APIRouter(prefix="/api/v2", tags=["v2"]) @v2_router.get("/devices") async def list_devices_v2(): return {"version": "v2", "data": [], "meta": {}} # Новый формат app.include_router(v1_router) app.include_router(v2_router) Документация: OpenAPI и SwaggerFastAPI автоматически генерирует OpenAPI spec. Добавьте подробные комментарии: @app.get( "/api/v1/devices/{device_id}/telemetry", tags=["Telemetry"], summary="Телеметрия устройства", description=""" Возвращает исторические данные телеметрии устройства. ## Параметры времени Используйте ISO 8601 формат: `2024-03-15T10:30:00Z` Или относительные значения: `-1h`, `-24h`, `-7d`, `-30d` ## Агрегация - `raw`: сырые данные (ограничено 10 000 точек) - `1min`: агрегация по минутам - `5min`, `1h`, `1d`: другие интервалы """, response_description="Список точек телеметрии с временными метками", responses={ 200: {"description": "Успешно"}, 404: {"description": "Устройство не найдено"}, 400: {"description": "Неверные параметры времени"}, } ) async def get_telemetry( device_id: int = Path(..., description="ID устройства", example=42), from_time: str = Query(..., description="Начало периода (ISO 8601 или -Nh/-Nd)", example="-24h"), to_time: str = Query(default="now", description="Конец периода"), resample: str = Query(default="5min", description="Интервал агрегации", regex="^(raw|1min|5min|1h|1d)$"), ): ... Чеклист для production APIБезопасность: □ HTTPS только (HTTP редирект на HTTPS) □ JWT с разумным TTL (1-24 часа) □ Rate limiting по IP и по user □ Валидация всех входных данных □ SQL-инъекции: параметризованные запросы (ORM) □ Секреты не в коде (env vars, Vault) □ CORS настроен правильно (не allow_origins=["*"]!) Надёжность: □ Timeouts на все внешние запросы □ Circuit Breaker для сервисов-зависимостей □ Graceful shutdown (SIGTERM обработан) □ Health endpoint /health или /api/health Observability: □ Структурированные логи (JSON) с request_id □ Метрики: latency, error rate, throughput □ Distributed tracing (OpenTelemetry) Документация: □ OpenAPI/Swagger автоматически □ Примеры запросов в описаниях □ CHANGELOG с версиями ЗаключениеХороший REST API — это API, которым приятно пользоваться. Предсказуемые URL, понятные коды ошибок, единообразная структура ответов, версионирование без сюрпризов, документация которая не врёт. FastAPI делает большую часть работы автоматически: валидацию, сериализацию, документацию. Но архитектурные решения — за вами. Потратьте время на проектирование URL до написания кода. Нарисуйте ресурсы и операции. Согласуйте с командой стандарты ошибок. Это окупится при первом обращении клиентской команды к вашему API.
REST: не просто "HTTP + JSON"REST (Representational State Transfer) — архитектурный стиль, описанный Роем Филдингом в 2000 году. Большинство "REST API" в реальности — это RPC поверх HTTP (CRUD по URL). Настоящий REST имеет шесть ограничений, из которых на практике применяют три-четыре. Но это не важно. Важно проектировать API, которым приятно пользоваться: предсказуемым, документированным, обрабатывающим ошибки правильно, безопасным и масштабируемым. Дизайн URL: основные принципыПринципы именования ресурсов:✅ Существительные во множественном числе: /api/v1/devices /api/v1/devices/42 /api/v1/devices/42/sensors /api/v1/devices/42/sensors/7/readings ❌ Глаголы в URL: /api/v1/getDevices ← нет! /api/v1/createDevice ← нет! /api/v1/device/42/delete ← нет! Действие выражается HTTP-методом: GET /devices → список устройств POST /devices → создать устройство GET /devices/42 → получить устройство 42 PUT /devices/42 → полностью заменить устройство 42 PATCH /devices/42 → частично обновить устройство 42 DELETE /devices/42 → удалить устройство 42 Вложенность — для зависимых ресурсов: GET /devices/42/sensors → датчики устройства 42 POST /devices/42/sensors → добавить датчик к устройству 42 GET /devices/42/sensors/7 → конкретный датчик DELETE /devices/42/sensors/7 → удалить датчик Максимум 3 уровня вложенности! Глубже — smell. HTTP методы и их семантикаМетод Идемпотентный Безопасный Применение GET ✅ ✅ Получение данных POST ❌ ❌ Создание, не-идемпотентные действия PUT ✅ ❌ Полная замена ресурса PATCH ❌* ❌ Частичное обновление DELETE ✅ ❌ Удаление HEAD ✅ ✅ Получение заголовков без тела OPTIONS ✅ ✅ CORS preflight, capabilities Идемпотентность: повторный вызов даёт тот же результат. PUT /devices/42 с одними данными можно вызвать 100 раз — результат одинаковый. DELETE /devices/42 — тоже (второй вызов: 404, но ресурс всё равно удалён). Коды состояния HTTP: правильное использование2xx — Успех: 200 OK — GET, PUT, PATCH успешно 201 Created — POST создал ресурс; Location: /api/v1/devices/43 204 No Content — DELETE, PATCH без возврата данных 3xx — Перенаправление: 301 Moved Permanently — ресурс переехал навсегда 304 Not Modified — кешированный ответ актуален (ETag/If-None-Match) 4xx — Ошибка клиента: 400 Bad Request — невалидные данные запроса 401 Unauthorized — не аутентифицирован (нет или неверный токен) 403 Forbidden — аутентифицирован, но нет прав 404 Not Found — ресурс не существует 405 Method Not Allowed— метод не поддерживается для этого URL 409 Conflict — конфликт (дубликат, версионирование) 422 Unprocessable — синтаксически корректный JSON, но семантически неверный 429 Too Many Requests — rate limit превышен 5xx — Ошибка сервера: 500 Internal Server Error — непредвиденная ошибка 503 Service Unavailable — временно недоступен (maintenance, overload) Структура ответов: единообразие обязательно# Стандартизированный формат ответа # Успешный список с пагинацией: { "data": [ {"id": 1, "name": "Насос 1", "status": "active"}, {"id": 2, "name": "Насос 2", "status": "fault"} ], "meta": { "total": 48, "page": 2, "page_size": 10, "pages": 5, "next": "/api/v1/devices?page=3&page_size=10", "prev": "/api/v1/devices?page=1&page_size=10" } } # Единичный объект: { "data": { "id": 42, "name": "Насос холодной воды", "location": "Котельная", "created_at": "2024-01-15T10:30:00Z", "updated_at": "2024-03-10T08:45:22Z" } } # Ошибка (ВСЕГДА одна структура!): { "error": { "code": "VALIDATION_ERROR", "message": "Ошибка валидации входных данных", "details": [ { "field": "temperature_max", "message": "Значение должно быть больше temperature_min" }, { "field": "device_id", "message": "Устройство с таким ID не существует" } ], "request_id": "req_abc123xyz", "timestamp": "2024-03-15T14:22:33Z" } } FastAPI: production-ready API за минуты# main.py from fastapi import FastAPI, HTTPException, Depends, Query, Path, status from fastapi.middleware.cors import CORSMiddleware from fastapi.middleware.gzip import GZipMiddleware from fastapi.responses import JSONResponse from pydantic import BaseModel, Field, validator from typing import Optional, List from datetime import datetime import uuid app = FastAPI( title="Industrial IoT API", description="API управления промышленными устройствами", version="1.0.0", docs_url="/api/docs", # Swagger UI redoc_url="/api/redoc", # ReDoc openapi_url="/api/openapi.json" ) # Middleware app.add_middleware(GZipMiddleware, minimum_size=1000) app.add_middleware( CORSMiddleware, allow_origins=["https://dashboard.factory.com"], allow_methods=["GET", "POST", "PUT", "PATCH", "DELETE"], allow_headers=["Authorization", "Content-Type", "X-Request-ID"], ) # ===== МОДЕЛИ ===== class DeviceStatus(str): ACTIVE = "active" INACTIVE = "inactive" FAULT = "fault" MAINTENANCE = "maintenance" class DeviceBase(BaseModel): name: str = Field(..., min_length=1, max_length=100, example="Насос 1") location: str = Field(..., example="Котельная") model: str = Field(..., example="Grundfos CM5-5") tags: List[str] = Field(default=[], example=["pump", "cooling"]) class DeviceCreate(DeviceBase): pass class DeviceUpdate(BaseModel): name: Optional[str] = Field(None, min_length=1, max_length=100) location: Optional[str] = None status: Optional[str] = None tags: Optional[List[str]] = None class DeviceResponse(DeviceBase): id: int status: str = "active" created_at: datetime updated_at: datetime class Config: from_attributes = True class PaginatedResponse(BaseModel): data: List[DeviceResponse] meta: dict # ===== ЗАВИСИМОСТИ ===== # Имитация БД fake_db = {} device_counter = 0 def get_device_or_404(device_id: int = Path(..., ge=1)) -> dict: device = fake_db.get(device_id) if not device: raise HTTPException( status_code=status.HTTP_404_NOT_FOUND, detail={ "error": { "code": "DEVICE_NOT_FOUND", "message": f"Устройство с ID {device_id} не найдено", "request_id": str(uuid.uuid4()) } } ) return device # ===== ENDPOINTS ===== @app.get( "/api/v1/devices", response_model=PaginatedResponse, summary="Список устройств", tags=["Devices"] ) async def list_devices( page: int = Query(default=1, ge=1, description="Номер страницы"), page_size: int = Query(default=20, ge=1, le=100, description="Размер страницы"), status: Optional[str] = Query(default=None, description="Фильтр по статусу"), search: Optional[str] = Query(default=None, description="Поиск по имени"), sort_by: str = Query(default="created_at", description="Поле сортировки"), sort_desc: bool = Query(default=True, description="По убыванию"), ): """ Возвращает список устройств с пагинацией и фильтрацией. - **page**: страница (начиная с 1) - **page_size**: количество на странице (макс. 100) - **status**: фильтр по статусу (active, inactive, fault, maintenance) - **search**: поиск по имени и местоположению """ # Имитация запроса к БД all_devices = list(fake_db.values()) if status: all_devices = [d for d in all_devices if d.get("status") == status] if search: q = search.lower() all_devices = [d for d in all_devices if q in d.get("name", "").lower() or q in d.get("location", "").lower()] total = len(all_devices) pages = (total + page_size - 1) // page_size start = (page - 1) * page_size items = all_devices[start:start + page_size] base_url = f"/api/v1/devices?page_size={page_size}" return { "data": items, "meta": { "total": total, "page": page, "page_size": page_size, "pages": pages, "next": f"{base_url}&page={page+1}" if page < pages else None, "prev": f"{base_url}&page={page-1}" if page > 1 else None, } } @app.get( "/api/v1/devices/{device_id}", response_model=DeviceResponse, summary="Получить устройство", tags=["Devices"], responses={404: {"description": "Устройство не найдено"}} ) async def get_device(device: dict = Depends(get_device_or_404)): return device @app.post( "/api/v1/devices", response_model=DeviceResponse, status_code=status.HTTP_201_CREATED, summary="Создать устройство", tags=["Devices"] ) async def create_device(device_data: DeviceCreate): global device_counter device_counter += 1 now = datetime.utcnow() device = { "id": device_counter, "status": "active", "created_at": now, "updated_at": now, **device_data.dict() } fake_db[device_counter] = device return device @app.patch( "/api/v1/devices/{device_id}", response_model=DeviceResponse, summary="Обновить устройство", tags=["Devices"] ) async def update_device( update_data: DeviceUpdate, device: dict = Depends(get_device_or_404) ): # PATCH — обновляем только переданные поля updates = update_data.dict(exclude_unset=True) # Только явно переданные поля! device.update(updates) device["updated_at"] = datetime.utcnow() return device @app.delete( "/api/v1/devices/{device_id}", status_code=status.HTTP_204_NO_CONTENT, summary="Удалить устройство", tags=["Devices"] ) async def delete_device(device: dict = Depends(get_device_or_404)): fake_db.pop(device["id"]) # 204 — нет тела ответа # ===== ОБРАБОТЧИКИ ОШИБОК ===== @app.exception_handler(404) async def not_found_handler(request, exc): return JSONResponse( status_code=404, content={"error": {"code": "NOT_FOUND", "message": "Ресурс не найден"}} ) @app.exception_handler(500) async def server_error_handler(request, exc): # Логируем, но не раскрываем детали клиенту! import logging logging.exception(f"Unhandled error: {exc}") return JSONResponse( status_code=500, content={ "error": { "code": "INTERNAL_ERROR", "message": "Внутренняя ошибка сервера", "request_id": str(uuid.uuid4()) } } ) JWT авторизацияfrom fastapi import Depends, HTTPException, status from fastapi.security import HTTPBearer, HTTPAuthorizationCredentials import jwt from datetime import datetime, timedelta SECRET_KEY = "super-secret-key-change-in-production" ALGORITHM = "HS256" TOKEN_EXPIRE = 60 * 24 # минуты security = HTTPBearer() def create_access_token(data: dict, expire_minutes: int = TOKEN_EXPIRE) -> str: payload = { **data, "exp": datetime.utcnow() + timedelta(minutes=expire_minutes), "iat": datetime.utcnow(), "type": "access" } return jwt.encode(payload, SECRET_KEY, algorithm=ALGORITHM) def verify_token(credentials: HTTPAuthorizationCredentials = Depends(security)) -> dict: try: payload = jwt.decode(credentials.credentials, SECRET_KEY, algorithms=[ALGORITHM]) return payload except jwt.ExpiredSignatureError: raise HTTPException(status_code=401, detail={ "error": {"code": "TOKEN_EXPIRED", "message": "Токен истёк"} }) except jwt.InvalidTokenError: raise HTTPException(status_code=401, detail={ "error": {"code": "INVALID_TOKEN", "message": "Неверный токен"} }) # Использование: @app.get("/api/v1/protected") async def protected_route(current_user: dict = Depends(verify_token)): return {"user_id": current_user["sub"], "message": "OK"} @app.post("/api/v1/auth/login") async def login(username: str, password: str): # Проверка пользователя (в реальности — из БД) if username != "admin" or password != "secret": raise HTTPException(status_code=401, detail={"error": {"code": "INVALID_CREDENTIALS"}}) token = create_access_token({"sub": username, "role": "admin"}) return {"access_token": token, "token_type": "bearer", "expires_in": TOKEN_EXPIRE * 60} Rate Limitingfrom fastapi import Request from collections import defaultdict import time class InMemoryRateLimiter: """Простой rate limiter (для production используйте Redis)""" def __init__(self, requests_per_minute: int = 60): self.rpm = requests_per_minute self.store = defaultdict(list) def is_allowed(self, key: str) -> tuple[bool, dict]: now = time.time() window = 60.0 # Очищаем устаревшие записи self.store[key] = [t for t in self.store[key] if now - t < window] count = len(self.store[key]) headers = { "X-RateLimit-Limit": str(self.rpm), "X-RateLimit-Remaining": str(max(0, self.rpm - count - 1)), "X-RateLimit-Reset": str(int(now + window)), } if count >= self.rpm: return False, headers self.store[key].append(now) return True, headers rate_limiter = InMemoryRateLimiter(requests_per_minute=100) @app.middleware("http") async def rate_limit_middleware(request: Request, call_next): # Ключ: IP + User-Agent (или user_id после авторизации) client_ip = request.client.host key = f"{client_ip}:{request.headers.get('user-agent', '')[:50]}" allowed, headers = rate_limiter.is_allowed(key) if not allowed: return JSONResponse( status_code=429, content={"error": {"code": "RATE_LIMIT_EXCEEDED", "message": "Слишком много запросов. Повторите через 60 секунд."}}, headers={**headers, "Retry-After": "60"} ) response = await call_next(request) response.headers.update(headers) return response Версионирование API# Способ 1: В URL (самый простой и видимый) # /api/v1/devices # /api/v2/devices # Способ 2: В заголовке # Accept: application/vnd.myapi.v2+json # Способ 3: В параметре запроса # /api/devices?version=2 # Рекомендуется: URL-версионирование для публичных API # Правила обратной совместимости: # ✅ МОЖНО добавлять новые поля в ответ (клиент игнорирует незнакомые) # ✅ МОЖНО добавлять новые необязательные параметры # ✅ МОЖНО добавлять новые endpoints # ❌ НЕЛЬЗЯ удалять поля из ответа # ❌ НЕЛЬЗЯ менять тип поля # ❌ НЕЛЬЗЯ делать необязательный параметр обязательным # ❌ НЕЛЬЗЯ менять семантику существующих полей # Любое из запрещённого → новая мажорная версия! from fastapi import APIRouter # v1 router v1_router = APIRouter(prefix="/api/v1", tags=["v1"]) @v1_router.get("/devices") async def list_devices_v1(): return {"version": "v1", "data": []} # v2 router (новая логика, breaking changes) v2_router = APIRouter(prefix="/api/v2", tags=["v2"]) @v2_router.get("/devices") async def list_devices_v2(): return {"version": "v2", "data": [], "meta": {}} # Новый формат app.include_router(v1_router) app.include_router(v2_router) Документация: OpenAPI и SwaggerFastAPI автоматически генерирует OpenAPI spec. Добавьте подробные комментарии: @app.get( "/api/v1/devices/{device_id}/telemetry", tags=["Telemetry"], summary="Телеметрия устройства", description=""" Возвращает исторические данные телеметрии устройства. ## Параметры времени Используйте ISO 8601 формат: `2024-03-15T10:30:00Z` Или относительные значения: `-1h`, `-24h`, `-7d`, `-30d` ## Агрегация - `raw`: сырые данные (ограничено 10 000 точек) - `1min`: агрегация по минутам - `5min`, `1h`, `1d`: другие интервалы """, response_description="Список точек телеметрии с временными метками", responses={ 200: {"description": "Успешно"}, 404: {"description": "Устройство не найдено"}, 400: {"description": "Неверные параметры времени"}, } ) async def get_telemetry( device_id: int = Path(..., description="ID устройства", example=42), from_time: str = Query(..., description="Начало периода (ISO 8601 или -Nh/-Nd)", example="-24h"), to_time: str = Query(default="now", description="Конец периода"), resample: str = Query(default="5min", description="Интервал агрегации", regex="^(raw|1min|5min|1h|1d)$"), ): ... Чеклист для production APIБезопасность: □ HTTPS только (HTTP редирект на HTTPS) □ JWT с разумным TTL (1-24 часа) □ Rate limiting по IP и по user □ Валидация всех входных данных □ SQL-инъекции: параметризованные запросы (ORM) □ Секреты не в коде (env vars, Vault) □ CORS настроен правильно (не allow_origins=["*"]!) Надёжность: □ Timeouts на все внешние запросы □ Circuit Breaker для сервисов-зависимостей □ Graceful shutdown (SIGTERM обработан) □ Health endpoint /health или /api/health Observability: □ Структурированные логи (JSON) с request_id □ Метрики: latency, error rate, throughput □ Distributed tracing (OpenTelemetry) Документация: □ OpenAPI/Swagger автоматически □ Примеры запросов в описаниях □ CHANGELOG с версиями ЗаключениеХороший REST API — это API, которым приятно пользоваться. Предсказуемые URL, понятные коды ошибок, единообразная структура ответов, версионирование без сюрпризов, документация которая не врёт. FastAPI делает большую часть работы автоматически: валидацию, сериализацию, документацию. Но архитектурные решения — за вами. Потратьте время на проектирование URL до написания кода. Нарисуйте ресурсы и операции. Согласуйте с командой стандарты ошибок. Это окупится при первом обращении клиентской команды к вашему API. -
 Правильный датчик — половина успеха автоматизацииСамый умный ПЛК и лучший алгоритм управления ничего не стоят, если датчик даёт неверные данные. Выбор, монтаж и калибровка датчиков — часто недооцениваемая область, которая определяет качество всей системы. Промышленный датчик — не просто "измерительное устройство". Это прибор, который должен работать 24/7 годами в условиях вибраций, агрессивных сред, перепадов температур и электромагнитных помех. И при этом давать достоверные показания. Классификация выходных сигналовПрежде чем выбирать датчик — определитесь с типом сигнала: Аналоговые сигналы4–20 мА (токовая петля): Самый распространённый промышленный стандарт 4 мА = 0% диапазона, 20 мА = 100% Устойчив к помехам (ток, не напряжение) Обнаружение обрыва кабеля: < 3.8 мА = авария Длина линии до нескольких км (ограничено напряжением питания) Двухпроводная схема: датчик питается от той же петли! 0–10 В: Проще в подключении, но чувствителен к помехам Нет встроенного обнаружения обрыва Ограничение длины кабеля (~50 м) Используется в HVAC, Building Automation 0–5 В / ±10 В: Распространён для ускорений, давлений в автомотиве Дискретные сигналыNPN / PNP: NPN: выход тянет к GND при активации (сигнал = LOW) PNP: выход тянет к питанию (сигнал = HIGH) Подключение к ПЛК: важно соответствие типа входного модуля! NO / NC (нормально открытый / нормально закрытый): NO: контакт разомкнут в норме, замыкается при срабатывании NC: контакт замкнут в норме, размыкается при срабатывании Для безопасности: NC предпочтительнее (обрыв провода = срабатывание защиты) Цифровые/протокольныеIO-Link, HART, Profibus PA, Foundation Fieldbus, EtherCAT — для умных датчиков с диагностикой и конфигурированием по линии. Температура: термопары и PT100Термопары (Thermocouple)Принцип: эффект Зеебека — два разных металла, соединённых в двух точках, генерируют ЭДС при разнице температур. Тип Диапазон Материал Применение K -200..+1372°C NiCr-NiAl Универсальный, самый популярный J -210..+1200°C Fe-CuNi Печи, старые установки T -270..+400°C Cu-CuNi Криогеника, пищевая промышленность N -270..+1300°C NiCrSi-NiSi Стабильнее K при высоких T S 0..+1768°C Pt10Rh-Pt Металлургия (эталон) B +250..+1820°C Pt30Rh-Pt6Rh Высокотемпературные печи Ключевые особенности термопар: Генерируют малую ЭДС (0–80 мВ) — нужен прецизионный усилитель Требуют компенсации холодного спая (CJC — Cold Junction Compensation) Длинные термопарные кабели из компенсационных проводов (дороже!) Нелинейная характеристика (полиномиальная аппроксимация по ГОСТ) Подключение к микроконтроллеру через MAX31855/MAX6675: #include <Adafruit_MAX31855.h> #include <SPI.h> // MAX31855: усилитель термопары типа K с SPI интерфейсом Adafruit_MAX31855 thermocouple(D5, D6, D7); // CLK, CS, DO void setup() { Serial.begin(115200); if (!thermocouple.begin()) { Serial.println("MAX31855 не найден!"); while (1); } } void loop() { double hot_temp = thermocouple.readCelsius(); // Температура термопары double cold_temp = thermocouple.readInternal(); // Температура холодного спая (чип) if (isnan(hot_temp)) { uint8_t fault = thermocouple.readError(); Serial.print("Ошибка: "); if (fault & MAX31855_FAULT_OPEN) Serial.println("обрыв термопары"); if (fault & MAX31855_FAULT_SHORT_GND) Serial.println("КЗ на GND"); if (fault & MAX31855_FAULT_SHORT_VCC) Serial.println("КЗ на VCC"); } else { Serial.printf("T = %.2f°C (холодный спай: %.2f°C)\n", hot_temp, cold_temp); } delay(1000); } Термосопротивления PT100/PT1000Принцип: сопротивление платинового проводника линейно растёт с температурой. PT100: 100 Ом при 0°C, α = 0.00385 Ом/(Ом·°C) PT1000: 1000 Ом при 0°C (лучше для длинных кабелей) R(T) = R0 × [1 + A×T + B×T² + C×T³ × (T-100)] R0 = 100 Ом A = 3.9083×10⁻³ B = -5.775×10⁻⁷ C = -4.183×10⁻¹² (только при T < 0°C) Упрощённо для -50..+200°C: R(T) ≈ 100 × (1 + 0.00385 × T) T ≈ (R - 100) / 0.385 Схемы подключения: 2-проводная (дёшево, но ошибка от сопротивления кабеля): [ПЛК]──R_кабель──[PT100]──R_кабель──[ПЛК] Ошибка: ΔR_кабель = 2 × ρ × L / S При 10 м, 0.5 мм²: ΔR ≈ 0.7 Ом ≈ 1.8°C погрешность! 3-проводная (стандарт): [ПЛК]──R1──[PT100]──R2──[ПЛК] │ R3──────────[ПЛК] Измерительная схема компенсирует сопротивление одного провода 4-проводная (эталонная точность): [ПЛК]──I+──[PT100]──I-──[ПЛК] (ток через PT100) [ПЛК]──U+──[PT100]──U-──[ПЛК] (измерение напряжения) Сопротивление провода не влияет на точность Датчики давления: 4–20 мА в промышленностиОсновные типы:Пьезорезистивные: мембрана с тензодатчиками, сигнал 4–20 мА. Самые распространённые. Пьезоэлектрические: для динамических давлений (удары, взрывы). Заряд пропорционален давлению. Ёмкостные: высокая точность (0.01%), дорогие. Для точных технологических процессов. Подключение датчика 4–20 мА:Двухпроводная схема (+питание, -сигнал): 24В ──────────┬──────── Датчик (+) │ R_shunt (250 Ом) │ GND ──────────┴──────── Датчик (-) │ Измеряем U на R_shunt 4мА → 1.000В 20мА → 5.000В В ПЛК: аналоговый вход 1–5В или через преобразователь ток→напряжение def current_to_pressure(current_ma: float, pressure_min: float, pressure_max: float) -> float: """ Преобразование тока 4-20мА в давление. Args: current_ma: ток в мА (4.0..20.0) pressure_min: давление при 4мА (нижний предел датчика) pressure_max: давление при 20мА (верхний предел) Returns: давление в единицах pressure_min/max """ # Проверка обрыва линии if current_ma < 3.8: raise ValueError(f"Обрыв линии или ошибка датчика: {current_ma} мА") # Проверка превышения if current_ma > 20.5: raise ValueError(f"Превышение тока: {current_ma} мА") # Линейное масштабирование # 4мА = 0%, 20мА = 100% pct = (current_ma - 4.0) / 16.0 return pressure_min + pct * (pressure_max - pressure_min) # ADC напряжение → ток → давление def adc_voltage_to_pressure(voltage_v: float, shunt_ohm: float = 250.0, p_min: float = 0.0, p_max: float = 16.0) -> float: current_ma = voltage_v / shunt_ohm * 1000.0 return current_to_pressure(current_ma, p_min, p_max) # Пример: voltage = 2.5 # Вольт на шунте 250 Ом current = 2.5 / 250 * 1000 # = 10 мА pressure = current_to_pressure(current, 0, 16) # = 7.5 бар (середина диапазона) Индуктивные датчики: металл без контактаИндуктивный датчик (Inductive Proximity Sensor) обнаруживает металлические объекты без физического контакта. Принцип: высокочастотное электромагнитное поле. При попадании металла в зону — меняется амплитуда генератора → срабатывание. Дальность обнаружения зависит от металла: Сталь (St37): номинальная дальность × 1.0 Нержавейка (304): × 0.7–0.85 Алюминий: × 0.4–0.5 Медь, латунь: × 0.35–0.45 Типичные параметры: Диаметр: M8, M12, M18, M30 (стандартные серии) Дальность: 2–50 мм Выход: NPN или PNP, NO или NC Питание: 10–30В DC Частота переключения: до 3000–5000 Гц Пример выбора: Считать металлические детали на конвейере: M12, PNP NO, Sn=4 мм Контроль положения поршня цилиндра: M8 встраиваемый, PNP NO Подключение PNP к ПЛК с входом 24В: +24В ──────── Коричневый провод датчика (питание) Синий провод ────────────────────────── GND (0В) Чёрный провод ── DI вход ПЛК ─── ↗ 24В при срабатывании NPN подключение к ПЛК: +24В ────────────────────────────── DI вход ПЛК Чёрный провод ─── DI вход ПЛК ── ↘ 0В при срабатывании Ёмкостные датчики: любые материалыЁмкостной датчик (Capacitive) обнаруживает металлы, пластики, жидкости, порошки, дерево. Принцип: электрод датчика образует конденсатор с объектом. Приближение объекта → рост ёмкости → срабатывание. Применения: Контроль уровня сыпучих материалов (зерно, цемент, порошки) сквозь стенку ёмкости Обнаружение прозрачных объектов (стекло, пластик) — там, где оптика не работает Контроль присутствия жидкости в трубе (сквозь пластик) Счётчик таблеток/ампул на фармацевтическом конвейере Особенность: требует настройки чувствительности под конкретный материал и расстояние (потенциометр или IO-Link). Ультразвуковые датчики уровняПринцип: излучают ультразвуковой импульс → принимают эхо → время до эха = расстояние. Расстояние = v_звука × t_эхо / 2 v_звука ≈ 343 м/с при 20°C Поправка на температуру: v(T) = 331.5 + 0.606 × T(°C) При T=40°C: v = 331.5 + 0.606×40 = 355.7 м/с Ошибка без коррекции при 5м дальности: Δd = 5 × (355.7-343)/343 = 0.185 м = 18.5 см! Пример: SR-04 (HC-SR04) на Arduino: // HC-SR04: бюджетный датчик для прототипов (не промышленный!) // Промышленные: Pepperl+Fuchs, Microsonic, ifm, Banner const int TRIG_PIN = 9; const int ECHO_PIN = 10; void setup() { Serial.begin(115200); pinMode(TRIG_PIN, OUTPUT); pinMode(ECHO_PIN, INPUT); } float measure_distance_cm(float temp_celsius = 20.0) { // Отправляем импульс 10 мкс digitalWrite(TRIG_PIN, LOW); delayMicroseconds(2); digitalWrite(TRIG_PIN, HIGH); delayMicroseconds(10); digitalWrite(TRIG_PIN, LOW); // Измеряем длительность эхо unsigned long duration_us = pulseIn(ECHO_PIN, HIGH, 30000); // таймаут 30 мс if (duration_us == 0) { return -1; // Объект не найден или слишком далеко } // Расчёт расстояния с коррекцией температуры float speed_cms = (331.5 + 0.606 * temp_celsius) * 100.0 / 1000000.0; // см/мкс float distance = duration_us * speed_cms / 2.0; return distance; } // Уровень в резервуаре: float measure_tank_level(float tank_height_cm) { float distance = measure_distance_cm(25.0); if (distance < 0 || distance > tank_height_cm) return -1; float level_pct = (1.0 - distance / tank_height_cm) * 100.0; return max(0.0f, min(100.0f, level_pct)); } Мёртвая зона: HC-SR04 не измеряет до 2 см. Промышленные: от 1–3 мм. Проблемы: пена на поверхности жидкости, пыль, ветер, наклонные поверхности, температурные градиенты. Расходомеры: измерение потокаЭлектромагнитный (Flowmeter/Магнитный):Только электропроводящие жидкости (вода, кислоты, суспензии) Нет движущихся частей → долговечность Нет потерь давления Погрешность: 0.5–1% Сигнал: 4–20 мА + импульсный выход (число импульсов = объём) Вихревой (Vortex):Жидкости и газы Измеряет частоту вихрей (пропорциональна скорости) Минимальный расход: ограничен (при малом расходе не работает) Ультразвуковой (накладной / inline):Накладной: крепится снаружи трубы без врезки! Подходит для ретрофита существующих трубопроводов Для чистых жидкостей (пузыри искажают сигнал) Coriolis:Измеряет массовый расход напрямую (не объём!) Самый точный (0.1%), самый дорогой Работает с любыми жидкостями, суспензиями, вязкими средами Датчики вибрации: предиктивное обслуживаниеimport numpy as np from scipy.fft import rfft, rfftfreq from scipy.signal import find_peaks class VibrationAnalyzer: """ Анализ вибрации для диагностики подшипников и валов. Акселерометр: ADXL345 (I2C) или промышленный 4-20мА. """ def __init__(self, sample_rate: int = 1000): self.sample_rate = sample_rate def analyze(self, samples: np.ndarray, machine_rpm: float) -> dict: """ Полный анализ вибрационного сигнала. machine_rpm: скорость вращения (об/мин) для идентификации гармоник """ n = len(samples) # === ВРЕМЕННЫЕ ПОКАЗАТЕЛИ === rms = np.sqrt(np.mean(samples**2)) peak = np.max(np.abs(samples)) crest = peak / rms if rms > 0 else 0 # Эксцесс (Kurtosis): для обнаружения ударных дефектов mean = np.mean(samples) std = np.std(samples) kurtosis = np.mean(((samples - mean) / std)**4) if std > 0 else 0 # === СПЕКТРАЛЬНЫЙ АНАЛИЗ === # Оконная функция для уменьшения утечек window = np.hanning(n) spectrum = np.abs(rfft(samples * window)) * 2 / n freqs = rfftfreq(n, 1.0 / self.sample_rate) # Основная частота вращения f_rotation = machine_rpm / 60.0 # Поиск пиков в спектре peaks_idx, peak_props = find_peaks( spectrum, height=0.01 * np.max(spectrum), distance=5 ) peaks = [(float(freqs[i]), float(spectrum[i])) for i in peaks_idx] peaks.sort(key=lambda x: -x[1]) # По убыванию амплитуды # Идентификация характерных частот identified = {} for freq, amp in peaks[:10]: # Гармоники вращения for harmonic in range(1, 8): if abs(freq - harmonic * f_rotation) < 2.0: identified[f"{harmonic}x_rotation"] = (freq, amp) # === ДИАГНОСТИКА === # ISO 10816-3: нормы вибрации для промышленных машин # Класс 1 (малые): OK<2.3, WARN<4.5, CRIT<7.1 мм/с RMS # Класс 2 (средние): OK<4.5, WARN<7.1, CRIT<11.0 rms_velocity_mms = rms / (2 * np.pi * f_rotation) * 1000 if f_rotation > 0 else 0 if rms_velocity_mms < 2.3: iso_status = "Зона A (Хорошо)" elif rms_velocity_mms < 4.5: iso_status = "Зона B (Допустимо)" elif rms_velocity_mms < 7.1: iso_status = "Зона C (Внимание!)" else: iso_status = "Зона D (Опасно!)" # Диагностика по Kurtosis if kurtosis > 6: bearing_diagnosis = "Дефект подшипника (ударные нагрузки)" elif kurtosis > 4: bearing_diagnosis = "Начальный износ подшипника" else: bearing_diagnosis = "Норма" return { 'rms_g': round(rms, 4), 'peak_g': round(peak, 4), 'crest_factor': round(crest, 2), 'kurtosis': round(kurtosis, 2), 'rms_velocity_mms': round(rms_velocity_mms, 2), 'iso_status': iso_status, 'bearing_status': bearing_diagnosis, 'top_frequencies': peaks[:5], 'identified_harmonics': identified, } Калибровка: без неё данные не достоверныКаждый датчик имеет погрешности: смещение (offset), нелинейность, дрейф со временем и температурой. Калибровка — сравнение с эталоном и коррекция. def two_point_calibration(raw_low: float, ref_low: float, raw_high: float, ref_high: float, raw_measured: float) -> float: """ Двухточечная линейная калибровка. raw_low, raw_high: показания датчика в нижней и верхней точках ref_low, ref_high: эталонные значения в этих точках raw_measured: текущее показание датчика Пример: PT100 показывает 99.2 Ом при 0°C (вместо 100) и 138.9 при 100°C (вместо 138.5) calibrated = two_point_calibration(99.2, 100.0, 138.9, 138.5, current_reading) """ if raw_high == raw_low: return ref_low # Линейная интерполяция slope = (ref_high - ref_low) / (raw_high - raw_low) offset = ref_low - slope * raw_low return slope * raw_measured + offset Периодичность калибровки:Термопары: ежегодно или при замене PT100: 1–2 раза в год (дрейф незначителен) Датчики давления: раз в год или при смене диапазона Расходомеры: согласно паспорту (обычно 1 раз в год) Монтаж: правила, которые нельзя игнорироватьТемпературные датчики:✅ Погружение на 1/2–2/3 диаметра трубы ✅ Против потока (для лучшего теплообмена) ✅ Защитный карман (гильза) из нержавейки ❌ На наружной поверхности трубы (ошибка до 50°C!) ❌ В зоне завихрений (после колен, до 10D от колена) Датчики давления: ✅ Импульсные линии: уклон для самодренажа (для газа — вверх, для жидкости — вниз) ✅ Манометрический вентиль для обслуживания без остановки ❌ Прямое подключение к горячим/агрессивным средам без разделительного сосуда Индуктивные датчики: ✅ Расстояние > 2× диаметра от соседних металлических поверхностей ✅ Осевая нагрузка — только через крепёжную гайку, не на корпус ❌ Монтаж в металлический кронштейн вплотную (ложные срабатывания) ЗаключениеПравильный выбор датчика — это компромисс между точностью, диапазоном, стойкостью к среде, стоимостью и сложностью подключения. Никогда не выбирайте датчик по принципу "самый дешёвый" — плохой датчик в критическом месте обойдётся дороже в простоях и ремонтах. Всегда изучайте datasheet: реальный диапазон рабочих температур, степень защиты IP, материал контактной части. И никогда не экономьте на монтаже — половина проблем с датчиками — это неправильный монтаж, а не неисправность прибора.
Правильный датчик — половина успеха автоматизацииСамый умный ПЛК и лучший алгоритм управления ничего не стоят, если датчик даёт неверные данные. Выбор, монтаж и калибровка датчиков — часто недооцениваемая область, которая определяет качество всей системы. Промышленный датчик — не просто "измерительное устройство". Это прибор, который должен работать 24/7 годами в условиях вибраций, агрессивных сред, перепадов температур и электромагнитных помех. И при этом давать достоверные показания. Классификация выходных сигналовПрежде чем выбирать датчик — определитесь с типом сигнала: Аналоговые сигналы4–20 мА (токовая петля): Самый распространённый промышленный стандарт 4 мА = 0% диапазона, 20 мА = 100% Устойчив к помехам (ток, не напряжение) Обнаружение обрыва кабеля: < 3.8 мА = авария Длина линии до нескольких км (ограничено напряжением питания) Двухпроводная схема: датчик питается от той же петли! 0–10 В: Проще в подключении, но чувствителен к помехам Нет встроенного обнаружения обрыва Ограничение длины кабеля (~50 м) Используется в HVAC, Building Automation 0–5 В / ±10 В: Распространён для ускорений, давлений в автомотиве Дискретные сигналыNPN / PNP: NPN: выход тянет к GND при активации (сигнал = LOW) PNP: выход тянет к питанию (сигнал = HIGH) Подключение к ПЛК: важно соответствие типа входного модуля! NO / NC (нормально открытый / нормально закрытый): NO: контакт разомкнут в норме, замыкается при срабатывании NC: контакт замкнут в норме, размыкается при срабатывании Для безопасности: NC предпочтительнее (обрыв провода = срабатывание защиты) Цифровые/протокольныеIO-Link, HART, Profibus PA, Foundation Fieldbus, EtherCAT — для умных датчиков с диагностикой и конфигурированием по линии. Температура: термопары и PT100Термопары (Thermocouple)Принцип: эффект Зеебека — два разных металла, соединённых в двух точках, генерируют ЭДС при разнице температур. Тип Диапазон Материал Применение K -200..+1372°C NiCr-NiAl Универсальный, самый популярный J -210..+1200°C Fe-CuNi Печи, старые установки T -270..+400°C Cu-CuNi Криогеника, пищевая промышленность N -270..+1300°C NiCrSi-NiSi Стабильнее K при высоких T S 0..+1768°C Pt10Rh-Pt Металлургия (эталон) B +250..+1820°C Pt30Rh-Pt6Rh Высокотемпературные печи Ключевые особенности термопар: Генерируют малую ЭДС (0–80 мВ) — нужен прецизионный усилитель Требуют компенсации холодного спая (CJC — Cold Junction Compensation) Длинные термопарные кабели из компенсационных проводов (дороже!) Нелинейная характеристика (полиномиальная аппроксимация по ГОСТ) Подключение к микроконтроллеру через MAX31855/MAX6675: #include <Adafruit_MAX31855.h> #include <SPI.h> // MAX31855: усилитель термопары типа K с SPI интерфейсом Adafruit_MAX31855 thermocouple(D5, D6, D7); // CLK, CS, DO void setup() { Serial.begin(115200); if (!thermocouple.begin()) { Serial.println("MAX31855 не найден!"); while (1); } } void loop() { double hot_temp = thermocouple.readCelsius(); // Температура термопары double cold_temp = thermocouple.readInternal(); // Температура холодного спая (чип) if (isnan(hot_temp)) { uint8_t fault = thermocouple.readError(); Serial.print("Ошибка: "); if (fault & MAX31855_FAULT_OPEN) Serial.println("обрыв термопары"); if (fault & MAX31855_FAULT_SHORT_GND) Serial.println("КЗ на GND"); if (fault & MAX31855_FAULT_SHORT_VCC) Serial.println("КЗ на VCC"); } else { Serial.printf("T = %.2f°C (холодный спай: %.2f°C)\n", hot_temp, cold_temp); } delay(1000); } Термосопротивления PT100/PT1000Принцип: сопротивление платинового проводника линейно растёт с температурой. PT100: 100 Ом при 0°C, α = 0.00385 Ом/(Ом·°C) PT1000: 1000 Ом при 0°C (лучше для длинных кабелей) R(T) = R0 × [1 + A×T + B×T² + C×T³ × (T-100)] R0 = 100 Ом A = 3.9083×10⁻³ B = -5.775×10⁻⁷ C = -4.183×10⁻¹² (только при T < 0°C) Упрощённо для -50..+200°C: R(T) ≈ 100 × (1 + 0.00385 × T) T ≈ (R - 100) / 0.385 Схемы подключения: 2-проводная (дёшево, но ошибка от сопротивления кабеля): [ПЛК]──R_кабель──[PT100]──R_кабель──[ПЛК] Ошибка: ΔR_кабель = 2 × ρ × L / S При 10 м, 0.5 мм²: ΔR ≈ 0.7 Ом ≈ 1.8°C погрешность! 3-проводная (стандарт): [ПЛК]──R1──[PT100]──R2──[ПЛК] │ R3──────────[ПЛК] Измерительная схема компенсирует сопротивление одного провода 4-проводная (эталонная точность): [ПЛК]──I+──[PT100]──I-──[ПЛК] (ток через PT100) [ПЛК]──U+──[PT100]──U-──[ПЛК] (измерение напряжения) Сопротивление провода не влияет на точность Датчики давления: 4–20 мА в промышленностиОсновные типы:Пьезорезистивные: мембрана с тензодатчиками, сигнал 4–20 мА. Самые распространённые. Пьезоэлектрические: для динамических давлений (удары, взрывы). Заряд пропорционален давлению. Ёмкостные: высокая точность (0.01%), дорогие. Для точных технологических процессов. Подключение датчика 4–20 мА:Двухпроводная схема (+питание, -сигнал): 24В ──────────┬──────── Датчик (+) │ R_shunt (250 Ом) │ GND ──────────┴──────── Датчик (-) │ Измеряем U на R_shunt 4мА → 1.000В 20мА → 5.000В В ПЛК: аналоговый вход 1–5В или через преобразователь ток→напряжение def current_to_pressure(current_ma: float, pressure_min: float, pressure_max: float) -> float: """ Преобразование тока 4-20мА в давление. Args: current_ma: ток в мА (4.0..20.0) pressure_min: давление при 4мА (нижний предел датчика) pressure_max: давление при 20мА (верхний предел) Returns: давление в единицах pressure_min/max """ # Проверка обрыва линии if current_ma < 3.8: raise ValueError(f"Обрыв линии или ошибка датчика: {current_ma} мА") # Проверка превышения if current_ma > 20.5: raise ValueError(f"Превышение тока: {current_ma} мА") # Линейное масштабирование # 4мА = 0%, 20мА = 100% pct = (current_ma - 4.0) / 16.0 return pressure_min + pct * (pressure_max - pressure_min) # ADC напряжение → ток → давление def adc_voltage_to_pressure(voltage_v: float, shunt_ohm: float = 250.0, p_min: float = 0.0, p_max: float = 16.0) -> float: current_ma = voltage_v / shunt_ohm * 1000.0 return current_to_pressure(current_ma, p_min, p_max) # Пример: voltage = 2.5 # Вольт на шунте 250 Ом current = 2.5 / 250 * 1000 # = 10 мА pressure = current_to_pressure(current, 0, 16) # = 7.5 бар (середина диапазона) Индуктивные датчики: металл без контактаИндуктивный датчик (Inductive Proximity Sensor) обнаруживает металлические объекты без физического контакта. Принцип: высокочастотное электромагнитное поле. При попадании металла в зону — меняется амплитуда генератора → срабатывание. Дальность обнаружения зависит от металла: Сталь (St37): номинальная дальность × 1.0 Нержавейка (304): × 0.7–0.85 Алюминий: × 0.4–0.5 Медь, латунь: × 0.35–0.45 Типичные параметры: Диаметр: M8, M12, M18, M30 (стандартные серии) Дальность: 2–50 мм Выход: NPN или PNP, NO или NC Питание: 10–30В DC Частота переключения: до 3000–5000 Гц Пример выбора: Считать металлические детали на конвейере: M12, PNP NO, Sn=4 мм Контроль положения поршня цилиндра: M8 встраиваемый, PNP NO Подключение PNP к ПЛК с входом 24В: +24В ──────── Коричневый провод датчика (питание) Синий провод ────────────────────────── GND (0В) Чёрный провод ── DI вход ПЛК ─── ↗ 24В при срабатывании NPN подключение к ПЛК: +24В ────────────────────────────── DI вход ПЛК Чёрный провод ─── DI вход ПЛК ── ↘ 0В при срабатывании Ёмкостные датчики: любые материалыЁмкостной датчик (Capacitive) обнаруживает металлы, пластики, жидкости, порошки, дерево. Принцип: электрод датчика образует конденсатор с объектом. Приближение объекта → рост ёмкости → срабатывание. Применения: Контроль уровня сыпучих материалов (зерно, цемент, порошки) сквозь стенку ёмкости Обнаружение прозрачных объектов (стекло, пластик) — там, где оптика не работает Контроль присутствия жидкости в трубе (сквозь пластик) Счётчик таблеток/ампул на фармацевтическом конвейере Особенность: требует настройки чувствительности под конкретный материал и расстояние (потенциометр или IO-Link). Ультразвуковые датчики уровняПринцип: излучают ультразвуковой импульс → принимают эхо → время до эха = расстояние. Расстояние = v_звука × t_эхо / 2 v_звука ≈ 343 м/с при 20°C Поправка на температуру: v(T) = 331.5 + 0.606 × T(°C) При T=40°C: v = 331.5 + 0.606×40 = 355.7 м/с Ошибка без коррекции при 5м дальности: Δd = 5 × (355.7-343)/343 = 0.185 м = 18.5 см! Пример: SR-04 (HC-SR04) на Arduino: // HC-SR04: бюджетный датчик для прототипов (не промышленный!) // Промышленные: Pepperl+Fuchs, Microsonic, ifm, Banner const int TRIG_PIN = 9; const int ECHO_PIN = 10; void setup() { Serial.begin(115200); pinMode(TRIG_PIN, OUTPUT); pinMode(ECHO_PIN, INPUT); } float measure_distance_cm(float temp_celsius = 20.0) { // Отправляем импульс 10 мкс digitalWrite(TRIG_PIN, LOW); delayMicroseconds(2); digitalWrite(TRIG_PIN, HIGH); delayMicroseconds(10); digitalWrite(TRIG_PIN, LOW); // Измеряем длительность эхо unsigned long duration_us = pulseIn(ECHO_PIN, HIGH, 30000); // таймаут 30 мс if (duration_us == 0) { return -1; // Объект не найден или слишком далеко } // Расчёт расстояния с коррекцией температуры float speed_cms = (331.5 + 0.606 * temp_celsius) * 100.0 / 1000000.0; // см/мкс float distance = duration_us * speed_cms / 2.0; return distance; } // Уровень в резервуаре: float measure_tank_level(float tank_height_cm) { float distance = measure_distance_cm(25.0); if (distance < 0 || distance > tank_height_cm) return -1; float level_pct = (1.0 - distance / tank_height_cm) * 100.0; return max(0.0f, min(100.0f, level_pct)); } Мёртвая зона: HC-SR04 не измеряет до 2 см. Промышленные: от 1–3 мм. Проблемы: пена на поверхности жидкости, пыль, ветер, наклонные поверхности, температурные градиенты. Расходомеры: измерение потокаЭлектромагнитный (Flowmeter/Магнитный):Только электропроводящие жидкости (вода, кислоты, суспензии) Нет движущихся частей → долговечность Нет потерь давления Погрешность: 0.5–1% Сигнал: 4–20 мА + импульсный выход (число импульсов = объём) Вихревой (Vortex):Жидкости и газы Измеряет частоту вихрей (пропорциональна скорости) Минимальный расход: ограничен (при малом расходе не работает) Ультразвуковой (накладной / inline):Накладной: крепится снаружи трубы без врезки! Подходит для ретрофита существующих трубопроводов Для чистых жидкостей (пузыри искажают сигнал) Coriolis:Измеряет массовый расход напрямую (не объём!) Самый точный (0.1%), самый дорогой Работает с любыми жидкостями, суспензиями, вязкими средами Датчики вибрации: предиктивное обслуживаниеimport numpy as np from scipy.fft import rfft, rfftfreq from scipy.signal import find_peaks class VibrationAnalyzer: """ Анализ вибрации для диагностики подшипников и валов. Акселерометр: ADXL345 (I2C) или промышленный 4-20мА. """ def __init__(self, sample_rate: int = 1000): self.sample_rate = sample_rate def analyze(self, samples: np.ndarray, machine_rpm: float) -> dict: """ Полный анализ вибрационного сигнала. machine_rpm: скорость вращения (об/мин) для идентификации гармоник """ n = len(samples) # === ВРЕМЕННЫЕ ПОКАЗАТЕЛИ === rms = np.sqrt(np.mean(samples**2)) peak = np.max(np.abs(samples)) crest = peak / rms if rms > 0 else 0 # Эксцесс (Kurtosis): для обнаружения ударных дефектов mean = np.mean(samples) std = np.std(samples) kurtosis = np.mean(((samples - mean) / std)**4) if std > 0 else 0 # === СПЕКТРАЛЬНЫЙ АНАЛИЗ === # Оконная функция для уменьшения утечек window = np.hanning(n) spectrum = np.abs(rfft(samples * window)) * 2 / n freqs = rfftfreq(n, 1.0 / self.sample_rate) # Основная частота вращения f_rotation = machine_rpm / 60.0 # Поиск пиков в спектре peaks_idx, peak_props = find_peaks( spectrum, height=0.01 * np.max(spectrum), distance=5 ) peaks = [(float(freqs[i]), float(spectrum[i])) for i in peaks_idx] peaks.sort(key=lambda x: -x[1]) # По убыванию амплитуды # Идентификация характерных частот identified = {} for freq, amp in peaks[:10]: # Гармоники вращения for harmonic in range(1, 8): if abs(freq - harmonic * f_rotation) < 2.0: identified[f"{harmonic}x_rotation"] = (freq, amp) # === ДИАГНОСТИКА === # ISO 10816-3: нормы вибрации для промышленных машин # Класс 1 (малые): OK<2.3, WARN<4.5, CRIT<7.1 мм/с RMS # Класс 2 (средние): OK<4.5, WARN<7.1, CRIT<11.0 rms_velocity_mms = rms / (2 * np.pi * f_rotation) * 1000 if f_rotation > 0 else 0 if rms_velocity_mms < 2.3: iso_status = "Зона A (Хорошо)" elif rms_velocity_mms < 4.5: iso_status = "Зона B (Допустимо)" elif rms_velocity_mms < 7.1: iso_status = "Зона C (Внимание!)" else: iso_status = "Зона D (Опасно!)" # Диагностика по Kurtosis if kurtosis > 6: bearing_diagnosis = "Дефект подшипника (ударные нагрузки)" elif kurtosis > 4: bearing_diagnosis = "Начальный износ подшипника" else: bearing_diagnosis = "Норма" return { 'rms_g': round(rms, 4), 'peak_g': round(peak, 4), 'crest_factor': round(crest, 2), 'kurtosis': round(kurtosis, 2), 'rms_velocity_mms': round(rms_velocity_mms, 2), 'iso_status': iso_status, 'bearing_status': bearing_diagnosis, 'top_frequencies': peaks[:5], 'identified_harmonics': identified, } Калибровка: без неё данные не достоверныКаждый датчик имеет погрешности: смещение (offset), нелинейность, дрейф со временем и температурой. Калибровка — сравнение с эталоном и коррекция. def two_point_calibration(raw_low: float, ref_low: float, raw_high: float, ref_high: float, raw_measured: float) -> float: """ Двухточечная линейная калибровка. raw_low, raw_high: показания датчика в нижней и верхней точках ref_low, ref_high: эталонные значения в этих точках raw_measured: текущее показание датчика Пример: PT100 показывает 99.2 Ом при 0°C (вместо 100) и 138.9 при 100°C (вместо 138.5) calibrated = two_point_calibration(99.2, 100.0, 138.9, 138.5, current_reading) """ if raw_high == raw_low: return ref_low # Линейная интерполяция slope = (ref_high - ref_low) / (raw_high - raw_low) offset = ref_low - slope * raw_low return slope * raw_measured + offset Периодичность калибровки:Термопары: ежегодно или при замене PT100: 1–2 раза в год (дрейф незначителен) Датчики давления: раз в год или при смене диапазона Расходомеры: согласно паспорту (обычно 1 раз в год) Монтаж: правила, которые нельзя игнорироватьТемпературные датчики:✅ Погружение на 1/2–2/3 диаметра трубы ✅ Против потока (для лучшего теплообмена) ✅ Защитный карман (гильза) из нержавейки ❌ На наружной поверхности трубы (ошибка до 50°C!) ❌ В зоне завихрений (после колен, до 10D от колена) Датчики давления: ✅ Импульсные линии: уклон для самодренажа (для газа — вверх, для жидкости — вниз) ✅ Манометрический вентиль для обслуживания без остановки ❌ Прямое подключение к горячим/агрессивным средам без разделительного сосуда Индуктивные датчики: ✅ Расстояние > 2× диаметра от соседних металлических поверхностей ✅ Осевая нагрузка — только через крепёжную гайку, не на корпус ❌ Монтаж в металлический кронштейн вплотную (ложные срабатывания) ЗаключениеПравильный выбор датчика — это компромисс между точностью, диапазоном, стойкостью к среде, стоимостью и сложностью подключения. Никогда не выбирайте датчик по принципу "самый дешёвый" — плохой датчик в критическом месте обойдётся дороже в простоях и ремонтах. Всегда изучайте datasheet: реальный диапазон рабочих температур, степень защиты IP, материал контактной части. И никогда не экономьте на монтаже — половина проблем с датчиками — это неправильный монтаж, а не неисправность прибора. -
 SQL: язык, которому 50 лет, но он не устарелSQL изобрели в IBM в 1974 году. С тех пор появились NoSQL, NewSQL, GraphQL, временны́е базы данных, документные хранилища. Но SQL не умер — он стал стандартом для большинства задач работы с данными. Реляционные СУБД (PostgreSQL, MySQL, SQLite, MS SQL, Oracle) хранят данные в большинстве корпоративных систем мира. И даже "NoSQL" системы (ClickHouse, DuckDB, BigQuery) используют SQL-диалект. Знание SQL — это инвестиция с гарантированной отдачей для любого разработчика. Архитектура запроса: как PostgreSQL исполняет SQLПонимание этого даёт инсайт, почему одни запросы быстрые, а другие — нет: Текст запроса ↓ [Parser] — проверка синтаксиса ↓ [Rewriter] — разворачивание Views, правила ↓ [Planner/Optimizer] — КЛЮЧЕВОЙ ЭТАП! - Оценка стоимости разных планов - Выбор порядка JOIN-ов - Выбор алгоритма соединения (Hash Join, Nested Loop, Merge Join) - Решение: использовать индекс или seq scan ↓ [Executor] — выполнение выбранного плана ↓ Результат Планировщик работает на основе статистики (pg_statistics). Устаревшая статистика → неоптимальный план → медленный запрос. Поэтому важен ANALYZE или автовакуум. EXPLAIN ANALYZE: видим что происходит-- Всегда используйте ANALYZE для реального времени (но он выполняет запрос!) -- Для SELECT это безопасно. Для DML используйте ROLLBACK: -- BEGIN; EXPLAIN ANALYZE UPDATE ...; ROLLBACK; EXPLAIN (ANALYZE, BUFFERS, FORMAT TEXT) SELECT u.name, COUNT(o.id) as order_count, SUM(o.total) as total_sum FROM users u JOIN orders o ON o.user_id = u.id WHERE u.created_at > '2024-01-01' AND o.status = 'completed' GROUP BY u.id, u.name ORDER BY total_sum DESC LIMIT 20; -- Типичный вывод и как его читать: /* Limit (cost=1250.45..1250.50 rows=20 width=48) (actual time=45.231..45.234 rows=20 loops=1) -> Sort (cost=1250.45..1253.95 rows=1400 width=48) (actual time=45.228..45.231 rows=20 loops=1) Sort Key: (sum(o.total)) DESC Sort Method: top-N heapsort Memory: 27kB -> HashAggregate (cost=1190.23..1204.73 rows=1400 width=48) (actual time=44.123..45.012 rows=1823 loops=1) Group Key: u.id, u.name Batches: 1 Memory Usage: 657kB -> Hash Join (cost=485.30..1148.73 rows=8300 width=24) (actual time=2.341..38.201 rows=9843 loops=1) Hash Cond: (o.user_id = u.id) Buffers: shared hit=342 read=891 ← ВАЖНО! 891 блоков с диска! -> Seq Scan on orders o (cost=0.00..456.23 rows=12800 width=16) ↑ SEQ SCAN на большой таблице = тревожный сигнал! Filter: ((status)::text = 'completed'::text) Rows Removed by Filter: 23456 -> Hash (cost=423.55..423.55 rows=4940 width=16) (actual time=2.103..2.103 rows=4892 loops=1) -> Index Scan using idx_users_created on users u Index Cond: (created_at > '2024-01-01'::date) Planning Time: 0.523 ms Execution Time: 45.789 ms ← Реальное время выполнения */ Что искать в EXPLAIN:Сигнал Что значит Решение Seq Scan на большой таблице Нет индекса или не используется Добавить индекс Rows Removed by Filter: N (N >> результата) Фильтр работает после scan Индекс на колонку фильтра shared read: N (N > 1000) Много чтений с диска Индекс, увеличить shared_buffers Nested Loop при большом N Плохой алгоритм JOIN Статистика, индексы, rewrite Sort без using index Сортировка в памяти/диске Индекс на ORDER BY колонку Индексы: типы и когда применятьB-Tree (по умолчанию)Подходит для: =, <, >, BETWEEN, LIKE 'prefix%', ORDER BY, диапазоны дат. -- Обычный индекс CREATE INDEX idx_orders_user_id ON orders(user_id); -- Составной индекс (порядок важен!) -- Покрывает: WHERE user_id = X AND status = Y -- Покрывает: WHERE user_id = X (только первая колонка) -- НЕ покрывает: WHERE status = Y (без user_id) CREATE INDEX idx_orders_user_status ON orders(user_id, status); -- Частичный индекс (только для подмножества строк) -- Гораздо меньше, работает быстрее для частых запросов с фильтром CREATE INDEX idx_orders_active ON orders(created_at) WHERE status IN ('pending', 'processing'); -- Индекс с включёнными колонками (covering index) -- SELECT user_id, total FROM orders WHERE status = 'completed' -- будет выполнен только из индекса, без обращения к таблице! CREATE INDEX idx_orders_status_covering ON orders(status) INCLUDE (user_id, total); Hash индексТолько для = (равенство). Быстрее B-Tree для равенства, но нет диапазонов: CREATE INDEX idx_sessions_token ON sessions USING HASH (token); -- Отлично для: WHERE token = 'abc123' (авторизация) GIN (Generalized Inverted Index)Для массивов, JSONB, полнотекстового поиска, pg_trgm: -- Полнотекстовый поиск CREATE INDEX idx_articles_fts ON articles USING GIN (to_tsvector('russian', title || ' ' || body)); -- Поиск по JSONB CREATE INDEX idx_devices_meta ON devices USING GIN (metadata jsonb_path_ops); -- Запрос: WHERE metadata @> '{"type": "sensor"}' -- pg_trgm для LIKE '%substring%' (иначе seq scan!) CREATE EXTENSION IF NOT EXISTS pg_trgm; CREATE INDEX idx_products_name_trgm ON products USING GIN (name gin_trgm_ops); -- Запрос: WHERE name ILIKE '%насос%' BRIN (Block Range INdex)Для очень больших таблиц с монотонно возрастающими данными (временны́е метки): -- Таблица телеметрии: 10 миллиардов строк -- B-Tree индекс займёт 200 ГБ -- BRIN займёт 1 МБ! (хранит мин/макс по блокам) CREATE INDEX idx_telemetry_time_brin ON telemetry USING BRIN (measured_at) WITH (pages_per_range = 128); -- Работает только если данные ФИЗИЧЕСКИ упорядочены по времени -- (INSERT в хронологическом порядке) Оконные функции: SQL нового уровняОконные функции — одна из самых мощных возможностей SQL, которую многие не знают. -- Задача: для каждого заказа показать его номер в последовательности -- заказов этого клиента и общее количество заказов клиента SELECT id, user_id, created_at, total, -- Номер строки в партиции (по каждому user_id отдельно) ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY created_at) AS order_number, -- Ранг (при одинаковых значениях — одинаковый ранг, следующий пропускается) RANK() OVER (PARTITION BY user_id ORDER BY total DESC) AS rank_by_total, -- Dense Rank (без пропусков) DENSE_RANK() OVER (PARTITION BY user_id ORDER BY total DESC) AS dense_rank, -- Количество строк в партиции COUNT(*) OVER (PARTITION BY user_id) AS total_orders, -- Нарастающая сумма SUM(total) OVER (PARTITION BY user_id ORDER BY created_at ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS running_total, -- Скользящее среднее (последние 3 заказа) AVG(total) OVER (PARTITION BY user_id ORDER BY created_at ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS moving_avg_3, -- Предыдущее и следующее значение LAG(total, 1) OVER (PARTITION BY user_id ORDER BY created_at) AS prev_order_total, LEAD(total, 1) OVER (PARTITION BY user_id ORDER BY created_at) AS next_order_total, -- Процент от общей суммы клиента ROUND(total / SUM(total) OVER (PARTITION BY user_id) * 100, 2) AS pct_of_customer_total, -- Процентиль PERCENT_RANK() OVER (PARTITION BY user_id ORDER BY total) AS percentile FROM orders ORDER BY user_id, created_at; Практический пример: анализ телеметрии-- Обнаружение аномалий: значения > avg + 2*stddev WITH stats AS ( SELECT device_id, AVG(temperature) AS avg_temp, STDDEV(temperature) AS std_temp FROM telemetry WHERE measured_at > NOW() - INTERVAL '7 days' GROUP BY device_id ), windowed AS ( SELECT t.*, s.avg_temp, s.std_temp, -- Z-score (t.temperature - s.avg_temp) / NULLIF(s.std_temp, 0) AS z_score, -- Скользящее среднее за 5 измерений AVG(t.temperature) OVER ( PARTITION BY t.device_id ORDER BY t.measured_at ROWS BETWEEN 4 PRECEDING AND CURRENT ROW ) AS moving_avg_5, -- Предыдущее значение (для расчёта скорости изменения) LAG(t.temperature) OVER ( PARTITION BY t.device_id ORDER BY t.measured_at ) AS prev_temp, LAG(t.measured_at) OVER ( PARTITION BY t.device_id ORDER BY t.measured_at ) AS prev_time FROM telemetry t JOIN stats s ON s.device_id = t.device_id WHERE t.measured_at > NOW() - INTERVAL '24 hours' ) SELECT device_id, measured_at, temperature, ROUND(z_score::numeric, 2) AS z_score, ROUND(moving_avg_5::numeric, 2) AS moving_avg, -- Скорость изменения (°C/мин) ROUND( (temperature - prev_temp) / NULLIF(EXTRACT(EPOCH FROM (measured_at - prev_time)) / 60.0, 0) , 2) AS rate_per_min, CASE WHEN ABS(z_score) > 3 THEN 'КРИТИЧЕСКАЯ АНОМАЛИЯ' WHEN ABS(z_score) > 2 THEN 'Аномалия' ELSE 'Норма' END AS status FROM windowed WHERE ABS(z_score) > 2 ORDER BY ABS(z_score) DESC; CTE: читаемые и повторно используемые запросы-- CTE (Common Table Expression) — именованные подзапросы -- Делают сложные запросы читаемыми WITH -- Шаг 1: активные устройства за последние 24 часа active_devices AS ( SELECT DISTINCT device_id FROM telemetry WHERE measured_at > NOW() - INTERVAL '24 hours' ), -- Шаг 2: статистика по каждому устройству device_stats AS ( SELECT t.device_id, COUNT(*) AS reading_count, AVG(t.temperature) AS avg_temp, MAX(t.temperature) AS max_temp, MIN(t.temperature) AS min_temp, SUM(CASE WHEN t.fault THEN 1 ELSE 0 END) AS fault_count FROM telemetry t INNER JOIN active_devices ad ON ad.device_id = t.device_id WHERE t.measured_at > NOW() - INTERVAL '24 hours' GROUP BY t.device_id ), -- Шаг 3: ранжирование по количеству аварий ranked AS ( SELECT *, RANK() OVER (ORDER BY fault_count DESC) AS fault_rank FROM device_stats ) -- Финальный запрос SELECT r.device_id, d.name, d.location, r.reading_count, ROUND(r.avg_temp::numeric, 2) AS avg_temp, r.max_temp, r.fault_count, r.fault_rank, CASE WHEN r.fault_count > 10 THEN '🔴 Требует внимания' ELSE '🟢 OK' END AS status FROM ranked r JOIN devices d ON d.id = r.device_id ORDER BY r.fault_rank; Рекурсивные CTE: для деревьев и графов-- Дерево категорий оборудования WITH RECURSIVE category_tree AS ( -- Базовый случай: корневые категории SELECT id, name, parent_id, 1 AS depth, name::text AS path FROM categories WHERE parent_id IS NULL UNION ALL -- Рекурсивный шаг: дочерние категории SELECT c.id, c.name, c.parent_id, ct.depth + 1, ct.path || ' > ' || c.name FROM categories c INNER JOIN category_tree ct ON ct.id = c.parent_id ) SELECT depth, REPEAT(' ', depth - 1) || name AS name_indented, path FROM category_tree ORDER BY path; -- Результат: -- Оборудование -- Насосное оборудование -- Центробежные насосы -- Шестерённые насосы -- Нагреватели -- Ленточные Транзакции и ACID-- Пример транзакции: перевод средств -- ACID: Atomicity, Consistency, Isolation, Durability BEGIN; -- Несколько операций — или все, или ничего! UPDATE accounts SET balance = balance - 1000 WHERE id = 1; UPDATE accounts SET balance = balance + 1000 WHERE id = 2; INSERT INTO transactions (from_id, to_id, amount, created_at) VALUES (1, 2, 1000, NOW()); -- Проверка (если не OK — откатываем всё) DO $$ DECLARE balance DECIMAL; BEGIN SELECT balance INTO balance FROM accounts WHERE id = 1; IF balance < 0 THEN RAISE EXCEPTION 'Недостаточно средств!'; END IF; END; $$; COMMIT; -- Всё OK, фиксируем -- или ROLLBACK; -- Если что-то пошло не так -- Уровни изоляции транзакций: -- READ UNCOMMITTED: видит незафиксированные данные (грязное чтение) -- READ COMMITTED: видит только зафиксированные (по умолчанию в PG) -- REPEATABLE READ: повторное чтение даёт тот же результат -- SERIALIZABLE: полная изоляция, как последовательное выполнение SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; Партиционирование: для больших таблиц-- Партиционирование таблицы телеметрии по месяцам CREATE TABLE telemetry ( id BIGSERIAL, device_id INT NOT NULL, measured_at TIMESTAMPTZ NOT NULL, temperature FLOAT, pressure FLOAT, current FLOAT ) PARTITION BY RANGE (measured_at); -- Создаём партиции по месяцам CREATE TABLE telemetry_2024_01 PARTITION OF telemetry FOR VALUES FROM ('2024-01-01') TO ('2024-02-01'); CREATE TABLE telemetry_2024_02 PARTITION OF telemetry FOR VALUES FROM ('2024-02-01') TO ('2024-03-01'); -- ... и так далее -- Индексы создаются на каждой партиции отдельно CREATE INDEX ON telemetry_2024_01 (device_id, measured_at); CREATE INDEX ON telemetry_2024_02 (device_id, measured_at); -- Автоматическое создание партиций (pg_partman) -- SELECT partman.create_parent('public.telemetry', 'measured_at', -- 'native', 'monthly'); -- Преимущества: -- 1. Partition pruning: запрос за январь сканирует только telemetry_2024_01 -- 2. Быстрое удаление старых данных: DROP TABLE telemetry_2023_01 -- 3. Параллельное сканирование разных партиций N+1 проблема: самая частая ошибка-- N+1: вместо одного запроса делаем N+1 -- Типичная ошибка при работе с ORM -- ❌ ПЛОХО (в Python/PHP коде): -- users = db.execute("SELECT * FROM users LIMIT 100") -- for user in users: -- orders = db.execute("SELECT * FROM orders WHERE user_id = ?", user.id) -- Итого: 1 + 100 = 101 запрос! -- ✅ ХОРОШО: один JOIN SELECT u.id, u.name, u.email, COUNT(o.id) AS order_count, SUM(o.total) AS total_spent FROM users u LEFT JOIN orders o ON o.user_id = u.id GROUP BY u.id, u.name, u.email LIMIT 100; -- ✅ ХОРОШО: два запроса с IN (для сложных случаев) -- users = db.execute("SELECT * FROM users LIMIT 100") -- user_ids = [u.id for u in users] -- orders = db.execute("SELECT * FROM orders WHERE user_id = ANY(?)", user_ids) -- Итого: 2 запроса! Практические паттерны оптимизации-- 1. UPSERT (INSERT или UPDATE если существует) INSERT INTO device_status (device_id, status, updated_at) VALUES (1, 'online', NOW()) ON CONFLICT (device_id) DO UPDATE SET status = EXCLUDED.status, updated_at = EXCLUDED.updated_at; -- 2. Batch INSERT (вместо N отдельных INSERT) INSERT INTO telemetry (device_id, measured_at, temperature) VALUES (1, '2024-01-01 10:00', 25.3), (1, '2024-01-01 10:01', 25.4), (2, '2024-01-01 10:00', 22.1) -- До 1000 строк в одном запросе — намного быстрее! -- 3. COPY для массовой загрузки (самый быстрый способ) -- \COPY telemetry FROM '/data/telemetry.csv' CSV HEADER -- 4. Materialized View для сложных агрегатов CREATE MATERIALIZED VIEW daily_device_summary AS SELECT device_id, DATE(measured_at) AS day, AVG(temperature) AS avg_temp, MAX(temperature) AS max_temp, COUNT(*) AS readings FROM telemetry GROUP BY device_id, DATE(measured_at); CREATE UNIQUE INDEX ON daily_device_summary(device_id, day); -- Обновление (можно конкурентно, без блокировки SELECT) REFRESH MATERIALIZED VIEW CONCURRENTLY daily_device_summary; -- 5. EXPLAIN сначала, оптимизировать потом! -- Никогда не оптимизируйте наугад. Всегда смотрите план. PostgreSQL: важные настройки performance-- Ключевые параметры postgresql.conf для production: -- Память (зависит от RAM сервера): -- shared_buffers = 25% RAM (напр. 4GB для 16GB) -- effective_cache_size = 75% RAM -- work_mem = 64MB (для сортировок и hash join) -- maintenance_work_mem = 1GB (для VACUUM, CREATE INDEX) -- Диск (для SSD): -- random_page_cost = 1.1 (вместо 4.0) -- effective_io_concurrency = 200 -- Параллелизм: -- max_parallel_workers_per_gather = 4 -- max_worker_processes = 8 -- Checkpoint: -- checkpoint_completion_target = 0.9 -- wal_buffers = 64MB -- Проверка текущих настроек: SELECT name, setting, unit, context FROM pg_settings WHERE name IN ('shared_buffers', 'work_mem', 'max_connections'); -- Статистика медленных запросов (pg_stat_statements): CREATE EXTENSION IF NOT EXISTS pg_stat_statements; SELECT substring(query, 1, 80) AS query_short, calls, ROUND(total_exec_time::numeric / 1000, 2) AS total_sec, ROUND(mean_exec_time::numeric, 2) AS mean_ms, rows FROM pg_stat_statements ORDER BY total_exec_time DESC LIMIT 20; ЗаключениеSQL — не просто "язык запросов", это язык управления данными. Понимание планировщика, правильное использование индексов, оконные функции и CTE — это инструменты, которые превращают "работает" в "работает быстро и масштабируется". Практический совет: запустите pg_stat_statements на вашем production-сервере прямо сейчас. Посмотрите топ-20 медленных запросов. С вероятностью 80% — там найдётся очевидная оптимизация, которая ускорит приложение в разы. Инвестируйте в "Use The Index, Luke" (use-the-index-luke.com) — лучшее бесплатное руководство по индексам SQL. И всегда: EXPLAIN ANALYZE перед любой "оптимизацией".
SQL: язык, которому 50 лет, но он не устарелSQL изобрели в IBM в 1974 году. С тех пор появились NoSQL, NewSQL, GraphQL, временны́е базы данных, документные хранилища. Но SQL не умер — он стал стандартом для большинства задач работы с данными. Реляционные СУБД (PostgreSQL, MySQL, SQLite, MS SQL, Oracle) хранят данные в большинстве корпоративных систем мира. И даже "NoSQL" системы (ClickHouse, DuckDB, BigQuery) используют SQL-диалект. Знание SQL — это инвестиция с гарантированной отдачей для любого разработчика. Архитектура запроса: как PostgreSQL исполняет SQLПонимание этого даёт инсайт, почему одни запросы быстрые, а другие — нет: Текст запроса ↓ [Parser] — проверка синтаксиса ↓ [Rewriter] — разворачивание Views, правила ↓ [Planner/Optimizer] — КЛЮЧЕВОЙ ЭТАП! - Оценка стоимости разных планов - Выбор порядка JOIN-ов - Выбор алгоритма соединения (Hash Join, Nested Loop, Merge Join) - Решение: использовать индекс или seq scan ↓ [Executor] — выполнение выбранного плана ↓ Результат Планировщик работает на основе статистики (pg_statistics). Устаревшая статистика → неоптимальный план → медленный запрос. Поэтому важен ANALYZE или автовакуум. EXPLAIN ANALYZE: видим что происходит-- Всегда используйте ANALYZE для реального времени (но он выполняет запрос!) -- Для SELECT это безопасно. Для DML используйте ROLLBACK: -- BEGIN; EXPLAIN ANALYZE UPDATE ...; ROLLBACK; EXPLAIN (ANALYZE, BUFFERS, FORMAT TEXT) SELECT u.name, COUNT(o.id) as order_count, SUM(o.total) as total_sum FROM users u JOIN orders o ON o.user_id = u.id WHERE u.created_at > '2024-01-01' AND o.status = 'completed' GROUP BY u.id, u.name ORDER BY total_sum DESC LIMIT 20; -- Типичный вывод и как его читать: /* Limit (cost=1250.45..1250.50 rows=20 width=48) (actual time=45.231..45.234 rows=20 loops=1) -> Sort (cost=1250.45..1253.95 rows=1400 width=48) (actual time=45.228..45.231 rows=20 loops=1) Sort Key: (sum(o.total)) DESC Sort Method: top-N heapsort Memory: 27kB -> HashAggregate (cost=1190.23..1204.73 rows=1400 width=48) (actual time=44.123..45.012 rows=1823 loops=1) Group Key: u.id, u.name Batches: 1 Memory Usage: 657kB -> Hash Join (cost=485.30..1148.73 rows=8300 width=24) (actual time=2.341..38.201 rows=9843 loops=1) Hash Cond: (o.user_id = u.id) Buffers: shared hit=342 read=891 ← ВАЖНО! 891 блоков с диска! -> Seq Scan on orders o (cost=0.00..456.23 rows=12800 width=16) ↑ SEQ SCAN на большой таблице = тревожный сигнал! Filter: ((status)::text = 'completed'::text) Rows Removed by Filter: 23456 -> Hash (cost=423.55..423.55 rows=4940 width=16) (actual time=2.103..2.103 rows=4892 loops=1) -> Index Scan using idx_users_created on users u Index Cond: (created_at > '2024-01-01'::date) Planning Time: 0.523 ms Execution Time: 45.789 ms ← Реальное время выполнения */ Что искать в EXPLAIN:Сигнал Что значит Решение Seq Scan на большой таблице Нет индекса или не используется Добавить индекс Rows Removed by Filter: N (N >> результата) Фильтр работает после scan Индекс на колонку фильтра shared read: N (N > 1000) Много чтений с диска Индекс, увеличить shared_buffers Nested Loop при большом N Плохой алгоритм JOIN Статистика, индексы, rewrite Sort без using index Сортировка в памяти/диске Индекс на ORDER BY колонку Индексы: типы и когда применятьB-Tree (по умолчанию)Подходит для: =, <, >, BETWEEN, LIKE 'prefix%', ORDER BY, диапазоны дат. -- Обычный индекс CREATE INDEX idx_orders_user_id ON orders(user_id); -- Составной индекс (порядок важен!) -- Покрывает: WHERE user_id = X AND status = Y -- Покрывает: WHERE user_id = X (только первая колонка) -- НЕ покрывает: WHERE status = Y (без user_id) CREATE INDEX idx_orders_user_status ON orders(user_id, status); -- Частичный индекс (только для подмножества строк) -- Гораздо меньше, работает быстрее для частых запросов с фильтром CREATE INDEX idx_orders_active ON orders(created_at) WHERE status IN ('pending', 'processing'); -- Индекс с включёнными колонками (covering index) -- SELECT user_id, total FROM orders WHERE status = 'completed' -- будет выполнен только из индекса, без обращения к таблице! CREATE INDEX idx_orders_status_covering ON orders(status) INCLUDE (user_id, total); Hash индексТолько для = (равенство). Быстрее B-Tree для равенства, но нет диапазонов: CREATE INDEX idx_sessions_token ON sessions USING HASH (token); -- Отлично для: WHERE token = 'abc123' (авторизация) GIN (Generalized Inverted Index)Для массивов, JSONB, полнотекстового поиска, pg_trgm: -- Полнотекстовый поиск CREATE INDEX idx_articles_fts ON articles USING GIN (to_tsvector('russian', title || ' ' || body)); -- Поиск по JSONB CREATE INDEX idx_devices_meta ON devices USING GIN (metadata jsonb_path_ops); -- Запрос: WHERE metadata @> '{"type": "sensor"}' -- pg_trgm для LIKE '%substring%' (иначе seq scan!) CREATE EXTENSION IF NOT EXISTS pg_trgm; CREATE INDEX idx_products_name_trgm ON products USING GIN (name gin_trgm_ops); -- Запрос: WHERE name ILIKE '%насос%' BRIN (Block Range INdex)Для очень больших таблиц с монотонно возрастающими данными (временны́е метки): -- Таблица телеметрии: 10 миллиардов строк -- B-Tree индекс займёт 200 ГБ -- BRIN займёт 1 МБ! (хранит мин/макс по блокам) CREATE INDEX idx_telemetry_time_brin ON telemetry USING BRIN (measured_at) WITH (pages_per_range = 128); -- Работает только если данные ФИЗИЧЕСКИ упорядочены по времени -- (INSERT в хронологическом порядке) Оконные функции: SQL нового уровняОконные функции — одна из самых мощных возможностей SQL, которую многие не знают. -- Задача: для каждого заказа показать его номер в последовательности -- заказов этого клиента и общее количество заказов клиента SELECT id, user_id, created_at, total, -- Номер строки в партиции (по каждому user_id отдельно) ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY created_at) AS order_number, -- Ранг (при одинаковых значениях — одинаковый ранг, следующий пропускается) RANK() OVER (PARTITION BY user_id ORDER BY total DESC) AS rank_by_total, -- Dense Rank (без пропусков) DENSE_RANK() OVER (PARTITION BY user_id ORDER BY total DESC) AS dense_rank, -- Количество строк в партиции COUNT(*) OVER (PARTITION BY user_id) AS total_orders, -- Нарастающая сумма SUM(total) OVER (PARTITION BY user_id ORDER BY created_at ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS running_total, -- Скользящее среднее (последние 3 заказа) AVG(total) OVER (PARTITION BY user_id ORDER BY created_at ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS moving_avg_3, -- Предыдущее и следующее значение LAG(total, 1) OVER (PARTITION BY user_id ORDER BY created_at) AS prev_order_total, LEAD(total, 1) OVER (PARTITION BY user_id ORDER BY created_at) AS next_order_total, -- Процент от общей суммы клиента ROUND(total / SUM(total) OVER (PARTITION BY user_id) * 100, 2) AS pct_of_customer_total, -- Процентиль PERCENT_RANK() OVER (PARTITION BY user_id ORDER BY total) AS percentile FROM orders ORDER BY user_id, created_at; Практический пример: анализ телеметрии-- Обнаружение аномалий: значения > avg + 2*stddev WITH stats AS ( SELECT device_id, AVG(temperature) AS avg_temp, STDDEV(temperature) AS std_temp FROM telemetry WHERE measured_at > NOW() - INTERVAL '7 days' GROUP BY device_id ), windowed AS ( SELECT t.*, s.avg_temp, s.std_temp, -- Z-score (t.temperature - s.avg_temp) / NULLIF(s.std_temp, 0) AS z_score, -- Скользящее среднее за 5 измерений AVG(t.temperature) OVER ( PARTITION BY t.device_id ORDER BY t.measured_at ROWS BETWEEN 4 PRECEDING AND CURRENT ROW ) AS moving_avg_5, -- Предыдущее значение (для расчёта скорости изменения) LAG(t.temperature) OVER ( PARTITION BY t.device_id ORDER BY t.measured_at ) AS prev_temp, LAG(t.measured_at) OVER ( PARTITION BY t.device_id ORDER BY t.measured_at ) AS prev_time FROM telemetry t JOIN stats s ON s.device_id = t.device_id WHERE t.measured_at > NOW() - INTERVAL '24 hours' ) SELECT device_id, measured_at, temperature, ROUND(z_score::numeric, 2) AS z_score, ROUND(moving_avg_5::numeric, 2) AS moving_avg, -- Скорость изменения (°C/мин) ROUND( (temperature - prev_temp) / NULLIF(EXTRACT(EPOCH FROM (measured_at - prev_time)) / 60.0, 0) , 2) AS rate_per_min, CASE WHEN ABS(z_score) > 3 THEN 'КРИТИЧЕСКАЯ АНОМАЛИЯ' WHEN ABS(z_score) > 2 THEN 'Аномалия' ELSE 'Норма' END AS status FROM windowed WHERE ABS(z_score) > 2 ORDER BY ABS(z_score) DESC; CTE: читаемые и повторно используемые запросы-- CTE (Common Table Expression) — именованные подзапросы -- Делают сложные запросы читаемыми WITH -- Шаг 1: активные устройства за последние 24 часа active_devices AS ( SELECT DISTINCT device_id FROM telemetry WHERE measured_at > NOW() - INTERVAL '24 hours' ), -- Шаг 2: статистика по каждому устройству device_stats AS ( SELECT t.device_id, COUNT(*) AS reading_count, AVG(t.temperature) AS avg_temp, MAX(t.temperature) AS max_temp, MIN(t.temperature) AS min_temp, SUM(CASE WHEN t.fault THEN 1 ELSE 0 END) AS fault_count FROM telemetry t INNER JOIN active_devices ad ON ad.device_id = t.device_id WHERE t.measured_at > NOW() - INTERVAL '24 hours' GROUP BY t.device_id ), -- Шаг 3: ранжирование по количеству аварий ranked AS ( SELECT *, RANK() OVER (ORDER BY fault_count DESC) AS fault_rank FROM device_stats ) -- Финальный запрос SELECT r.device_id, d.name, d.location, r.reading_count, ROUND(r.avg_temp::numeric, 2) AS avg_temp, r.max_temp, r.fault_count, r.fault_rank, CASE WHEN r.fault_count > 10 THEN '🔴 Требует внимания' ELSE '🟢 OK' END AS status FROM ranked r JOIN devices d ON d.id = r.device_id ORDER BY r.fault_rank; Рекурсивные CTE: для деревьев и графов-- Дерево категорий оборудования WITH RECURSIVE category_tree AS ( -- Базовый случай: корневые категории SELECT id, name, parent_id, 1 AS depth, name::text AS path FROM categories WHERE parent_id IS NULL UNION ALL -- Рекурсивный шаг: дочерние категории SELECT c.id, c.name, c.parent_id, ct.depth + 1, ct.path || ' > ' || c.name FROM categories c INNER JOIN category_tree ct ON ct.id = c.parent_id ) SELECT depth, REPEAT(' ', depth - 1) || name AS name_indented, path FROM category_tree ORDER BY path; -- Результат: -- Оборудование -- Насосное оборудование -- Центробежные насосы -- Шестерённые насосы -- Нагреватели -- Ленточные Транзакции и ACID-- Пример транзакции: перевод средств -- ACID: Atomicity, Consistency, Isolation, Durability BEGIN; -- Несколько операций — или все, или ничего! UPDATE accounts SET balance = balance - 1000 WHERE id = 1; UPDATE accounts SET balance = balance + 1000 WHERE id = 2; INSERT INTO transactions (from_id, to_id, amount, created_at) VALUES (1, 2, 1000, NOW()); -- Проверка (если не OK — откатываем всё) DO $$ DECLARE balance DECIMAL; BEGIN SELECT balance INTO balance FROM accounts WHERE id = 1; IF balance < 0 THEN RAISE EXCEPTION 'Недостаточно средств!'; END IF; END; $$; COMMIT; -- Всё OK, фиксируем -- или ROLLBACK; -- Если что-то пошло не так -- Уровни изоляции транзакций: -- READ UNCOMMITTED: видит незафиксированные данные (грязное чтение) -- READ COMMITTED: видит только зафиксированные (по умолчанию в PG) -- REPEATABLE READ: повторное чтение даёт тот же результат -- SERIALIZABLE: полная изоляция, как последовательное выполнение SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; Партиционирование: для больших таблиц-- Партиционирование таблицы телеметрии по месяцам CREATE TABLE telemetry ( id BIGSERIAL, device_id INT NOT NULL, measured_at TIMESTAMPTZ NOT NULL, temperature FLOAT, pressure FLOAT, current FLOAT ) PARTITION BY RANGE (measured_at); -- Создаём партиции по месяцам CREATE TABLE telemetry_2024_01 PARTITION OF telemetry FOR VALUES FROM ('2024-01-01') TO ('2024-02-01'); CREATE TABLE telemetry_2024_02 PARTITION OF telemetry FOR VALUES FROM ('2024-02-01') TO ('2024-03-01'); -- ... и так далее -- Индексы создаются на каждой партиции отдельно CREATE INDEX ON telemetry_2024_01 (device_id, measured_at); CREATE INDEX ON telemetry_2024_02 (device_id, measured_at); -- Автоматическое создание партиций (pg_partman) -- SELECT partman.create_parent('public.telemetry', 'measured_at', -- 'native', 'monthly'); -- Преимущества: -- 1. Partition pruning: запрос за январь сканирует только telemetry_2024_01 -- 2. Быстрое удаление старых данных: DROP TABLE telemetry_2023_01 -- 3. Параллельное сканирование разных партиций N+1 проблема: самая частая ошибка-- N+1: вместо одного запроса делаем N+1 -- Типичная ошибка при работе с ORM -- ❌ ПЛОХО (в Python/PHP коде): -- users = db.execute("SELECT * FROM users LIMIT 100") -- for user in users: -- orders = db.execute("SELECT * FROM orders WHERE user_id = ?", user.id) -- Итого: 1 + 100 = 101 запрос! -- ✅ ХОРОШО: один JOIN SELECT u.id, u.name, u.email, COUNT(o.id) AS order_count, SUM(o.total) AS total_spent FROM users u LEFT JOIN orders o ON o.user_id = u.id GROUP BY u.id, u.name, u.email LIMIT 100; -- ✅ ХОРОШО: два запроса с IN (для сложных случаев) -- users = db.execute("SELECT * FROM users LIMIT 100") -- user_ids = [u.id for u in users] -- orders = db.execute("SELECT * FROM orders WHERE user_id = ANY(?)", user_ids) -- Итого: 2 запроса! Практические паттерны оптимизации-- 1. UPSERT (INSERT или UPDATE если существует) INSERT INTO device_status (device_id, status, updated_at) VALUES (1, 'online', NOW()) ON CONFLICT (device_id) DO UPDATE SET status = EXCLUDED.status, updated_at = EXCLUDED.updated_at; -- 2. Batch INSERT (вместо N отдельных INSERT) INSERT INTO telemetry (device_id, measured_at, temperature) VALUES (1, '2024-01-01 10:00', 25.3), (1, '2024-01-01 10:01', 25.4), (2, '2024-01-01 10:00', 22.1) -- До 1000 строк в одном запросе — намного быстрее! -- 3. COPY для массовой загрузки (самый быстрый способ) -- \COPY telemetry FROM '/data/telemetry.csv' CSV HEADER -- 4. Materialized View для сложных агрегатов CREATE MATERIALIZED VIEW daily_device_summary AS SELECT device_id, DATE(measured_at) AS day, AVG(temperature) AS avg_temp, MAX(temperature) AS max_temp, COUNT(*) AS readings FROM telemetry GROUP BY device_id, DATE(measured_at); CREATE UNIQUE INDEX ON daily_device_summary(device_id, day); -- Обновление (можно конкурентно, без блокировки SELECT) REFRESH MATERIALIZED VIEW CONCURRENTLY daily_device_summary; -- 5. EXPLAIN сначала, оптимизировать потом! -- Никогда не оптимизируйте наугад. Всегда смотрите план. PostgreSQL: важные настройки performance-- Ключевые параметры postgresql.conf для production: -- Память (зависит от RAM сервера): -- shared_buffers = 25% RAM (напр. 4GB для 16GB) -- effective_cache_size = 75% RAM -- work_mem = 64MB (для сортировок и hash join) -- maintenance_work_mem = 1GB (для VACUUM, CREATE INDEX) -- Диск (для SSD): -- random_page_cost = 1.1 (вместо 4.0) -- effective_io_concurrency = 200 -- Параллелизм: -- max_parallel_workers_per_gather = 4 -- max_worker_processes = 8 -- Checkpoint: -- checkpoint_completion_target = 0.9 -- wal_buffers = 64MB -- Проверка текущих настроек: SELECT name, setting, unit, context FROM pg_settings WHERE name IN ('shared_buffers', 'work_mem', 'max_connections'); -- Статистика медленных запросов (pg_stat_statements): CREATE EXTENSION IF NOT EXISTS pg_stat_statements; SELECT substring(query, 1, 80) AS query_short, calls, ROUND(total_exec_time::numeric / 1000, 2) AS total_sec, ROUND(mean_exec_time::numeric, 2) AS mean_ms, rows FROM pg_stat_statements ORDER BY total_exec_time DESC LIMIT 20; ЗаключениеSQL — не просто "язык запросов", это язык управления данными. Понимание планировщика, правильное использование индексов, оконные функции и CTE — это инструменты, которые превращают "работает" в "работает быстро и масштабируется". Практический совет: запустите pg_stat_statements на вашем production-сервере прямо сейчас. Посмотрите топ-20 медленных запросов. С вероятностью 80% — там найдётся очевидная оптимизация, которая ускорит приложение в разы. Инвестируйте в "Use The Index, Luke" (use-the-index-luke.com) — лучшее бесплатное руководство по индексам SQL. И всегда: EXPLAIN ANALYZE перед любой "оптимизацией". -
 PCB-дизайн: мост между схемой и устройствомОтличная схема в плохом PCB-дизайне — это источник помех, нестабильная работа, проблемы с EMC и перегрев. Хороший PCB-дизайн — это такая же инженерная дисциплина, как схемотехника. Современные инструменты доступны бесплатно (KiCad), производство быстрое и дешёвое (JLCPCB, PCBWay, OSHPark — 5 плат за $2 с доставкой за 2 недели). Барьер для входа в PCB-разработку никогда не был ниже. Но количество "тонких мест" не уменьшилось. Сегодня — практика без воды. Инструменты: что выбратьKiCad (бесплатно, открытый исходный код)Версия 7/8 — функционально близка к коммерческим решениям Отличный Schematic Editor и PCB Editor SPICE-симуляция, 3D-просмотр Огромная библиотека компонентов, активное сообщество Рекомендация: для большинства проектов вполне достаточно Altium DesignerПромышленный стандарт в телекоме и аэрокосмосе $8 000+/год лицензия Нельзя просто взять и попробовать CircuitMaker (бесплатная версия Altium) — сильно урезана Eagle (Autodesk)Бесплатно до 2 слоёв и 80 см² Хорошая экосистема библиотек SparkFun/Adafruit Интегрируется с Fusion 360 EasyEDA / LCEDAБраузерный, бесплатный Прямая интеграция с JLCPCB и их библиотекой компонентов Быстрый старт для простых проектов Процесс разработки: от идеи до платы1. Спецификация → 2. Схема → 3. Выбор корпуса → 4. Разводка → 5. DRC/проверки → 6. Генерация Gerber → 7. Заказ → 8. Пайка → 9. Отладка Шаг 1: Схема (Schematic)Правила хорошей схемы: Читается слева направо: сигнал течёт от входа к выходу VCC сверху, GND снизу: стандартная конвенция Все пины обозначены: нет "hanging pins" без назначения Развязочные конденсаторы: рядом с каждой микросхемой на схеме (не просто в угол!) Комментарии: номиналы, допуски, критичные параметры Обязательные компоненты для питания: - Входной конденсатор: электролит 100 мкФ/16В (bulk capacitor) - Bypass конденсатор: керамика 100 нФ X7R рядом с каждым VCC пином IC - Bypass конденсатор: 10 нФ дополнительно для высокочастотных IC - Ferrite bead (если нужна изоляция аналоговой и цифровой земли) Шаг 2: Footprint и 3D-моделиВыбор правильного корпуса компонента критически важен: Проверьте datasheet производителя — landing pattern (рекомендуемый footprint) IPC-7351 — стандарт land pattern для SMD Предпочитайте компоненты из основных серий (0402, 0603, 0805 — легко заказать) Слои PCB: понимание стекаДвухслойная PCB (2-layer):─── Copper Top (компоненты, сигналы) ─── Core (диэлектрик FR4, 1.6 мм) ─── Copper Bottom (земля, сигналы) Дёшево ($2–5 за 10 плат), достаточно для большинства низкочастотных проектов. Четырёхслойная PCB (4-layer):─── Layer 1: Copper Top (сигналы, компоненты) ─── Prepreg (диэлектрик) ─── Layer 2: Ground Plane (сплошная земля!) ─── Core ─── Layer 3: Power Plane (питание) ─── Prepreg ─── Layer 4: Copper Bottom (сигналы) Дороже (~$15–30 за 10 плат), но: Слой земли под каждым сигнальным слоем — контролируемый импеданс Чистое питание (мало помех) Лучшая EMC Обязательна при F > 50 МГц или быстрых фронтах Земляной полигон (Ground Plane): основа всегоЭто самое важное правило PCB-дизайна. Сплошной медный полигон на слое GND: Почему это важно: Низкоиндуктивный путь возврата тока для каждого сигнала Экранирование сигнальных слоёв Тепловая масса для компонентов Референс для импеданса сигналов ПРАВИЛЬНО: земля под каждым сигнальным трэком ─Signal──────────────────────────────── Layer 1 ─────────────────────────────────────── Layer 2 (GND plane) Ток сигнала течёт по трэку, ток возврата — прямо под ним по плоскости (минимальная петля!) НЕПРАВИЛЬНО: нет плоскости, возврат по произвольному пути ─Signal──────────────────────────────── Layer 1 ──────────GND wire──────────────────── Layer 2 Ток возврата ищет произвольный путь → большая петля → EMI! Критические правила полигона:Не разрезайте плоскость без необходимости! ❌ Плохо: прорезь делит плоскость на два острова ───────────────────────────────────────────────── ╔═══════════════════╗ ← Прорезь! ─────────╝ ╚──────────────────── Ток возврата вынужден огибать прорезь → большая петля → EMI ✅ Хорошо: полигон цельный ───────────────────────────────────────────────────────────── (никаких прорезей без веской причины) ───────────────────────────────────────────────────────────── Via stitching — соединение полигонов между слоями: Размещайте заземляющие виа равномерно по всей плате (через каждые 1–2 см). Это снижает индуктивность плоскости. Импеданс трэков: для высокоскоростных сигналовПри частоте выше ~100 МГц или временах нарастания фронта <2нс — трэки нужно рассматривать как длинные линии. Импеданс трэка должен совпадать с импедансом источника и нагрузки (обычно 50 Ом для одиночного трэка или 100 Ом для дифференциальной пары). Формула для микрополосковой линии (Microstrip):Трэк на поверхностном слое над плоскостью земли: Z0 ≈ (87 / √(εr + 1.41)) × ln(5.98 × h / (0.8 × w + t)) Где: εr = диэлектрическая проницаемость (FR4: 4.2–4.5) h = расстояние от трэка до плоскости, мкм w = ширина трэка, мкм t = толщина меди, мкм (стандарт 1oz = 35 мкм) Для FR4, 4-слойная плата, h=200 мкм: 50 Ом → w ≈ 450 мкм (0.45 мм) 75 Ом → w ≈ 200 мкм (0.20 мм) Практически: используйте онлайн-калькуляторы (Saturn PCB Toolkit, Polar Si9000) или параметр stackup от производителя платы (JLCPCB публикует точные параметры своего FR4). Дифференциальные парыUSB, LVDS, HDMI, Ethernet, SerDes — все используют дифференциальные пары. Правила трассировки: Правила дифференциальных пар: 1. Одинаковая длина обоих трэков (skew < 5 мил/пс сигнала) 2. Одинаковое расстояние между трэками по всей длине (coupling) 3. Расстояние между трэками пары: 2-3 толщины диэлектрика 4. Без прямых углов (45° или радиусы) 5. Пересечение плоскости GND: только перпендикулярно, не вдоль щели USB FS (12 Мбит/с): Z_diff = 90 Ом, зазор 150 мкм USB HS (480 Мбит/с): Z_diff = 90 Ом, контроль длины ±0.1 мм Ethernet 100M: Z_diff = 100 Ом через трансформатор LVDS: Z_diff = 100 Ом Декупплинг конденсаторы: где и какиеСтратегия декупплинга (от источника питания к IC): [Источник] → [100 мкФ electrolytic] → [10 мкФ MLCC] → [100 нФ MLCC] → [IC] (bulk, далеко) (medium, ближе) (bypass, вплотную) Расположение на плате: ┌────────────────────────────────────┐ │ ┌──────┐ │ │ │ IC │ ← 100нФ вплотную к VCC пину │ └──────┘ ← 10нФ рядом │ ... │ │ [100мкФ] │ └────────────────────────────────────┘ Расстояние: - 100 нФ: ≤ 1 мм от VCC пина IC - 10 нФ: ≤ 3 мм - 100 мкФ: ≤ 10 мм НЕПРАВИЛЬНО: конденсатор в угол платы далеко от IC Эффективность падает экспоненциально с расстоянием! Выбор диэлектрика конденсатора:Диэлектрик Применение Зависимость от V/T X7R Bypass, фильтры (100 пФ – 10 мкФ) Умеренная X5R Bulk bypass (1 мкФ – 47 мкФ) Значительная при V C0G/NP0 Точные цепи, LC-фильтры Минимальная Y5V Не использовать в серьёзных проектах Огромная (-80%!) Важно: MLCC конденсатор 10 мкФ X5R 6.3В при напряжении 5В теряет 60% ёмкости из-за DC bias! Проверяйте даташит. Тепловой дизайн на PCBТепловое сопротивление медной области: R_th = L / (λ × A) = L / (380 Вт/(м·К) × ширина × толщина) Для FR4 (плохой теплопроводник, λ=0.3 Вт/(м·К)): Тепло течёт ПО МЕДИ, не через диэлектрик! Рекомендации: 1. Thermal vias под горячими компонентами: ┌──────────────────────────┐ │ IC (рассеивает 2 Вт) │ │ ●●●●●●●●●●●●●●●●●●● │ ← via array к Cu plane └──────────────────────────┘ Диаметр via: 0.3 мм, шаг: 0.8–1.0 мм 2. Copper pour (медный полигон) рядом с горячим компонентом 3. Radiator pad: обнажённая медь сверху для конвекции Расчёт температуры: T_junction = T_ambient + P × (R_th_jc + R_th_board + R_th_air) ↑ Это то, на что влияет PCB-дизайн EMC: электромагнитная совместимостьПлохой PCB-дизайн — главная причина проблем с EMC-сертификацией. Три правила EMC для PCB:1. Минимизировать площадь токовых петель: Высокочастотный ток протекает: Source → трэк → нагрузка → возврат по плоскости GND (под трэком) Площадь петли = длина трэка × расстояние до плоскости Уменьшить расстояние = 4-слойка со сплошной GND плоскостью 2. Разделить аналоговую и цифровую землю правильно: Популярный МИФ: "нужно разделить AGND и DGND полностью" РЕАЛЬНОСТЬ: один сплошной полигон GND, аналоговые компоненты в одном углу, цифровые в другом. Соединяйте земли в ОДНОЙ точке под ADC/DAC. Разрезать полигон почти никогда не нужно и часто вредно! 3. Развязка питания IC: Уже разобрали выше — 100нФ вплотную к каждому VCC пину. Дополнительные меры EMC:Ferrite bead в линии питания шумных цифровых блоков Common-mode фильтры на интерфейсных линиях Guard ring (защитное кольцо) вокруг аналоговых блоков Минимизировать длину высокочастотных трэков Правила трассировки: шпаргалкаШирина трэков: - Питание (до 1А): 0.5 мм - Питание (до 2А): 1.0 мм - Питание (до 5А): 2.5 мм - Сигналы: 0.15–0.25 мм (минимум производства: обычно 0.1 мм) Зазоры: - Сигнал-сигнал: ≥ 0.15 мм (производственный минимум) - 100В AC: ≥ 1 мм (по воздуху), 2 мм (по поверхности) - 250В AC: ≥ 2 мм / 4 мм Переходные отверстия (via): - Стандарт: диаметр 0.6 мм (отверстие 0.3 мм) - Micro via: 0.2 мм — дорого, только если необходимо - Технологические отверстия (крепёжные): нет меди, 3.2 мм (под M3) Углы трэков: ✅ 45° (стандарт) ✅ Радиусы (лучше для высоких частот) ❌ 90° прямые углы (устарелая проблема, но лучше избегать) Подготовка к производству: Gerber файлыНабор файлов для производства: Gerber файлы: .GTL - Top Copper (верхний слой меди) .GBL - Bottom Copper .GTS - Top Solder Mask (маска верхнего слоя) .GBS - Bottom Solder Mask .GTO - Top Silkscreen (маркировка) .GBO - Bottom Silkscreen .GKO - Board Outline (контур платы) .GM1..N - Inner layers (внутренние слои, если есть) Drill файл: .DRL или .XLN - координаты и размеры отверстий BOM (Bill of Materials): .CSV - список компонентов с номиналами, производителем, part number Pick and Place: .CSV - координаты и ориентация SMD компонентов (для PCBA) JLCPCB: заказ платы и PCBA-сборкиJLCPCB — наиболее популярный среди разработчиков производитель: Параметры стандартного заказа: Количество: 5 штук Слои: 2 Размер: ≤ 100×100 мм Цена: $2 + доставка Срок: 2 дня производство + 1-2 недели доставка PCBA (сборка компонентов): Выбор "SMT Assembly" при оформлении заказа Загрузить: Gerber + BOM + Pick&Place CSV Компоненты: из их склада (Basic Parts бесплатно; Extended Parts - $3/тип) Нюанс: минимальный заказ PCBA - 2 платы, некоторые компоненты не доступны Типичные ошибки новичков1. Слишком тонкие трэки питания Трэк 0.15 мм, ток 500мА → нагрев, падение напряжения, деградация. 2. Конденсаторы декупплинга далеко от IC Декупплинг работает только при минимальной индуктивности пути. 3. Разрезанный земляной полигон Трэки проходят через полигон, создавая "острова" — петли, помехи. 4. Несоответствие footprint реальному корпусу Проверьте в 3D-просмотре ДО заказа! Footprint 0402 vs 0603 — разные! 5. Нет тестовых точек Как отлаживать плату без точек для щупа? Добавьте testpad на каждый критичный сигнал. 6. Не проверена DRC (Design Rule Check) KiCad/EasyEDA имеют встроенную проверку. Всегда запускайте перед экспортом. ЗаключениеPCB-дизайн — навык, который приходит с практикой. Сделайте свою первую плату, закажите, спаяйте, найдите ошибки, сделайте вторую лучше. Итерационный процесс. KiCad 8 — отличная бесплатная точка входа. Пройдите официальные туториалы на kicandhw.io. Изучите IPC-2221 (Generic Standard on Printed Board Design) — документ объёмный, но содержит ответы на большинство вопросов по правилам разводки. Инвестируйте в понимание физики: как ток возвращается к источнику, что такое импеданс трэка, как работает декупллинг. С этим пониманием большинство решений по разводке становятся очевидными.
PCB-дизайн: мост между схемой и устройствомОтличная схема в плохом PCB-дизайне — это источник помех, нестабильная работа, проблемы с EMC и перегрев. Хороший PCB-дизайн — это такая же инженерная дисциплина, как схемотехника. Современные инструменты доступны бесплатно (KiCad), производство быстрое и дешёвое (JLCPCB, PCBWay, OSHPark — 5 плат за $2 с доставкой за 2 недели). Барьер для входа в PCB-разработку никогда не был ниже. Но количество "тонких мест" не уменьшилось. Сегодня — практика без воды. Инструменты: что выбратьKiCad (бесплатно, открытый исходный код)Версия 7/8 — функционально близка к коммерческим решениям Отличный Schematic Editor и PCB Editor SPICE-симуляция, 3D-просмотр Огромная библиотека компонентов, активное сообщество Рекомендация: для большинства проектов вполне достаточно Altium DesignerПромышленный стандарт в телекоме и аэрокосмосе $8 000+/год лицензия Нельзя просто взять и попробовать CircuitMaker (бесплатная версия Altium) — сильно урезана Eagle (Autodesk)Бесплатно до 2 слоёв и 80 см² Хорошая экосистема библиотек SparkFun/Adafruit Интегрируется с Fusion 360 EasyEDA / LCEDAБраузерный, бесплатный Прямая интеграция с JLCPCB и их библиотекой компонентов Быстрый старт для простых проектов Процесс разработки: от идеи до платы1. Спецификация → 2. Схема → 3. Выбор корпуса → 4. Разводка → 5. DRC/проверки → 6. Генерация Gerber → 7. Заказ → 8. Пайка → 9. Отладка Шаг 1: Схема (Schematic)Правила хорошей схемы: Читается слева направо: сигнал течёт от входа к выходу VCC сверху, GND снизу: стандартная конвенция Все пины обозначены: нет "hanging pins" без назначения Развязочные конденсаторы: рядом с каждой микросхемой на схеме (не просто в угол!) Комментарии: номиналы, допуски, критичные параметры Обязательные компоненты для питания: - Входной конденсатор: электролит 100 мкФ/16В (bulk capacitor) - Bypass конденсатор: керамика 100 нФ X7R рядом с каждым VCC пином IC - Bypass конденсатор: 10 нФ дополнительно для высокочастотных IC - Ferrite bead (если нужна изоляция аналоговой и цифровой земли) Шаг 2: Footprint и 3D-моделиВыбор правильного корпуса компонента критически важен: Проверьте datasheet производителя — landing pattern (рекомендуемый footprint) IPC-7351 — стандарт land pattern для SMD Предпочитайте компоненты из основных серий (0402, 0603, 0805 — легко заказать) Слои PCB: понимание стекаДвухслойная PCB (2-layer):─── Copper Top (компоненты, сигналы) ─── Core (диэлектрик FR4, 1.6 мм) ─── Copper Bottom (земля, сигналы) Дёшево ($2–5 за 10 плат), достаточно для большинства низкочастотных проектов. Четырёхслойная PCB (4-layer):─── Layer 1: Copper Top (сигналы, компоненты) ─── Prepreg (диэлектрик) ─── Layer 2: Ground Plane (сплошная земля!) ─── Core ─── Layer 3: Power Plane (питание) ─── Prepreg ─── Layer 4: Copper Bottom (сигналы) Дороже (~$15–30 за 10 плат), но: Слой земли под каждым сигнальным слоем — контролируемый импеданс Чистое питание (мало помех) Лучшая EMC Обязательна при F > 50 МГц или быстрых фронтах Земляной полигон (Ground Plane): основа всегоЭто самое важное правило PCB-дизайна. Сплошной медный полигон на слое GND: Почему это важно: Низкоиндуктивный путь возврата тока для каждого сигнала Экранирование сигнальных слоёв Тепловая масса для компонентов Референс для импеданса сигналов ПРАВИЛЬНО: земля под каждым сигнальным трэком ─Signal──────────────────────────────── Layer 1 ─────────────────────────────────────── Layer 2 (GND plane) Ток сигнала течёт по трэку, ток возврата — прямо под ним по плоскости (минимальная петля!) НЕПРАВИЛЬНО: нет плоскости, возврат по произвольному пути ─Signal──────────────────────────────── Layer 1 ──────────GND wire──────────────────── Layer 2 Ток возврата ищет произвольный путь → большая петля → EMI! Критические правила полигона:Не разрезайте плоскость без необходимости! ❌ Плохо: прорезь делит плоскость на два острова ───────────────────────────────────────────────── ╔═══════════════════╗ ← Прорезь! ─────────╝ ╚──────────────────── Ток возврата вынужден огибать прорезь → большая петля → EMI ✅ Хорошо: полигон цельный ───────────────────────────────────────────────────────────── (никаких прорезей без веской причины) ───────────────────────────────────────────────────────────── Via stitching — соединение полигонов между слоями: Размещайте заземляющие виа равномерно по всей плате (через каждые 1–2 см). Это снижает индуктивность плоскости. Импеданс трэков: для высокоскоростных сигналовПри частоте выше ~100 МГц или временах нарастания фронта <2нс — трэки нужно рассматривать как длинные линии. Импеданс трэка должен совпадать с импедансом источника и нагрузки (обычно 50 Ом для одиночного трэка или 100 Ом для дифференциальной пары). Формула для микрополосковой линии (Microstrip):Трэк на поверхностном слое над плоскостью земли: Z0 ≈ (87 / √(εr + 1.41)) × ln(5.98 × h / (0.8 × w + t)) Где: εr = диэлектрическая проницаемость (FR4: 4.2–4.5) h = расстояние от трэка до плоскости, мкм w = ширина трэка, мкм t = толщина меди, мкм (стандарт 1oz = 35 мкм) Для FR4, 4-слойная плата, h=200 мкм: 50 Ом → w ≈ 450 мкм (0.45 мм) 75 Ом → w ≈ 200 мкм (0.20 мм) Практически: используйте онлайн-калькуляторы (Saturn PCB Toolkit, Polar Si9000) или параметр stackup от производителя платы (JLCPCB публикует точные параметры своего FR4). Дифференциальные парыUSB, LVDS, HDMI, Ethernet, SerDes — все используют дифференциальные пары. Правила трассировки: Правила дифференциальных пар: 1. Одинаковая длина обоих трэков (skew < 5 мил/пс сигнала) 2. Одинаковое расстояние между трэками по всей длине (coupling) 3. Расстояние между трэками пары: 2-3 толщины диэлектрика 4. Без прямых углов (45° или радиусы) 5. Пересечение плоскости GND: только перпендикулярно, не вдоль щели USB FS (12 Мбит/с): Z_diff = 90 Ом, зазор 150 мкм USB HS (480 Мбит/с): Z_diff = 90 Ом, контроль длины ±0.1 мм Ethernet 100M: Z_diff = 100 Ом через трансформатор LVDS: Z_diff = 100 Ом Декупплинг конденсаторы: где и какиеСтратегия декупплинга (от источника питания к IC): [Источник] → [100 мкФ electrolytic] → [10 мкФ MLCC] → [100 нФ MLCC] → [IC] (bulk, далеко) (medium, ближе) (bypass, вплотную) Расположение на плате: ┌────────────────────────────────────┐ │ ┌──────┐ │ │ │ IC │ ← 100нФ вплотную к VCC пину │ └──────┘ ← 10нФ рядом │ ... │ │ [100мкФ] │ └────────────────────────────────────┘ Расстояние: - 100 нФ: ≤ 1 мм от VCC пина IC - 10 нФ: ≤ 3 мм - 100 мкФ: ≤ 10 мм НЕПРАВИЛЬНО: конденсатор в угол платы далеко от IC Эффективность падает экспоненциально с расстоянием! Выбор диэлектрика конденсатора:Диэлектрик Применение Зависимость от V/T X7R Bypass, фильтры (100 пФ – 10 мкФ) Умеренная X5R Bulk bypass (1 мкФ – 47 мкФ) Значительная при V C0G/NP0 Точные цепи, LC-фильтры Минимальная Y5V Не использовать в серьёзных проектах Огромная (-80%!) Важно: MLCC конденсатор 10 мкФ X5R 6.3В при напряжении 5В теряет 60% ёмкости из-за DC bias! Проверяйте даташит. Тепловой дизайн на PCBТепловое сопротивление медной области: R_th = L / (λ × A) = L / (380 Вт/(м·К) × ширина × толщина) Для FR4 (плохой теплопроводник, λ=0.3 Вт/(м·К)): Тепло течёт ПО МЕДИ, не через диэлектрик! Рекомендации: 1. Thermal vias под горячими компонентами: ┌──────────────────────────┐ │ IC (рассеивает 2 Вт) │ │ ●●●●●●●●●●●●●●●●●●● │ ← via array к Cu plane └──────────────────────────┘ Диаметр via: 0.3 мм, шаг: 0.8–1.0 мм 2. Copper pour (медный полигон) рядом с горячим компонентом 3. Radiator pad: обнажённая медь сверху для конвекции Расчёт температуры: T_junction = T_ambient + P × (R_th_jc + R_th_board + R_th_air) ↑ Это то, на что влияет PCB-дизайн EMC: электромагнитная совместимостьПлохой PCB-дизайн — главная причина проблем с EMC-сертификацией. Три правила EMC для PCB:1. Минимизировать площадь токовых петель: Высокочастотный ток протекает: Source → трэк → нагрузка → возврат по плоскости GND (под трэком) Площадь петли = длина трэка × расстояние до плоскости Уменьшить расстояние = 4-слойка со сплошной GND плоскостью 2. Разделить аналоговую и цифровую землю правильно: Популярный МИФ: "нужно разделить AGND и DGND полностью" РЕАЛЬНОСТЬ: один сплошной полигон GND, аналоговые компоненты в одном углу, цифровые в другом. Соединяйте земли в ОДНОЙ точке под ADC/DAC. Разрезать полигон почти никогда не нужно и часто вредно! 3. Развязка питания IC: Уже разобрали выше — 100нФ вплотную к каждому VCC пину. Дополнительные меры EMC:Ferrite bead в линии питания шумных цифровых блоков Common-mode фильтры на интерфейсных линиях Guard ring (защитное кольцо) вокруг аналоговых блоков Минимизировать длину высокочастотных трэков Правила трассировки: шпаргалкаШирина трэков: - Питание (до 1А): 0.5 мм - Питание (до 2А): 1.0 мм - Питание (до 5А): 2.5 мм - Сигналы: 0.15–0.25 мм (минимум производства: обычно 0.1 мм) Зазоры: - Сигнал-сигнал: ≥ 0.15 мм (производственный минимум) - 100В AC: ≥ 1 мм (по воздуху), 2 мм (по поверхности) - 250В AC: ≥ 2 мм / 4 мм Переходные отверстия (via): - Стандарт: диаметр 0.6 мм (отверстие 0.3 мм) - Micro via: 0.2 мм — дорого, только если необходимо - Технологические отверстия (крепёжные): нет меди, 3.2 мм (под M3) Углы трэков: ✅ 45° (стандарт) ✅ Радиусы (лучше для высоких частот) ❌ 90° прямые углы (устарелая проблема, но лучше избегать) Подготовка к производству: Gerber файлыНабор файлов для производства: Gerber файлы: .GTL - Top Copper (верхний слой меди) .GBL - Bottom Copper .GTS - Top Solder Mask (маска верхнего слоя) .GBS - Bottom Solder Mask .GTO - Top Silkscreen (маркировка) .GBO - Bottom Silkscreen .GKO - Board Outline (контур платы) .GM1..N - Inner layers (внутренние слои, если есть) Drill файл: .DRL или .XLN - координаты и размеры отверстий BOM (Bill of Materials): .CSV - список компонентов с номиналами, производителем, part number Pick and Place: .CSV - координаты и ориентация SMD компонентов (для PCBA) JLCPCB: заказ платы и PCBA-сборкиJLCPCB — наиболее популярный среди разработчиков производитель: Параметры стандартного заказа: Количество: 5 штук Слои: 2 Размер: ≤ 100×100 мм Цена: $2 + доставка Срок: 2 дня производство + 1-2 недели доставка PCBA (сборка компонентов): Выбор "SMT Assembly" при оформлении заказа Загрузить: Gerber + BOM + Pick&Place CSV Компоненты: из их склада (Basic Parts бесплатно; Extended Parts - $3/тип) Нюанс: минимальный заказ PCBA - 2 платы, некоторые компоненты не доступны Типичные ошибки новичков1. Слишком тонкие трэки питания Трэк 0.15 мм, ток 500мА → нагрев, падение напряжения, деградация. 2. Конденсаторы декупплинга далеко от IC Декупплинг работает только при минимальной индуктивности пути. 3. Разрезанный земляной полигон Трэки проходят через полигон, создавая "острова" — петли, помехи. 4. Несоответствие footprint реальному корпусу Проверьте в 3D-просмотре ДО заказа! Footprint 0402 vs 0603 — разные! 5. Нет тестовых точек Как отлаживать плату без точек для щупа? Добавьте testpad на каждый критичный сигнал. 6. Не проверена DRC (Design Rule Check) KiCad/EasyEDA имеют встроенную проверку. Всегда запускайте перед экспортом. ЗаключениеPCB-дизайн — навык, который приходит с практикой. Сделайте свою первую плату, закажите, спаяйте, найдите ошибки, сделайте вторую лучше. Итерационный процесс. KiCad 8 — отличная бесплатная точка входа. Пройдите официальные туториалы на kicandhw.io. Изучите IPC-2221 (Generic Standard on Printed Board Design) — документ объёмный, но содержит ответы на большинство вопросов по правилам разводки. Инвестируйте в понимание физики: как ток возвращается к источнику, что такое импеданс трэка, как работает декупллинг. С этим пониманием большинство решений по разводке становятся очевидными. -
 ESP32: почему он стал стандартом IoTESP32 от Espressif Systems вышел в 2016 году и быстро стал самым популярным Wi-Fi/BT чипом для IoT. Причины: 240 МГц Xtensa LX6 (два ядра!) — серьёзная вычислительная мощь Wi-Fi 802.11 b/g/n + Bluetooth 4.2/BLE — встроено в один чип 520 КБ SRAM + внешняя Flash — достаточно для реальных приложений Богатая периферия: 18 каналов ADC, 2 DAC, 3 UART, 2 SPI, 2 I2C, I2S, CAN, Touch, Hall Цена $2–5 (модуль ESP32-WROOM-32) FreeRTOS в основе SDK — готовая RTOS "из коробки" Семейство ESP32 сегодня: ESP32 — оригинал, Xtensa LX6 240 МГц, Wi-Fi + BT Classic + BLE ESP32-S2 — одно ядро, USB OTG, нет BT, дешевле ESP32-S3 — два ядра, USB OTG, AI-расширения (ML) ESP32-C3 — RISC-V одно ядро, Wi-Fi + BLE, ультрадешёвый (~$1) ESP32-C6 — RISC-V, Wi-Fi 6, BLE 5, Thread/Zigbee (Matter) ESP32-H2 — только BLE 5 + Thread (802.15.4), без Wi-Fi Архитектура: два ядра и их назначениеESP32 имеет два ядра Xtensa LX6 с именами PRO_CPU (ядро 0) и APP_CPU (ядро 1): PRO_CPU (Protocol CPU, Core 0): - Wi-Fi/Bluetooth стек (работает здесь) - Системные задачи FreeRTOS - Обработка прерываний от периферии APP_CPU (Application CPU, Core 1): - Ваш прикладной код - Бизнес-логика - Задачи реального времени приложения При использовании Arduino framework — код в loop() выполняется на APP_CPU. В ESP-IDF — вы явно указываете ядро при создании задачи: // ESP-IDF: создание задач с привязкой к ядру void wifi_task(void *pvParam) { // Эта задача работает на PRO_CPU — ближе к WiFi-стеку while (1) { // Сетевые операции vTaskDelay(pdMS_TO_TICKS(100)); } } void sensor_task(void *pvParam) { // Эта задача на APP_CPU — изолирована от WiFi-шумов while (1) { float adc_val = read_adc(); run_pid(adc_val); vTaskDelay(pdMS_TO_TICKS(10)); } } void app_main(void) { // PRO_CPU (Core 0) — WiFi, сетевые задачи xTaskCreatePinnedToCore(wifi_task, "WiFi", 4096, NULL, 5, NULL, 0); // APP_CPU (Core 1) — приложение xTaskCreatePinnedToCore(sensor_task, "Sensor", 4096, NULL, 4, NULL, 1); } Важно: WiFi-стек использует PRO_CPU интенсивно во время передачи. Задачи реального времени лучше держать на APP_CPU чтобы WiFi не вызывал джиттер. WiFi: три режима работыStation Mode (STA) — подключение к роутеру// Arduino framework #include <WiFi.h> const char* SSID = "MyNetwork"; const char* PASSWORD = "MyPassword"; void wifi_connect() { WiFi.mode(WIFI_STA); WiFi.begin(SSID, PASSWORD); // Статический IP (не DHCP) — обязательно для production! IPAddress local_ip(192, 168, 1, 200); IPAddress gateway(192, 168, 1, 1); IPAddress subnet(255, 255, 255, 0); IPAddress dns1(192, 168, 1, 1); WiFi.config(local_ip, gateway, subnet, dns1); Serial.print("Подключение к WiFi"); uint32_t timeout = millis() + 30000; // 30 секунд таймаут while (WiFi.status() != WL_CONNECTED) { if (millis() > timeout) { Serial.println("\nОшибка подключения! Перезагрузка..."); ESP.restart(); } delay(500); Serial.print("."); } Serial.printf("\nПодключено! IP: %s, RSSI: %d dBm\n", WiFi.localIP().toString().c_str(), WiFi.RSSI()); } // Мониторинг соединения в loop(): void check_wifi_reconnect() { static uint32_t lastCheck = 0; if (millis() - lastCheck < 5000) return; lastCheck = millis(); if (WiFi.status() != WL_CONNECTED) { Serial.println("WiFi потерян, переподключение..."); WiFi.disconnect(); WiFi.begin(SSID, PASSWORD); } } Access Point Mode (AP) — ESP32 как точка доступаvoid start_access_point() { WiFi.mode(WIFI_AP); // SSID, пароль, канал, скрытый?, макс клиентов WiFi.softAP("ESP32-Config", "setup12345", 6, false, 4); // Настройка IP точки доступа IPAddress ap_ip(192, 168, 4, 1); IPAddress ap_netmask(255, 255, 255, 0); WiFi.softAPConfig(ap_ip, ap_ip, ap_netmask); Serial.printf("AP запущен: %s, IP: %s\n", WiFi.softAPSSID().c_str(), WiFi.softAPIP().toString().c_str()); } STA+AP (одновременно!) — для конфигурации устройстваvoid start_sta_ap_mode() { WiFi.mode(WIFI_AP_STA); // AP для настройки (пока устройство не настроено) WiFi.softAP("ESP32-Setup"); // STA для рабочего подключения if (has_credentials()) { WiFi.begin(saved_ssid, saved_password); } } BLE: Bluetooth Low Energy в деталяхBLE в ESP32 реализован через NimBLE (более лёгкий стек, рекомендуется) или Bluedroid. GATT Server — ESP32 как BLE периферия#include <NimBLEDevice.h> // UUID сервисов и характеристик (генерируйте свои на uuidgenerator.net) #define SERVICE_UUID "4fafc201-1fb5-459e-8fcc-c5c9c331914b" #define TEMPERATURE_UUID "beb5483e-36e1-4688-b7f5-ea07361b26a8" #define CONTROL_UUID "beb5483e-36e1-4688-b7f5-ea07361b26a9" NimBLEServer* pServer = nullptr; NimBLECharacteristic* pTempChar = nullptr; NimBLECharacteristic* pCtrlChar = nullptr; bool deviceConnected = false; // Callbacks для событий подключения class ServerCallbacks : public NimBLEServerCallbacks { void onConnect(NimBLEServer* pServer, ble_gap_conn_desc* desc) override { deviceConnected = true; Serial.printf("BLE: клиент подключён, addr: %s\n", NimBLEAddress(desc->peer_ota_addr).toString().c_str()); // Обновляем параметры соединения для лучшей производительности pServer->updateConnParams(desc->conn_handle, 6, 6, 0, 100); } void onDisconnect(NimBLEServer* pServer) override { deviceConnected = false; Serial.println("BLE: клиент отключился"); // Перезапускаем рекламу NimBLEDevice::startAdvertising(); } }; // Callbacks для записи характеристики управления class ControlCallbacks : public NimBLECharacteristicCallbacks { void onWrite(NimBLECharacteristic* pChar) override { std::string value = pChar->getValue(); if (value.length() > 0) { uint8_t command = value[0]; Serial.printf("BLE: команда получена: 0x%02X\n", command); switch (command) { case 0x01: relay_on(); break; case 0x00: relay_off(); break; } } } }; void ble_init() { NimBLEDevice::init("ESP32-Sensor"); NimBLEDevice::setMTU(185); // Увеличиваем MTU для больших пакетов pServer = NimBLEDevice::createServer(); pServer->setCallbacks(new ServerCallbacks()); // Создаём сервис NimBLEService* pService = pServer->createService(SERVICE_UUID); // Характеристика температуры (только чтение + уведомления) pTempChar = pService->createCharacteristic( TEMPERATURE_UUID, NIMBLE_PROPERTY::READ | NIMBLE_PROPERTY::NOTIFY ); pTempChar->setValue(0.0f); // Характеристика управления (запись) pCtrlChar = pService->createCharacteristic( CONTROL_UUID, NIMBLE_PROPERTY::WRITE | NIMBLE_PROPERTY::WRITE_NR // NR = No Response (быстрее) ); pCtrlChar->setCallbacks(new ControlCallbacks()); pService->start(); // Настройка рекламы NimBLEAdvertising* pAdv = NimBLEDevice::getAdvertising(); pAdv->addServiceUUID(SERVICE_UUID); pAdv->setScanResponse(true); pAdv->setMinPreferred(0x06); pAdv->start(); Serial.println("BLE запущен, ожидаем подключения..."); } // Обновление данных температуры (вызывать периодически) void ble_update_temperature(float temperature) { if (!deviceConnected) return; // Отправляем float как 4 байта uint8_t data[4]; memcpy(data, &temperature, 4); pTempChar->setValue(data, 4); pTempChar->notify(); // Push уведомление подключённому клиенту } NVS: хранение настроек во FlashNVS (Non-Volatile Storage) — key-value хранилище в Flash памяти ESP32. Пережи вает перезагрузки и обновления прошивки: #include <Preferences.h> // Arduino framework Preferences prefs; struct DeviceConfig { char mqtt_host[64]; uint16_t mqtt_port; char device_id[32]; float setpoint; bool auto_mode; }; DeviceConfig config; void config_load_defaults() { strlcpy(config.mqtt_host, "192.168.1.100", sizeof(config.mqtt_host)); config.mqtt_port = 1883; strlcpy(config.device_id, "esp32_001", sizeof(config.device_id)); config.setpoint = 25.0f; config.auto_mode = true; } bool config_load() { prefs.begin("config", true); // true = read-only if (!prefs.isKey("mqtt_host")) { prefs.end(); return false; // Первый запуск — нет сохранённых настроек } prefs.getString("mqtt_host", config.mqtt_host, sizeof(config.mqtt_host)); config.mqtt_port = prefs.getUShort("mqtt_port", 1883); prefs.getString("device_id", config.device_id, sizeof(config.device_id)); config.setpoint = prefs.getFloat("setpoint", 25.0f); config.auto_mode = prefs.getBool("auto_mode", true); prefs.end(); return true; } void config_save() { prefs.begin("config", false); // false = read-write prefs.putString("mqtt_host", config.mqtt_host); prefs.putUShort("mqtt_port", config.mqtt_port); prefs.putString("device_id", config.device_id); prefs.putFloat("setpoint", config.setpoint); prefs.putBool("auto_mode", config.auto_mode); prefs.end(); Serial.println("Конфигурация сохранена в NVS"); } void config_reset() { prefs.begin("config", false); prefs.clear(); prefs.end(); Serial.println("NVS очищен, перезагрузка..."); ESP.restart(); } // Использование: void setup() { if (!config_load()) { Serial.println("Первый запуск, загружаем дефолты"); config_load_defaults(); config_save(); } Serial.printf("MQTT: %s:%d\n", config.mqtt_host, config.mqtt_port); } OTA: обновление прошивки по воздухуESP32: глубокое погружение#include <ArduinoOTA.h> #include <Update.h> // ===== ПРОСТОЕ OTA ЧЕРЕЗ Arduino IDE ===== void ota_init_arduino() { ArduinoOTA.setHostname("esp32-gateway-001"); ArduinoOTA.setPassword("ota_secret_password"); ArduinoOTA.onStart([]() { String type = ArduinoOTA.getCommand() == U_FLASH ? "прошивку" : "файловую систему"; Serial.printf("OTA: начало обновления %s\n", type.c_str()); // Останавливаем критичные задачи перед обновлением mqtt_stop(); modbus_stop(); }); ArduinoOTA.onEnd([]() { Serial.println("OTA: обновление завершено, перезагрузка..."); }); ArduinoOTA.onProgress([](unsigned int progress, unsigned int total) { static uint8_t last_pct = 0; uint8_t pct = progress * 100 / total; if (pct != last_pct && pct % 10 == 0) { Serial.printf("OTA: %u%%\n", pct); last_pct = pct; } }); ArduinoOTA.onError([](ota_error_t error) { const char* errors[] = {"Auth Failed", "Begin Failed", "Connect Failed", "Receive Failed", "End Failed"}; Serial.printf("OTA Ошибка[%u]: %s\n", error, error <= 4 ? errors[error] : "Unknown"); }); ArduinoOTA.begin(); } // В loop() добавить: // ArduinoOTA.handle(); // ===== HTTP OTA: скачивание прошивки с сервера ===== #include <HTTPUpdate.h> #include <WiFiClientSecure.h> void ota_update_from_server(const char* server_url) { Serial.printf("OTA: загрузка с %s\n", server_url); WiFiClient client; // Или WiFiClientSecure для HTTPS (настройте сертификат!) httpUpdate.setLedPin(LED_BUILTIN, LOW); // Callback прогресса httpUpdate.onProgress([](int current, int total) { Serial.printf("OTA: %d/%d bytes (%d%%)\n", current, total, current * 100 / total); }); t_httpUpdate_return ret = httpUpdate.update(client, server_url); switch (ret) { case HTTP_UPDATE_FAILED: Serial.printf("OTA ошибка (%d): %s\n", httpUpdate.getLastError(), httpUpdate.getLastErrorString().c_str()); break; case HTTP_UPDATE_NO_UPDATES: Serial.println("OTA: нет обновлений"); break; case HTTP_UPDATE_OK: Serial.println("OTA: успех, перезагрузка..."); break; } } // Проверка обновлений по расписанию: void check_for_updates() { static uint32_t lastCheck = 0; const uint32_t CHECK_INTERVAL = 3600000UL; // 1 час if (millis() - lastCheck < CHECK_INTERVAL) return; lastCheck = millis(); // Проверяем версию на сервере String server_version = http_get_json("/api/firmware/version")["version"]; if (server_version != FIRMWARE_VERSION) { Serial.printf("Доступна новая версия: %s (текущая: %s)\n", server_version.c_str(), FIRMWARE_VERSION); ota_update_from_server("http://server/firmware/latest.bin"); } } Deep Sleep: энергосбережениеESP32 в active mode потребляет ~80–240 мА. В deep sleep — 10 мкА! #include <esp_sleep.h> #include <esp_wifi.h> // Типы пробуждения: // - Таймер (RTC таймер) // - GPIO (кнопка, сигнал) // - Touch (сенсорные входы) // - ULP (Ultra-Low Power co-processor) // - UART (RXD0) // - BT (в режиме light sleep) void go_to_deep_sleep(uint32_t sleep_seconds) { Serial.printf("Уходим в сон на %u секунд...\n", sleep_seconds); Serial.flush(); // Закрываем WiFi перед сном (экономит время пробуждения) WiFi.disconnect(true); WiFi.mode(WIFI_OFF); // Настраиваем пробуждение по таймеру esp_sleep_enable_timer_wakeup((uint64_t)sleep_seconds * 1000000ULL); // Пробуждение от GPIO4 (нажатие кнопки) esp_sleep_enable_ext0_wakeup(GPIO_NUM_4, 0); // 0 = LOW уровень // Входим в deep sleep esp_deep_sleep_start(); // Код после этой строки не выполнится! } void setup() { Serial.begin(115200); // Определяем причину пробуждения esp_sleep_wakeup_cause_t cause = esp_sleep_get_wakeup_cause(); switch (cause) { case ESP_SLEEP_WAKEUP_TIMER: Serial.println("Пробуждение: таймер"); send_sensor_data(); // Отправляем данные и снова в сон break; case ESP_SLEEP_WAKEUP_EXT0: Serial.println("Пробуждение: кнопка"); // Пользователь нажал кнопку — полная работа full_operation_mode(); return; case ESP_SLEEP_WAKEUP_UNDEFINED: Serial.println("Первый запуск или reset"); first_boot_setup(); break; default: Serial.printf("Причина: %d\n", cause); } // Снова в сон через 60 секунд go_to_deep_sleep(60); } // RTC Memory: данные переживают deep sleep! RTC_DATA_ATTR int boot_count = 0; RTC_DATA_ATTR float last_temperature = 0.0f; RTC_DATA_ATTR uint32_t error_count = 0; void setup_with_rtc_memory() { boot_count++; Serial.printf("Загрузка #%d, последняя T=%.1f°C\n", boot_count, last_temperature); // Читаем датчик, сохраняем в RTC memory last_temperature = read_temperature(); go_to_deep_sleep(300); // 5 минут } ADC: правильная работа с АЦПАЦП ESP32 имеет репутацию "неточного". Это правда — и вот почему и как с этим работать: #include <esp_adc/adc_oneshot.h> #include <esp_adc/adc_cali.h> #include <esp_adc/adc_cali_scheme.h> // Калиброванный ADC на ESP-IDF (точность ±5мВ вместо ±50мВ) adc_oneshot_unit_handle_t adc1_handle; adc_cali_handle_t cali_handle; void adc_init_calibrated() { // Инициализация ADC adc_oneshot_unit_init_cfg_t init_config = { .unit_id = ADC_UNIT_1, .ulp_mode = ADC_ULP_MODE_DISABLE, }; ESP_ERROR_CHECK(adc_oneshot_new_unit(&init_config, &adc1_handle)); // Настройка канала (GPIO34 = ADC1 Channel 6) adc_oneshot_chan_cfg_t chan_config = { .bitwidth = ADC_BITWIDTH_12, .atten = ADC_ATTEN_DB_12, // 0-3.3В диапазон }; ESP_ERROR_CHECK(adc_oneshot_config_channel(adc1_handle, ADC_CHANNEL_6, &chan_config)); // Калибровка (Line Fitting или Curve Fitting) adc_cali_line_fitting_config_t cali_config = { .unit_id = ADC_UNIT_1, .atten = ADC_ATTEN_DB_12, .bitwidth = ADC_BITWIDTH_12, }; ESP_ERROR_CHECK(adc_cali_create_scheme_line_fitting(&cali_config, &cali_handle)); } float adc_read_voltage_mv() { int raw; ESP_ERROR_CHECK(adc_oneshot_read(adc1_handle, ADC_CHANNEL_6, &raw)); int voltage_mv; ESP_ERROR_CHECK(adc_cali_raw_to_voltage(cali_handle, raw, &voltage_mv)); return (float)voltage_mv; } // Oversampling для повышения точности (16x → +2 бита) float adc_read_averaged(int samples = 64) { int64_t sum = 0; for (int i = 0; i < samples; i++) { int raw; adc_oneshot_read(adc1_handle, ADC_CHANNEL_6, &raw); sum += raw; delayMicroseconds(100); } int avg_raw = sum / samples; int voltage_mv; adc_cali_raw_to_voltage(cali_handle, avg_raw, &voltage_mv); return (float)voltage_mv; } // Важные ограничения ADC ESP32: // - GPIO36, 37, 38, 39: только вход, без pullup/pulldown в кристалле // - ADC2 нельзя использовать одновременно с WiFi! // - Нелинейность вблизи 0В и 3.3В — оставайтесь в диапазоне 100мВ..3.1В // - Для точных измерений: внешний АЦП MCP3208 по SPI Практический проект: промышленный IoT узел// Полная архитектура ESP32 IoT узла #include <Arduino.h> #include <WiFi.h> #include <PubSubClient.h> #include <ArduinoJson.h> #include <Preferences.h> // ===== КОНФИГУРАЦИЯ ===== #define FIRMWARE_VERSION "1.2.3" #define DEVICE_MODEL "ESP32-IoT-Node" #define PUBLISH_INTERVAL_MS 5000 #define WATCHDOG_TIMEOUT_MS 30000 // ===== ГЛОБАЛЬНОЕ СОСТОЯНИЕ ===== struct State { bool wifi_connected = false; bool mqtt_connected = false; float temperature = 0; float humidity = 0; float pressure = 0; uint32_t uptime_sec = 0; uint32_t publish_count = 0; uint32_t error_count = 0; }; State state; WiFiClient wifiClient; PubSubClient mqtt(wifiClient); // ===== МНОГОЗАДАЧНОСТЬ ===== QueueHandle_t sensorQueue; SemaphoreHandle_t stateMutex; // Задача: чтение датчиков (Core 1) void task_sensors(void *pv) { for (;;) { // Здесь: читаем датчики float t = 25.0 + random(-10, 10) / 10.0; // Имитация float h = 50.0 + random(-5, 5) / 10.0; // Обновляем состояние через мьютекс xSemaphoreTake(stateMutex, portMAX_DELAY); state.temperature = t; state.humidity = h; xSemaphoreGive(stateMutex); vTaskDelay(pdMS_TO_TICKS(1000)); } } // Задача: MQTT публикация (Core 0, рядом с WiFi) void task_mqtt(void *pv) { for (;;) { if (!mqtt.connected()) { if (WiFi.isConnected()) { if (mqtt.connect("esp32-node", "user", "pass", "nodes/esp32-001/status", 1, true, "{\"online\":false}")) { mqtt.publish("nodes/esp32-001/status", "{\"online\":true}", true); mqtt.subscribe("nodes/esp32-001/commands"); } } } mqtt.loop(); // Публикация данных static uint32_t lastPublish = 0; if (millis() - lastPublish >= PUBLISH_INTERVAL_MS) { lastPublish = millis(); StaticJsonDocument<256> doc; xSemaphoreTake(stateMutex, portMAX_DELAY); doc["temperature"] = state.temperature; doc["humidity"] = state.humidity; doc["uptime"] = state.uptime_sec; doc["errors"] = state.error_count; doc["version"] = FIRMWARE_VERSION; doc["rssi"] = WiFi.RSSI(); doc["free_heap"] = ESP.getFreeHeap(); xSemaphoreGive(stateMutex); char payload[256]; serializeJson(doc, payload); mqtt.publish("nodes/esp32-001/telemetry", payload); state.publish_count++; } vTaskDelay(pdMS_TO_TICKS(10)); } } // Задача: watchdog и uptime (Core 1) void task_system(void *pv) { for (;;) { state.uptime_sec++; // Проверка heap (memory leak detection) if (ESP.getFreeHeap() < 10000) { Serial.println("КРИТИЧНО: мало памяти! Перезагрузка..."); ESP.restart(); } // Heartbeat LED digitalWrite(LED_BUILTIN, !digitalRead(LED_BUILTIN)); vTaskDelay(pdMS_TO_TICKS(1000)); } } void setup() { Serial.begin(115200); Serial.printf("\nESP32 IoT Node v%s\n", FIRMWARE_VERSION); Serial.printf("Chip: %s, Rev: %d, Cores: %d\n", ESP.getChipModel(), ESP.getChipRevision(), ESP.getChipCores()); // Инициализация stateMutex = xSemaphoreCreateMutex(); sensorQueue = xQueueCreate(10, sizeof(float)); // WiFi WiFi.mode(WIFI_STA); WiFi.begin("SSID", "PASSWORD"); // MQTT mqtt.setServer("192.168.1.100", 1883); mqtt.setBufferSize(1024); // Запускаем задачи на разных ядрах xTaskCreatePinnedToCore(task_sensors, "Sensors", 4096, NULL, 3, NULL, 1); xTaskCreatePinnedToCore(task_mqtt, "MQTT", 8192, NULL, 4, NULL, 0); xTaskCreatePinnedToCore(task_system, "System", 2048, NULL, 1, NULL, 1); Serial.println("Задачи запущены"); } void loop() { // loop() работает на Core 1 с низким приоритетом // Можно использовать для некритичных задач или оставить пустым vTaskDelay(pdMS_TO_TICKS(1000)); } Выбор инструментария: Arduino vs ESP-IDFКритерий Arduino Framework ESP-IDF (native) Порог входа Низкий Высокий Документация Обширная, много примеров Официальная, полная Производительность Достаточная Максимальная Доступ к периферии Через библиотеки Прямой Размер бинарника Больше Меньше RTOS Доступен (FreeRTOS через задачи) Нативный Время разработки Быстрее Медленнее Production-ready Да (если делать правильно) Да Рекомендация Прототипы, несложные задачи Серийное производство ЗаключениеESP32 — один из лучших выборов для промышленных IoT-узлов с умеренными требованиями к реальному времени. Двухъядерность позволяет изолировать WiFi-стек от прикладного кода, богатая периферия закрывает большинство интерфейсных задач, встроенный FreeRTOS — для многозадачности. Ключевые принципы надёжного ESP32-устройства: статический IP вместо DHCP, watchdog timer, NVS для конфигурации, OTA для обновлений, RTC memory для данных через sleep, мониторинг heap и перезагрузка при критичном уровне. ESP32 — это не замена промышленному ПЛК. Но как edge-узел сбора данных, шлюз протоколов или умный датчик — идеальный выбор.
ESP32: почему он стал стандартом IoTESP32 от Espressif Systems вышел в 2016 году и быстро стал самым популярным Wi-Fi/BT чипом для IoT. Причины: 240 МГц Xtensa LX6 (два ядра!) — серьёзная вычислительная мощь Wi-Fi 802.11 b/g/n + Bluetooth 4.2/BLE — встроено в один чип 520 КБ SRAM + внешняя Flash — достаточно для реальных приложений Богатая периферия: 18 каналов ADC, 2 DAC, 3 UART, 2 SPI, 2 I2C, I2S, CAN, Touch, Hall Цена $2–5 (модуль ESP32-WROOM-32) FreeRTOS в основе SDK — готовая RTOS "из коробки" Семейство ESP32 сегодня: ESP32 — оригинал, Xtensa LX6 240 МГц, Wi-Fi + BT Classic + BLE ESP32-S2 — одно ядро, USB OTG, нет BT, дешевле ESP32-S3 — два ядра, USB OTG, AI-расширения (ML) ESP32-C3 — RISC-V одно ядро, Wi-Fi + BLE, ультрадешёвый (~$1) ESP32-C6 — RISC-V, Wi-Fi 6, BLE 5, Thread/Zigbee (Matter) ESP32-H2 — только BLE 5 + Thread (802.15.4), без Wi-Fi Архитектура: два ядра и их назначениеESP32 имеет два ядра Xtensa LX6 с именами PRO_CPU (ядро 0) и APP_CPU (ядро 1): PRO_CPU (Protocol CPU, Core 0): - Wi-Fi/Bluetooth стек (работает здесь) - Системные задачи FreeRTOS - Обработка прерываний от периферии APP_CPU (Application CPU, Core 1): - Ваш прикладной код - Бизнес-логика - Задачи реального времени приложения При использовании Arduino framework — код в loop() выполняется на APP_CPU. В ESP-IDF — вы явно указываете ядро при создании задачи: // ESP-IDF: создание задач с привязкой к ядру void wifi_task(void *pvParam) { // Эта задача работает на PRO_CPU — ближе к WiFi-стеку while (1) { // Сетевые операции vTaskDelay(pdMS_TO_TICKS(100)); } } void sensor_task(void *pvParam) { // Эта задача на APP_CPU — изолирована от WiFi-шумов while (1) { float adc_val = read_adc(); run_pid(adc_val); vTaskDelay(pdMS_TO_TICKS(10)); } } void app_main(void) { // PRO_CPU (Core 0) — WiFi, сетевые задачи xTaskCreatePinnedToCore(wifi_task, "WiFi", 4096, NULL, 5, NULL, 0); // APP_CPU (Core 1) — приложение xTaskCreatePinnedToCore(sensor_task, "Sensor", 4096, NULL, 4, NULL, 1); } Важно: WiFi-стек использует PRO_CPU интенсивно во время передачи. Задачи реального времени лучше держать на APP_CPU чтобы WiFi не вызывал джиттер. WiFi: три режима работыStation Mode (STA) — подключение к роутеру// Arduino framework #include <WiFi.h> const char* SSID = "MyNetwork"; const char* PASSWORD = "MyPassword"; void wifi_connect() { WiFi.mode(WIFI_STA); WiFi.begin(SSID, PASSWORD); // Статический IP (не DHCP) — обязательно для production! IPAddress local_ip(192, 168, 1, 200); IPAddress gateway(192, 168, 1, 1); IPAddress subnet(255, 255, 255, 0); IPAddress dns1(192, 168, 1, 1); WiFi.config(local_ip, gateway, subnet, dns1); Serial.print("Подключение к WiFi"); uint32_t timeout = millis() + 30000; // 30 секунд таймаут while (WiFi.status() != WL_CONNECTED) { if (millis() > timeout) { Serial.println("\nОшибка подключения! Перезагрузка..."); ESP.restart(); } delay(500); Serial.print("."); } Serial.printf("\nПодключено! IP: %s, RSSI: %d dBm\n", WiFi.localIP().toString().c_str(), WiFi.RSSI()); } // Мониторинг соединения в loop(): void check_wifi_reconnect() { static uint32_t lastCheck = 0; if (millis() - lastCheck < 5000) return; lastCheck = millis(); if (WiFi.status() != WL_CONNECTED) { Serial.println("WiFi потерян, переподключение..."); WiFi.disconnect(); WiFi.begin(SSID, PASSWORD); } } Access Point Mode (AP) — ESP32 как точка доступаvoid start_access_point() { WiFi.mode(WIFI_AP); // SSID, пароль, канал, скрытый?, макс клиентов WiFi.softAP("ESP32-Config", "setup12345", 6, false, 4); // Настройка IP точки доступа IPAddress ap_ip(192, 168, 4, 1); IPAddress ap_netmask(255, 255, 255, 0); WiFi.softAPConfig(ap_ip, ap_ip, ap_netmask); Serial.printf("AP запущен: %s, IP: %s\n", WiFi.softAPSSID().c_str(), WiFi.softAPIP().toString().c_str()); } STA+AP (одновременно!) — для конфигурации устройстваvoid start_sta_ap_mode() { WiFi.mode(WIFI_AP_STA); // AP для настройки (пока устройство не настроено) WiFi.softAP("ESP32-Setup"); // STA для рабочего подключения if (has_credentials()) { WiFi.begin(saved_ssid, saved_password); } } BLE: Bluetooth Low Energy в деталяхBLE в ESP32 реализован через NimBLE (более лёгкий стек, рекомендуется) или Bluedroid. GATT Server — ESP32 как BLE периферия#include <NimBLEDevice.h> // UUID сервисов и характеристик (генерируйте свои на uuidgenerator.net) #define SERVICE_UUID "4fafc201-1fb5-459e-8fcc-c5c9c331914b" #define TEMPERATURE_UUID "beb5483e-36e1-4688-b7f5-ea07361b26a8" #define CONTROL_UUID "beb5483e-36e1-4688-b7f5-ea07361b26a9" NimBLEServer* pServer = nullptr; NimBLECharacteristic* pTempChar = nullptr; NimBLECharacteristic* pCtrlChar = nullptr; bool deviceConnected = false; // Callbacks для событий подключения class ServerCallbacks : public NimBLEServerCallbacks { void onConnect(NimBLEServer* pServer, ble_gap_conn_desc* desc) override { deviceConnected = true; Serial.printf("BLE: клиент подключён, addr: %s\n", NimBLEAddress(desc->peer_ota_addr).toString().c_str()); // Обновляем параметры соединения для лучшей производительности pServer->updateConnParams(desc->conn_handle, 6, 6, 0, 100); } void onDisconnect(NimBLEServer* pServer) override { deviceConnected = false; Serial.println("BLE: клиент отключился"); // Перезапускаем рекламу NimBLEDevice::startAdvertising(); } }; // Callbacks для записи характеристики управления class ControlCallbacks : public NimBLECharacteristicCallbacks { void onWrite(NimBLECharacteristic* pChar) override { std::string value = pChar->getValue(); if (value.length() > 0) { uint8_t command = value[0]; Serial.printf("BLE: команда получена: 0x%02X\n", command); switch (command) { case 0x01: relay_on(); break; case 0x00: relay_off(); break; } } } }; void ble_init() { NimBLEDevice::init("ESP32-Sensor"); NimBLEDevice::setMTU(185); // Увеличиваем MTU для больших пакетов pServer = NimBLEDevice::createServer(); pServer->setCallbacks(new ServerCallbacks()); // Создаём сервис NimBLEService* pService = pServer->createService(SERVICE_UUID); // Характеристика температуры (только чтение + уведомления) pTempChar = pService->createCharacteristic( TEMPERATURE_UUID, NIMBLE_PROPERTY::READ | NIMBLE_PROPERTY::NOTIFY ); pTempChar->setValue(0.0f); // Характеристика управления (запись) pCtrlChar = pService->createCharacteristic( CONTROL_UUID, NIMBLE_PROPERTY::WRITE | NIMBLE_PROPERTY::WRITE_NR // NR = No Response (быстрее) ); pCtrlChar->setCallbacks(new ControlCallbacks()); pService->start(); // Настройка рекламы NimBLEAdvertising* pAdv = NimBLEDevice::getAdvertising(); pAdv->addServiceUUID(SERVICE_UUID); pAdv->setScanResponse(true); pAdv->setMinPreferred(0x06); pAdv->start(); Serial.println("BLE запущен, ожидаем подключения..."); } // Обновление данных температуры (вызывать периодически) void ble_update_temperature(float temperature) { if (!deviceConnected) return; // Отправляем float как 4 байта uint8_t data[4]; memcpy(data, &temperature, 4); pTempChar->setValue(data, 4); pTempChar->notify(); // Push уведомление подключённому клиенту } NVS: хранение настроек во FlashNVS (Non-Volatile Storage) — key-value хранилище в Flash памяти ESP32. Пережи вает перезагрузки и обновления прошивки: #include <Preferences.h> // Arduino framework Preferences prefs; struct DeviceConfig { char mqtt_host[64]; uint16_t mqtt_port; char device_id[32]; float setpoint; bool auto_mode; }; DeviceConfig config; void config_load_defaults() { strlcpy(config.mqtt_host, "192.168.1.100", sizeof(config.mqtt_host)); config.mqtt_port = 1883; strlcpy(config.device_id, "esp32_001", sizeof(config.device_id)); config.setpoint = 25.0f; config.auto_mode = true; } bool config_load() { prefs.begin("config", true); // true = read-only if (!prefs.isKey("mqtt_host")) { prefs.end(); return false; // Первый запуск — нет сохранённых настроек } prefs.getString("mqtt_host", config.mqtt_host, sizeof(config.mqtt_host)); config.mqtt_port = prefs.getUShort("mqtt_port", 1883); prefs.getString("device_id", config.device_id, sizeof(config.device_id)); config.setpoint = prefs.getFloat("setpoint", 25.0f); config.auto_mode = prefs.getBool("auto_mode", true); prefs.end(); return true; } void config_save() { prefs.begin("config", false); // false = read-write prefs.putString("mqtt_host", config.mqtt_host); prefs.putUShort("mqtt_port", config.mqtt_port); prefs.putString("device_id", config.device_id); prefs.putFloat("setpoint", config.setpoint); prefs.putBool("auto_mode", config.auto_mode); prefs.end(); Serial.println("Конфигурация сохранена в NVS"); } void config_reset() { prefs.begin("config", false); prefs.clear(); prefs.end(); Serial.println("NVS очищен, перезагрузка..."); ESP.restart(); } // Использование: void setup() { if (!config_load()) { Serial.println("Первый запуск, загружаем дефолты"); config_load_defaults(); config_save(); } Serial.printf("MQTT: %s:%d\n", config.mqtt_host, config.mqtt_port); } OTA: обновление прошивки по воздухуESP32: глубокое погружение#include <ArduinoOTA.h> #include <Update.h> // ===== ПРОСТОЕ OTA ЧЕРЕЗ Arduino IDE ===== void ota_init_arduino() { ArduinoOTA.setHostname("esp32-gateway-001"); ArduinoOTA.setPassword("ota_secret_password"); ArduinoOTA.onStart([]() { String type = ArduinoOTA.getCommand() == U_FLASH ? "прошивку" : "файловую систему"; Serial.printf("OTA: начало обновления %s\n", type.c_str()); // Останавливаем критичные задачи перед обновлением mqtt_stop(); modbus_stop(); }); ArduinoOTA.onEnd([]() { Serial.println("OTA: обновление завершено, перезагрузка..."); }); ArduinoOTA.onProgress([](unsigned int progress, unsigned int total) { static uint8_t last_pct = 0; uint8_t pct = progress * 100 / total; if (pct != last_pct && pct % 10 == 0) { Serial.printf("OTA: %u%%\n", pct); last_pct = pct; } }); ArduinoOTA.onError([](ota_error_t error) { const char* errors[] = {"Auth Failed", "Begin Failed", "Connect Failed", "Receive Failed", "End Failed"}; Serial.printf("OTA Ошибка[%u]: %s\n", error, error <= 4 ? errors[error] : "Unknown"); }); ArduinoOTA.begin(); } // В loop() добавить: // ArduinoOTA.handle(); // ===== HTTP OTA: скачивание прошивки с сервера ===== #include <HTTPUpdate.h> #include <WiFiClientSecure.h> void ota_update_from_server(const char* server_url) { Serial.printf("OTA: загрузка с %s\n", server_url); WiFiClient client; // Или WiFiClientSecure для HTTPS (настройте сертификат!) httpUpdate.setLedPin(LED_BUILTIN, LOW); // Callback прогресса httpUpdate.onProgress([](int current, int total) { Serial.printf("OTA: %d/%d bytes (%d%%)\n", current, total, current * 100 / total); }); t_httpUpdate_return ret = httpUpdate.update(client, server_url); switch (ret) { case HTTP_UPDATE_FAILED: Serial.printf("OTA ошибка (%d): %s\n", httpUpdate.getLastError(), httpUpdate.getLastErrorString().c_str()); break; case HTTP_UPDATE_NO_UPDATES: Serial.println("OTA: нет обновлений"); break; case HTTP_UPDATE_OK: Serial.println("OTA: успех, перезагрузка..."); break; } } // Проверка обновлений по расписанию: void check_for_updates() { static uint32_t lastCheck = 0; const uint32_t CHECK_INTERVAL = 3600000UL; // 1 час if (millis() - lastCheck < CHECK_INTERVAL) return; lastCheck = millis(); // Проверяем версию на сервере String server_version = http_get_json("/api/firmware/version")["version"]; if (server_version != FIRMWARE_VERSION) { Serial.printf("Доступна новая версия: %s (текущая: %s)\n", server_version.c_str(), FIRMWARE_VERSION); ota_update_from_server("http://server/firmware/latest.bin"); } } Deep Sleep: энергосбережениеESP32 в active mode потребляет ~80–240 мА. В deep sleep — 10 мкА! #include <esp_sleep.h> #include <esp_wifi.h> // Типы пробуждения: // - Таймер (RTC таймер) // - GPIO (кнопка, сигнал) // - Touch (сенсорные входы) // - ULP (Ultra-Low Power co-processor) // - UART (RXD0) // - BT (в режиме light sleep) void go_to_deep_sleep(uint32_t sleep_seconds) { Serial.printf("Уходим в сон на %u секунд...\n", sleep_seconds); Serial.flush(); // Закрываем WiFi перед сном (экономит время пробуждения) WiFi.disconnect(true); WiFi.mode(WIFI_OFF); // Настраиваем пробуждение по таймеру esp_sleep_enable_timer_wakeup((uint64_t)sleep_seconds * 1000000ULL); // Пробуждение от GPIO4 (нажатие кнопки) esp_sleep_enable_ext0_wakeup(GPIO_NUM_4, 0); // 0 = LOW уровень // Входим в deep sleep esp_deep_sleep_start(); // Код после этой строки не выполнится! } void setup() { Serial.begin(115200); // Определяем причину пробуждения esp_sleep_wakeup_cause_t cause = esp_sleep_get_wakeup_cause(); switch (cause) { case ESP_SLEEP_WAKEUP_TIMER: Serial.println("Пробуждение: таймер"); send_sensor_data(); // Отправляем данные и снова в сон break; case ESP_SLEEP_WAKEUP_EXT0: Serial.println("Пробуждение: кнопка"); // Пользователь нажал кнопку — полная работа full_operation_mode(); return; case ESP_SLEEP_WAKEUP_UNDEFINED: Serial.println("Первый запуск или reset"); first_boot_setup(); break; default: Serial.printf("Причина: %d\n", cause); } // Снова в сон через 60 секунд go_to_deep_sleep(60); } // RTC Memory: данные переживают deep sleep! RTC_DATA_ATTR int boot_count = 0; RTC_DATA_ATTR float last_temperature = 0.0f; RTC_DATA_ATTR uint32_t error_count = 0; void setup_with_rtc_memory() { boot_count++; Serial.printf("Загрузка #%d, последняя T=%.1f°C\n", boot_count, last_temperature); // Читаем датчик, сохраняем в RTC memory last_temperature = read_temperature(); go_to_deep_sleep(300); // 5 минут } ADC: правильная работа с АЦПАЦП ESP32 имеет репутацию "неточного". Это правда — и вот почему и как с этим работать: #include <esp_adc/adc_oneshot.h> #include <esp_adc/adc_cali.h> #include <esp_adc/adc_cali_scheme.h> // Калиброванный ADC на ESP-IDF (точность ±5мВ вместо ±50мВ) adc_oneshot_unit_handle_t adc1_handle; adc_cali_handle_t cali_handle; void adc_init_calibrated() { // Инициализация ADC adc_oneshot_unit_init_cfg_t init_config = { .unit_id = ADC_UNIT_1, .ulp_mode = ADC_ULP_MODE_DISABLE, }; ESP_ERROR_CHECK(adc_oneshot_new_unit(&init_config, &adc1_handle)); // Настройка канала (GPIO34 = ADC1 Channel 6) adc_oneshot_chan_cfg_t chan_config = { .bitwidth = ADC_BITWIDTH_12, .atten = ADC_ATTEN_DB_12, // 0-3.3В диапазон }; ESP_ERROR_CHECK(adc_oneshot_config_channel(adc1_handle, ADC_CHANNEL_6, &chan_config)); // Калибровка (Line Fitting или Curve Fitting) adc_cali_line_fitting_config_t cali_config = { .unit_id = ADC_UNIT_1, .atten = ADC_ATTEN_DB_12, .bitwidth = ADC_BITWIDTH_12, }; ESP_ERROR_CHECK(adc_cali_create_scheme_line_fitting(&cali_config, &cali_handle)); } float adc_read_voltage_mv() { int raw; ESP_ERROR_CHECK(adc_oneshot_read(adc1_handle, ADC_CHANNEL_6, &raw)); int voltage_mv; ESP_ERROR_CHECK(adc_cali_raw_to_voltage(cali_handle, raw, &voltage_mv)); return (float)voltage_mv; } // Oversampling для повышения точности (16x → +2 бита) float adc_read_averaged(int samples = 64) { int64_t sum = 0; for (int i = 0; i < samples; i++) { int raw; adc_oneshot_read(adc1_handle, ADC_CHANNEL_6, &raw); sum += raw; delayMicroseconds(100); } int avg_raw = sum / samples; int voltage_mv; adc_cali_raw_to_voltage(cali_handle, avg_raw, &voltage_mv); return (float)voltage_mv; } // Важные ограничения ADC ESP32: // - GPIO36, 37, 38, 39: только вход, без pullup/pulldown в кристалле // - ADC2 нельзя использовать одновременно с WiFi! // - Нелинейность вблизи 0В и 3.3В — оставайтесь в диапазоне 100мВ..3.1В // - Для точных измерений: внешний АЦП MCP3208 по SPI Практический проект: промышленный IoT узел// Полная архитектура ESP32 IoT узла #include <Arduino.h> #include <WiFi.h> #include <PubSubClient.h> #include <ArduinoJson.h> #include <Preferences.h> // ===== КОНФИГУРАЦИЯ ===== #define FIRMWARE_VERSION "1.2.3" #define DEVICE_MODEL "ESP32-IoT-Node" #define PUBLISH_INTERVAL_MS 5000 #define WATCHDOG_TIMEOUT_MS 30000 // ===== ГЛОБАЛЬНОЕ СОСТОЯНИЕ ===== struct State { bool wifi_connected = false; bool mqtt_connected = false; float temperature = 0; float humidity = 0; float pressure = 0; uint32_t uptime_sec = 0; uint32_t publish_count = 0; uint32_t error_count = 0; }; State state; WiFiClient wifiClient; PubSubClient mqtt(wifiClient); // ===== МНОГОЗАДАЧНОСТЬ ===== QueueHandle_t sensorQueue; SemaphoreHandle_t stateMutex; // Задача: чтение датчиков (Core 1) void task_sensors(void *pv) { for (;;) { // Здесь: читаем датчики float t = 25.0 + random(-10, 10) / 10.0; // Имитация float h = 50.0 + random(-5, 5) / 10.0; // Обновляем состояние через мьютекс xSemaphoreTake(stateMutex, portMAX_DELAY); state.temperature = t; state.humidity = h; xSemaphoreGive(stateMutex); vTaskDelay(pdMS_TO_TICKS(1000)); } } // Задача: MQTT публикация (Core 0, рядом с WiFi) void task_mqtt(void *pv) { for (;;) { if (!mqtt.connected()) { if (WiFi.isConnected()) { if (mqtt.connect("esp32-node", "user", "pass", "nodes/esp32-001/status", 1, true, "{\"online\":false}")) { mqtt.publish("nodes/esp32-001/status", "{\"online\":true}", true); mqtt.subscribe("nodes/esp32-001/commands"); } } } mqtt.loop(); // Публикация данных static uint32_t lastPublish = 0; if (millis() - lastPublish >= PUBLISH_INTERVAL_MS) { lastPublish = millis(); StaticJsonDocument<256> doc; xSemaphoreTake(stateMutex, portMAX_DELAY); doc["temperature"] = state.temperature; doc["humidity"] = state.humidity; doc["uptime"] = state.uptime_sec; doc["errors"] = state.error_count; doc["version"] = FIRMWARE_VERSION; doc["rssi"] = WiFi.RSSI(); doc["free_heap"] = ESP.getFreeHeap(); xSemaphoreGive(stateMutex); char payload[256]; serializeJson(doc, payload); mqtt.publish("nodes/esp32-001/telemetry", payload); state.publish_count++; } vTaskDelay(pdMS_TO_TICKS(10)); } } // Задача: watchdog и uptime (Core 1) void task_system(void *pv) { for (;;) { state.uptime_sec++; // Проверка heap (memory leak detection) if (ESP.getFreeHeap() < 10000) { Serial.println("КРИТИЧНО: мало памяти! Перезагрузка..."); ESP.restart(); } // Heartbeat LED digitalWrite(LED_BUILTIN, !digitalRead(LED_BUILTIN)); vTaskDelay(pdMS_TO_TICKS(1000)); } } void setup() { Serial.begin(115200); Serial.printf("\nESP32 IoT Node v%s\n", FIRMWARE_VERSION); Serial.printf("Chip: %s, Rev: %d, Cores: %d\n", ESP.getChipModel(), ESP.getChipRevision(), ESP.getChipCores()); // Инициализация stateMutex = xSemaphoreCreateMutex(); sensorQueue = xQueueCreate(10, sizeof(float)); // WiFi WiFi.mode(WIFI_STA); WiFi.begin("SSID", "PASSWORD"); // MQTT mqtt.setServer("192.168.1.100", 1883); mqtt.setBufferSize(1024); // Запускаем задачи на разных ядрах xTaskCreatePinnedToCore(task_sensors, "Sensors", 4096, NULL, 3, NULL, 1); xTaskCreatePinnedToCore(task_mqtt, "MQTT", 8192, NULL, 4, NULL, 0); xTaskCreatePinnedToCore(task_system, "System", 2048, NULL, 1, NULL, 1); Serial.println("Задачи запущены"); } void loop() { // loop() работает на Core 1 с низким приоритетом // Можно использовать для некритичных задач или оставить пустым vTaskDelay(pdMS_TO_TICKS(1000)); } Выбор инструментария: Arduino vs ESP-IDFКритерий Arduino Framework ESP-IDF (native) Порог входа Низкий Высокий Документация Обширная, много примеров Официальная, полная Производительность Достаточная Максимальная Доступ к периферии Через библиотеки Прямой Размер бинарника Больше Меньше RTOS Доступен (FreeRTOS через задачи) Нативный Время разработки Быстрее Медленнее Production-ready Да (если делать правильно) Да Рекомендация Прототипы, несложные задачи Серийное производство ЗаключениеESP32 — один из лучших выборов для промышленных IoT-узлов с умеренными требованиями к реальному времени. Двухъядерность позволяет изолировать WiFi-стек от прикладного кода, богатая периферия закрывает большинство интерфейсных задач, встроенный FreeRTOS — для многозадачности. Ключевые принципы надёжного ESP32-устройства: статический IP вместо DHCP, watchdog timer, NVS для конфигурации, OTA для обновлений, RTC memory для данных через sleep, мониторинг heap и перезагрузка при критичном уровне. ESP32 — это не замена промышленному ПЛК. Но как edge-узел сбора данных, шлюз протоколов или умный датчик — идеальный выбор. -
 Зачем Docker: "работает на моей машине"История, знакомая каждому разработчику. Приложение работает на вашем ноутбуке. Выкладываете на сервер — падает. Отличия: версия Python 3.9 vs 3.11, разные системные библиотеки, другая переменная PATH, конфликт зависимостей с другим приложением. Docker решает эту проблему радикально: упаковывает приложение вместе со всем окружением — операционной системой, библиотеками, конфигурацией. Контейнер запускается одинаково везде: на ноутбуке разработчика, в CI/CD, на production-сервере, в облаке. Дополнительные бонусы: Изоляция: одно приложение не мешает другому Воспроизводимость: одинаковая среда у всей команды Быстрое развёртывание: docker pull + docker run вместо часа установки Масштабирование: запустить 10 экземпляров так же легко, как 1 Чистота: удалить контейнер = никаких следов на хосте Основные концепцииImage (образ): Слоёная файловая система со всем необходимым. Неизменяемый шаблон. Хранится в Registry (Docker Hub, GitHub Container Registry, ваш собственный). Container (контейнер): Запущенный экземпляр образа. Изолированный процесс с собственной файловой системой, сетью, PID-пространством. Контейнеры ephemeral — данные исчезают при удалении (если нет Volume). Volume (том): Постоянное хранилище данных, переживает удаление контейнера. Network (сеть): Изолированная виртуальная сеть. Контейнеры в одной сети видят друг друга по имени. Dockerfile: Инструкции для сборки образа. Каждая инструкция — новый слой. Registry: Хранилище образов. Docker Hub — публичный. Можно развернуть свой (Harbor, Nexus). Dockerfile: пишем правильноБазовый пример (Python приложение):# Начинаем с официального образа Python # ВАЖНО: всегда указывайте точную версию, не :latest! FROM python:3.11-slim # Метаданные LABEL maintainer="your@email.com" LABEL version="1.0" LABEL description="Industrial IoT Gateway" # Устанавливаем рабочую директорию WORKDIR /app # Копируем ТОЛЬКО файлы зависимостей первыми! # Слои кешируются — если requirements.txt не изменился, # pip install не запустится при следующей сборке COPY requirements.txt . # Устанавливаем зависимости RUN pip install --no-cache-dir -r requirements.txt # Копируем исходный код (изменяется чаще — поэтому последним) COPY src/ ./src/ COPY config/ ./config/ # Создаём непривилегированного пользователя (безопасность!) RUN groupadd -r appuser && useradd -r -g appuser appuser RUN chown -R appuser:appuser /app USER appuser # Переменные окружения ENV PYTHONUNBUFFERED=1 \ PYTHONDONTWRITEBYTECODE=1 \ LOG_LEVEL=INFO # Открываем порт (документация, не публикует сам по себе) EXPOSE 8080 # Healthcheck: Docker проверяет живость контейнера HEALTHCHECK --interval=30s --timeout=10s --start-period=15s --retries=3 \ CMD curl -f http://localhost:8080/health || exit 1 # Команда запуска CMD ["python", "-m", "uvicorn", "src.main:app", "--host", "0.0.0.0", "--port", "8080"] Многоэтапная сборка (Multi-stage build):Критически важна для production. Финальный образ не содержит инструментов сборки (gcc, make, pip), что уменьшает размер и поверхность атаки: # ===== ЭТАП 1: Сборка ===== FROM python:3.11 AS builder WORKDIR /build # Устанавливаем зависимости для сборки RUN apt-get update && apt-get install -y --no-install-recommends \ gcc \ libffi-dev \ && rm -rf /var/lib/apt/lists/* COPY requirements.txt . # Устанавливаем в отдельную директорию RUN pip install --no-cache-dir --prefix=/install -r requirements.txt # ===== ЭТАП 2: Production образ ===== FROM python:3.11-slim AS production # Копируем только установленные пакеты из builder COPY --from=builder /install /usr/local WORKDIR /app # Только runtime зависимости ОС RUN apt-get update && apt-get install -y --no-install-recommends \ curl \ && rm -rf /var/lib/apt/lists/* \ && apt-get clean # Безопасность RUN groupadd -r app && useradd -r -g app -d /app -s /sbin/nologin app COPY --chown=app:app src/ ./src/ USER app ENV PYTHONUNBUFFERED=1 HEALTHCHECK --interval=30s --timeout=5s CMD curl -f http://localhost:8080/health CMD ["python", "src/main.py"] # Результат: образ ~180MB вместо ~900MB! .dockerignore — что НЕ копировать в образ:# .dockerignore **/__pycache__ **/*.pyc **/*.pyo .git .gitignore .venv venv *.env .env.* tests/ docs/ *.md .github/ node_modules/ dist/ *.log .DS_Store # Секреты — никогда в образ! *.key *.pem *secret* config.local.* Docker Compose: многосервисные приложенияDocker Compose — инструмент для запуска нескольких связанных контейнеров. Полный пример: IoT-платформа# docker-compose.yml version: '3.9' # Общие настройки через YAML anchors (DRY) x-common-env: &common-env TZ: Europe/Moscow LOG_LEVEL: ${LOG_LEVEL:-INFO} x-restart-policy: &restart-policy restart: unless-stopped services: # ===== MQTT БРОКЕР ===== mosquitto: image: eclipse-mosquitto:2.0.18 <<: *restart-policy volumes: - ./mosquitto/config:/mosquitto/config:ro - mosquitto_data:/mosquitto/data - mosquitto_logs:/mosquitto/log ports: - "1883:1883" # MQTT - "9001:9001" # WebSocket networks: - iot_network healthcheck: test: ["CMD", "mosquitto_sub", "-t", "$$SYS/#", "-C", "1", "-i", "healthcheck"] interval: 30s timeout: 10s retries: 3 # ===== БАЗА ДАННЫХ ВРЕМЕННЫХ РЯДОВ ===== influxdb: image: influxdb:2.7 <<: *restart-policy environment: <<: *common-env DOCKER_INFLUXDB_INIT_MODE: setup DOCKER_INFLUXDB_INIT_USERNAME: ${INFLUX_USER:-admin} DOCKER_INFLUXDB_INIT_PASSWORD: ${INFLUX_PASSWORD:?INFLUX_PASSWORD required} DOCKER_INFLUXDB_INIT_ORG: factory DOCKER_INFLUXDB_INIT_BUCKET: telemetry DOCKER_INFLUXDB_INIT_RETENTION: 30d DOCKER_INFLUXDB_INIT_ADMIN_TOKEN: ${INFLUX_TOKEN:?INFLUX_TOKEN required} volumes: - influxdb_data:/var/lib/influxdb2 - influxdb_config:/etc/influxdb2 ports: - "8086:8086" networks: - iot_network - monitoring_network healthcheck: test: ["CMD", "curl", "-f", "http://localhost:8086/health"] interval: 30s timeout: 10s retries: 5 start_period: 30s # ===== GRAFANA ===== grafana: image: grafana/grafana:10.3.1 <<: *restart-policy depends_on: influxdb: condition: service_healthy environment: <<: *common-env GF_SECURITY_ADMIN_USER: ${GF_ADMIN_USER:-admin} GF_SECURITY_ADMIN_PASSWORD: ${GF_ADMIN_PASSWORD:?required} GF_SERVER_ROOT_URL: http://localhost:3000 GF_SMTP_ENABLED: "true" GF_SMTP_HOST: ${SMTP_HOST:-localhost:25} volumes: - grafana_data:/var/lib/grafana - ./grafana/provisioning:/etc/grafana/provisioning:ro - ./grafana/dashboards:/var/lib/grafana/dashboards:ro ports: - "3000:3000" networks: - monitoring_network user: "472" # grafana user # ===== IOT ШЛЮЗ (наш сервис) ===== gateway: build: context: . dockerfile: Dockerfile target: production args: BUILD_DATE: ${BUILD_DATE:-unknown} GIT_COMMIT: ${GIT_COMMIT:-unknown} <<: *restart-policy depends_on: mosquitto: condition: service_healthy influxdb: condition: service_healthy environment: <<: *common-env MQTT_HOST: mosquitto # Имя сервиса = DNS-имя внутри сети! MQTT_PORT: 1883 INFLUX_URL: http://influxdb:8086 INFLUX_TOKEN: ${INFLUX_TOKEN} INFLUX_ORG: factory INFLUX_BUCKET: telemetry MODBUS_PORT: /dev/ttyUSB0 # Реальный порт с хоста volumes: - ./config:/app/config:ro - gateway_logs:/app/logs devices: - "/dev/ttyUSB0:/dev/ttyUSB0" # Проброс USB-устройства ports: - "8080:8080" networks: - iot_network - monitoring_network deploy: resources: limits: cpus: '1.0' memory: 512M reservations: cpus: '0.25' memory: 128M # ===== NGINX: реверс-прокси ===== nginx: image: nginx:1.25-alpine <<: *restart-policy depends_on: - grafana - gateway volumes: - ./nginx/nginx.conf:/etc/nginx/nginx.conf:ro - ./nginx/ssl:/etc/nginx/ssl:ro # TLS сертификаты ports: - "80:80" - "443:443" networks: - monitoring_network # ===== ТОМА ===== volumes: mosquitto_data: mosquitto_logs: influxdb_data: influxdb_config: grafana_data: gateway_logs: # ===== СЕТИ ===== networks: iot_network: # Для IoT-компонентов driver: bridge monitoring_network: # Для мониторинга и UI driver: bridge .env файл для Compose:# .env — НЕ коммитить в git! INFLUX_USER=admin INFLUX_PASSWORD=super_secret_influx_pass INFLUX_TOKEN=my-super-secret-token-change-this GF_ADMIN_USER=admin GF_ADMIN_PASSWORD=super_secret_grafana_pass LOG_LEVEL=INFO BUILD_DATE=2024-03-15 GIT_COMMIT=abc123 Docker: ключевые команды# ===== ОБРАЗЫ ===== docker build -t myapp:1.0 . # Собрать образ docker build --no-cache -t myapp:1.0 . # Без кеша docker images # Список образов docker rmi myapp:1.0 # Удалить образ docker image prune # Удалить неиспользуемые # История слоёв (анализ размера): docker history myapp:1.0 # ===== КОНТЕЙНЕРЫ ===== docker run -d \ --name gateway \ -p 8080:8080 \ -e MQTT_HOST=192.168.1.100 \ -v $(pwd)/config:/app/config:ro \ --restart unless-stopped \ myapp:1.0 docker ps # Запущенные контейнеры docker ps -a # Все (включая остановленные) docker logs gateway -f # Логи в реальном времени docker logs gateway --tail 100 # Последние 100 строк docker exec -it gateway bash # Войти внутрь контейнера docker stop gateway # Остановить docker start gateway # Запустить docker restart gateway # Перезапустить docker rm gateway # Удалить (сначала stop) docker stats # Потребление ресурсов # ===== COMPOSE ===== docker compose up -d # Запустить все сервисы docker compose up -d gateway # Запустить только gateway docker compose down # Остановить и удалить контейнеры docker compose down -v # + удалить тома (ОСТОРОЖНО!) docker compose logs -f # Логи всех сервисов docker compose logs -f gateway # Логи конкретного сервиса docker compose ps # Статус сервисов docker compose pull # Обновить образы docker compose build --no-cache # Пересобрать docker compose restart gateway # Перезапустить сервис docker compose exec gateway bash # Войти в контейнер # ===== REGISTRY ===== docker tag myapp:1.0 ghcr.io/myorg/myapp:1.0 docker push ghcr.io/myorg/myapp:1.0 docker pull ghcr.io/myorg/myapp:1.0 # ===== ОЧИСТКА ===== docker system prune -a # Удалить ВСЁ неиспользуемое docker volume prune # Удалить неиспользуемые тома Volumes и persistence: не теряем данные# Типы монтирования: services: app: volumes: # 1. Named Volume (рекомендуется для данных БД) - db_data:/var/lib/postgresql/data # 2. Bind Mount (для конфигов и разработки) - ./config:/app/config:ro # :ro = read-only - ./src:/app/src # Для hot-reload при разработке # 3. tmpfs (только в RAM, для временных данных) - type: tmpfs target: /tmp tmpfs: size: 100M volumes: db_data: driver: local # Для production: внешние тома # external: true # name: prod_db_data Backup томов:# Резервная копия тома influxdb_data docker run --rm \ -v influxdb_data:/source:ro \ -v $(pwd)/backups:/backup \ alpine:3 \ tar czf /backup/influxdb_$(date +%Y%m%d).tar.gz -C /source . # Восстановление docker run --rm \ -v influxdb_data:/target \ -v $(pwd)/backups:/backup:ro \ alpine:3 \ tar xzf /backup/influxdb_20240315.tar.gz -C /target Оптимизация размера образа# ❌ ПЛОХО: большой образ FROM ubuntu:22.04 RUN apt-get update RUN apt-get install -y python3 RUN apt-get install -y python3-pip RUN pip3 install flask COPY app.py . CMD ["python3", "app.py"] # Размер: ~480 МБ, 5 лишних слоёв # ✅ ХОРОШО: оптимизированный образ FROM python:3.11-slim RUN pip install --no-cache-dir flask COPY app.py . CMD ["python", "app.py"] # Размер: ~85 МБ, чистая сборка # ✅ ЕЩЁ ЛУЧШЕ: alpine (минимальный дистрибутив) FROM python:3.11-alpine # Некоторые C-расширения нужно собирать RUN apk add --no-cache gcc musl-dev && \ pip install --no-cache-dir flask && \ apk del gcc musl-dev COPY app.py . CMD ["python", "app.py"] # Размер: ~45 МБ Правило минимума слоёв для apt/apk: # Объединяйте RUN команды в одну для минимизации слоёв RUN apt-get update && \ apt-get install -y --no-install-recommends \ curl \ libpq5 \ && rm -rf /var/lib/apt/lists/* \ && apt-get clean # ОДИН слой вместо нескольких, и сразу очистка кеша Безопасность Docker1. Никогда не запускать от root:# Создаём непривилегированного пользователя RUN addgroup -S appgroup && adduser -S appuser -G appgroup USER appuser 2. Read-only файловая система:services: app: read_only: true # Файловая система только для чтения tmpfs: - /tmp # Разрешаем запись только в tmpfs - /var/run 3. Ограничение capabilities:services: app: cap_drop: - ALL # Убираем ВСЕ capabilities cap_add: - NET_BIND_SERVICE # Добавляем только необходимые 4. Сканирование образов на уязвимости:# Trivy — бесплатный сканер (Aqua Security) docker run --rm aquasec/trivy image myapp:1.0 # Или встроенный Docker Scout docker scout cves myapp:1.0 5. Secrets — не в переменных окружения production:# docker-compose.yml с Docker secrets services: app: secrets: - db_password - api_key environment: DB_PASSWORD_FILE: /run/secrets/db_password # Читаем из файла! secrets: db_password: file: ./secrets/db_password.txt # или external: true для Swarm/K8s Healthcheck и зависимости между сервисамиservices: postgres: image: postgres:15 healthcheck: test: ["CMD-SHELL", "pg_isready -U ${POSTGRES_USER}"] interval: 10s timeout: 5s retries: 5 start_period: 30s # Даём время на инициализацию app: depends_on: postgres: condition: service_healthy # Ждём пока postgres healthy! redis: condition: service_healthy Entrypoint-скрипт для ожидания зависимостей:#!/bin/sh # entrypoint.sh set -e echo "Ожидание готовности базы данных..." until nc -z -w5 ${DB_HOST} ${DB_PORT}; do echo "База данных недоступна, ждём..." sleep 2 done echo "База данных готова!" # Запуск миграций python manage.py migrate --no-input # Запуск приложения exec "$@" COPY entrypoint.sh /entrypoint.sh RUN chmod +x /entrypoint.sh ENTRYPOINT ["/entrypoint.sh"] CMD ["gunicorn", "app:application"] Docker в CI/CD (GitHub Actions)# .github/workflows/docker.yml name: Build and Deploy on: push: tags: ['v*.*.*'] jobs: build-push: runs-on: ubuntu-latest permissions: contents: read packages: write steps: - uses: actions/checkout@v4 - name: Set up Docker Buildx uses: docker/setup-buildx-action@v3 - name: Login to GitHub Container Registry uses: docker/login-action@v3 with: registry: ghcr.io username: ${{ github.actor }} password: ${{ secrets.GITHUB_TOKEN }} - name: Build and push uses: docker/build-push-action@v5 with: context: . platforms: linux/amd64,linux/arm64 # Multi-arch! push: true tags: | ghcr.io/${{ github.repository }}:${{ github.ref_name }} ghcr.io/${{ github.repository }}:latest cache-from: type=gha cache-to: type=gha,mode=max build-args: | GIT_COMMIT=${{ github.sha }} BUILD_DATE=${{ github.event.head_commit.timestamp }} deploy: needs: build-push runs-on: ubuntu-latest environment: production steps: - name: Deploy to server uses: appleboy/ssh-action@v1 with: host: ${{ secrets.SERVER_HOST }} username: deploy key: ${{ secrets.SERVER_SSH_KEY }} script: | cd /opt/iot-platform # Обновляем образ docker compose pull gateway # Обновляем с нулевым downtime docker compose up -d --no-deps gateway # Ждём healthcheck sleep 15 docker compose ps gateway | grep -q "healthy" || exit 1 echo "Деплой успешен!" Заключение: когда Docker, когда нетИспользуйте Docker: Приложения с множеством зависимостей Многосервисные приложения (backend + БД + брокер + мониторинг) CI/CD с гарантированной воспроизводимостью Несколько приложений на одном сервере Нужна возможность быстрого масштабирования Не обязательно Docker: Простые скрипты без зависимостей Приложения с прямым доступом к оборудованию (хотя --device помогает) Жёсткое реальное время (latency контейнера ~1 мкс, но это не ноль) Команда незнакома с Docker — сначала обучение, потом внедрение Docker — это не серебряная пуля, но инвестиция в него окупается быстро. Начните с docker-compose.yml для локальной разработки — уже это даст ощутимый результат: одна команда docker compose up поднимает весь стек вместо часа настройки.
Зачем Docker: "работает на моей машине"История, знакомая каждому разработчику. Приложение работает на вашем ноутбуке. Выкладываете на сервер — падает. Отличия: версия Python 3.9 vs 3.11, разные системные библиотеки, другая переменная PATH, конфликт зависимостей с другим приложением. Docker решает эту проблему радикально: упаковывает приложение вместе со всем окружением — операционной системой, библиотеками, конфигурацией. Контейнер запускается одинаково везде: на ноутбуке разработчика, в CI/CD, на production-сервере, в облаке. Дополнительные бонусы: Изоляция: одно приложение не мешает другому Воспроизводимость: одинаковая среда у всей команды Быстрое развёртывание: docker pull + docker run вместо часа установки Масштабирование: запустить 10 экземпляров так же легко, как 1 Чистота: удалить контейнер = никаких следов на хосте Основные концепцииImage (образ): Слоёная файловая система со всем необходимым. Неизменяемый шаблон. Хранится в Registry (Docker Hub, GitHub Container Registry, ваш собственный). Container (контейнер): Запущенный экземпляр образа. Изолированный процесс с собственной файловой системой, сетью, PID-пространством. Контейнеры ephemeral — данные исчезают при удалении (если нет Volume). Volume (том): Постоянное хранилище данных, переживает удаление контейнера. Network (сеть): Изолированная виртуальная сеть. Контейнеры в одной сети видят друг друга по имени. Dockerfile: Инструкции для сборки образа. Каждая инструкция — новый слой. Registry: Хранилище образов. Docker Hub — публичный. Можно развернуть свой (Harbor, Nexus). Dockerfile: пишем правильноБазовый пример (Python приложение):# Начинаем с официального образа Python # ВАЖНО: всегда указывайте точную версию, не :latest! FROM python:3.11-slim # Метаданные LABEL maintainer="your@email.com" LABEL version="1.0" LABEL description="Industrial IoT Gateway" # Устанавливаем рабочую директорию WORKDIR /app # Копируем ТОЛЬКО файлы зависимостей первыми! # Слои кешируются — если requirements.txt не изменился, # pip install не запустится при следующей сборке COPY requirements.txt . # Устанавливаем зависимости RUN pip install --no-cache-dir -r requirements.txt # Копируем исходный код (изменяется чаще — поэтому последним) COPY src/ ./src/ COPY config/ ./config/ # Создаём непривилегированного пользователя (безопасность!) RUN groupadd -r appuser && useradd -r -g appuser appuser RUN chown -R appuser:appuser /app USER appuser # Переменные окружения ENV PYTHONUNBUFFERED=1 \ PYTHONDONTWRITEBYTECODE=1 \ LOG_LEVEL=INFO # Открываем порт (документация, не публикует сам по себе) EXPOSE 8080 # Healthcheck: Docker проверяет живость контейнера HEALTHCHECK --interval=30s --timeout=10s --start-period=15s --retries=3 \ CMD curl -f http://localhost:8080/health || exit 1 # Команда запуска CMD ["python", "-m", "uvicorn", "src.main:app", "--host", "0.0.0.0", "--port", "8080"] Многоэтапная сборка (Multi-stage build):Критически важна для production. Финальный образ не содержит инструментов сборки (gcc, make, pip), что уменьшает размер и поверхность атаки: # ===== ЭТАП 1: Сборка ===== FROM python:3.11 AS builder WORKDIR /build # Устанавливаем зависимости для сборки RUN apt-get update && apt-get install -y --no-install-recommends \ gcc \ libffi-dev \ && rm -rf /var/lib/apt/lists/* COPY requirements.txt . # Устанавливаем в отдельную директорию RUN pip install --no-cache-dir --prefix=/install -r requirements.txt # ===== ЭТАП 2: Production образ ===== FROM python:3.11-slim AS production # Копируем только установленные пакеты из builder COPY --from=builder /install /usr/local WORKDIR /app # Только runtime зависимости ОС RUN apt-get update && apt-get install -y --no-install-recommends \ curl \ && rm -rf /var/lib/apt/lists/* \ && apt-get clean # Безопасность RUN groupadd -r app && useradd -r -g app -d /app -s /sbin/nologin app COPY --chown=app:app src/ ./src/ USER app ENV PYTHONUNBUFFERED=1 HEALTHCHECK --interval=30s --timeout=5s CMD curl -f http://localhost:8080/health CMD ["python", "src/main.py"] # Результат: образ ~180MB вместо ~900MB! .dockerignore — что НЕ копировать в образ:# .dockerignore **/__pycache__ **/*.pyc **/*.pyo .git .gitignore .venv venv *.env .env.* tests/ docs/ *.md .github/ node_modules/ dist/ *.log .DS_Store # Секреты — никогда в образ! *.key *.pem *secret* config.local.* Docker Compose: многосервисные приложенияDocker Compose — инструмент для запуска нескольких связанных контейнеров. Полный пример: IoT-платформа# docker-compose.yml version: '3.9' # Общие настройки через YAML anchors (DRY) x-common-env: &common-env TZ: Europe/Moscow LOG_LEVEL: ${LOG_LEVEL:-INFO} x-restart-policy: &restart-policy restart: unless-stopped services: # ===== MQTT БРОКЕР ===== mosquitto: image: eclipse-mosquitto:2.0.18 <<: *restart-policy volumes: - ./mosquitto/config:/mosquitto/config:ro - mosquitto_data:/mosquitto/data - mosquitto_logs:/mosquitto/log ports: - "1883:1883" # MQTT - "9001:9001" # WebSocket networks: - iot_network healthcheck: test: ["CMD", "mosquitto_sub", "-t", "$$SYS/#", "-C", "1", "-i", "healthcheck"] interval: 30s timeout: 10s retries: 3 # ===== БАЗА ДАННЫХ ВРЕМЕННЫХ РЯДОВ ===== influxdb: image: influxdb:2.7 <<: *restart-policy environment: <<: *common-env DOCKER_INFLUXDB_INIT_MODE: setup DOCKER_INFLUXDB_INIT_USERNAME: ${INFLUX_USER:-admin} DOCKER_INFLUXDB_INIT_PASSWORD: ${INFLUX_PASSWORD:?INFLUX_PASSWORD required} DOCKER_INFLUXDB_INIT_ORG: factory DOCKER_INFLUXDB_INIT_BUCKET: telemetry DOCKER_INFLUXDB_INIT_RETENTION: 30d DOCKER_INFLUXDB_INIT_ADMIN_TOKEN: ${INFLUX_TOKEN:?INFLUX_TOKEN required} volumes: - influxdb_data:/var/lib/influxdb2 - influxdb_config:/etc/influxdb2 ports: - "8086:8086" networks: - iot_network - monitoring_network healthcheck: test: ["CMD", "curl", "-f", "http://localhost:8086/health"] interval: 30s timeout: 10s retries: 5 start_period: 30s # ===== GRAFANA ===== grafana: image: grafana/grafana:10.3.1 <<: *restart-policy depends_on: influxdb: condition: service_healthy environment: <<: *common-env GF_SECURITY_ADMIN_USER: ${GF_ADMIN_USER:-admin} GF_SECURITY_ADMIN_PASSWORD: ${GF_ADMIN_PASSWORD:?required} GF_SERVER_ROOT_URL: http://localhost:3000 GF_SMTP_ENABLED: "true" GF_SMTP_HOST: ${SMTP_HOST:-localhost:25} volumes: - grafana_data:/var/lib/grafana - ./grafana/provisioning:/etc/grafana/provisioning:ro - ./grafana/dashboards:/var/lib/grafana/dashboards:ro ports: - "3000:3000" networks: - monitoring_network user: "472" # grafana user # ===== IOT ШЛЮЗ (наш сервис) ===== gateway: build: context: . dockerfile: Dockerfile target: production args: BUILD_DATE: ${BUILD_DATE:-unknown} GIT_COMMIT: ${GIT_COMMIT:-unknown} <<: *restart-policy depends_on: mosquitto: condition: service_healthy influxdb: condition: service_healthy environment: <<: *common-env MQTT_HOST: mosquitto # Имя сервиса = DNS-имя внутри сети! MQTT_PORT: 1883 INFLUX_URL: http://influxdb:8086 INFLUX_TOKEN: ${INFLUX_TOKEN} INFLUX_ORG: factory INFLUX_BUCKET: telemetry MODBUS_PORT: /dev/ttyUSB0 # Реальный порт с хоста volumes: - ./config:/app/config:ro - gateway_logs:/app/logs devices: - "/dev/ttyUSB0:/dev/ttyUSB0" # Проброс USB-устройства ports: - "8080:8080" networks: - iot_network - monitoring_network deploy: resources: limits: cpus: '1.0' memory: 512M reservations: cpus: '0.25' memory: 128M # ===== NGINX: реверс-прокси ===== nginx: image: nginx:1.25-alpine <<: *restart-policy depends_on: - grafana - gateway volumes: - ./nginx/nginx.conf:/etc/nginx/nginx.conf:ro - ./nginx/ssl:/etc/nginx/ssl:ro # TLS сертификаты ports: - "80:80" - "443:443" networks: - monitoring_network # ===== ТОМА ===== volumes: mosquitto_data: mosquitto_logs: influxdb_data: influxdb_config: grafana_data: gateway_logs: # ===== СЕТИ ===== networks: iot_network: # Для IoT-компонентов driver: bridge monitoring_network: # Для мониторинга и UI driver: bridge .env файл для Compose:# .env — НЕ коммитить в git! INFLUX_USER=admin INFLUX_PASSWORD=super_secret_influx_pass INFLUX_TOKEN=my-super-secret-token-change-this GF_ADMIN_USER=admin GF_ADMIN_PASSWORD=super_secret_grafana_pass LOG_LEVEL=INFO BUILD_DATE=2024-03-15 GIT_COMMIT=abc123 Docker: ключевые команды# ===== ОБРАЗЫ ===== docker build -t myapp:1.0 . # Собрать образ docker build --no-cache -t myapp:1.0 . # Без кеша docker images # Список образов docker rmi myapp:1.0 # Удалить образ docker image prune # Удалить неиспользуемые # История слоёв (анализ размера): docker history myapp:1.0 # ===== КОНТЕЙНЕРЫ ===== docker run -d \ --name gateway \ -p 8080:8080 \ -e MQTT_HOST=192.168.1.100 \ -v $(pwd)/config:/app/config:ro \ --restart unless-stopped \ myapp:1.0 docker ps # Запущенные контейнеры docker ps -a # Все (включая остановленные) docker logs gateway -f # Логи в реальном времени docker logs gateway --tail 100 # Последние 100 строк docker exec -it gateway bash # Войти внутрь контейнера docker stop gateway # Остановить docker start gateway # Запустить docker restart gateway # Перезапустить docker rm gateway # Удалить (сначала stop) docker stats # Потребление ресурсов # ===== COMPOSE ===== docker compose up -d # Запустить все сервисы docker compose up -d gateway # Запустить только gateway docker compose down # Остановить и удалить контейнеры docker compose down -v # + удалить тома (ОСТОРОЖНО!) docker compose logs -f # Логи всех сервисов docker compose logs -f gateway # Логи конкретного сервиса docker compose ps # Статус сервисов docker compose pull # Обновить образы docker compose build --no-cache # Пересобрать docker compose restart gateway # Перезапустить сервис docker compose exec gateway bash # Войти в контейнер # ===== REGISTRY ===== docker tag myapp:1.0 ghcr.io/myorg/myapp:1.0 docker push ghcr.io/myorg/myapp:1.0 docker pull ghcr.io/myorg/myapp:1.0 # ===== ОЧИСТКА ===== docker system prune -a # Удалить ВСЁ неиспользуемое docker volume prune # Удалить неиспользуемые тома Volumes и persistence: не теряем данные# Типы монтирования: services: app: volumes: # 1. Named Volume (рекомендуется для данных БД) - db_data:/var/lib/postgresql/data # 2. Bind Mount (для конфигов и разработки) - ./config:/app/config:ro # :ro = read-only - ./src:/app/src # Для hot-reload при разработке # 3. tmpfs (только в RAM, для временных данных) - type: tmpfs target: /tmp tmpfs: size: 100M volumes: db_data: driver: local # Для production: внешние тома # external: true # name: prod_db_data Backup томов:# Резервная копия тома influxdb_data docker run --rm \ -v influxdb_data:/source:ro \ -v $(pwd)/backups:/backup \ alpine:3 \ tar czf /backup/influxdb_$(date +%Y%m%d).tar.gz -C /source . # Восстановление docker run --rm \ -v influxdb_data:/target \ -v $(pwd)/backups:/backup:ro \ alpine:3 \ tar xzf /backup/influxdb_20240315.tar.gz -C /target Оптимизация размера образа# ❌ ПЛОХО: большой образ FROM ubuntu:22.04 RUN apt-get update RUN apt-get install -y python3 RUN apt-get install -y python3-pip RUN pip3 install flask COPY app.py . CMD ["python3", "app.py"] # Размер: ~480 МБ, 5 лишних слоёв # ✅ ХОРОШО: оптимизированный образ FROM python:3.11-slim RUN pip install --no-cache-dir flask COPY app.py . CMD ["python", "app.py"] # Размер: ~85 МБ, чистая сборка # ✅ ЕЩЁ ЛУЧШЕ: alpine (минимальный дистрибутив) FROM python:3.11-alpine # Некоторые C-расширения нужно собирать RUN apk add --no-cache gcc musl-dev && \ pip install --no-cache-dir flask && \ apk del gcc musl-dev COPY app.py . CMD ["python", "app.py"] # Размер: ~45 МБ Правило минимума слоёв для apt/apk: # Объединяйте RUN команды в одну для минимизации слоёв RUN apt-get update && \ apt-get install -y --no-install-recommends \ curl \ libpq5 \ && rm -rf /var/lib/apt/lists/* \ && apt-get clean # ОДИН слой вместо нескольких, и сразу очистка кеша Безопасность Docker1. Никогда не запускать от root:# Создаём непривилегированного пользователя RUN addgroup -S appgroup && adduser -S appuser -G appgroup USER appuser 2. Read-only файловая система:services: app: read_only: true # Файловая система только для чтения tmpfs: - /tmp # Разрешаем запись только в tmpfs - /var/run 3. Ограничение capabilities:services: app: cap_drop: - ALL # Убираем ВСЕ capabilities cap_add: - NET_BIND_SERVICE # Добавляем только необходимые 4. Сканирование образов на уязвимости:# Trivy — бесплатный сканер (Aqua Security) docker run --rm aquasec/trivy image myapp:1.0 # Или встроенный Docker Scout docker scout cves myapp:1.0 5. Secrets — не в переменных окружения production:# docker-compose.yml с Docker secrets services: app: secrets: - db_password - api_key environment: DB_PASSWORD_FILE: /run/secrets/db_password # Читаем из файла! secrets: db_password: file: ./secrets/db_password.txt # или external: true для Swarm/K8s Healthcheck и зависимости между сервисамиservices: postgres: image: postgres:15 healthcheck: test: ["CMD-SHELL", "pg_isready -U ${POSTGRES_USER}"] interval: 10s timeout: 5s retries: 5 start_period: 30s # Даём время на инициализацию app: depends_on: postgres: condition: service_healthy # Ждём пока postgres healthy! redis: condition: service_healthy Entrypoint-скрипт для ожидания зависимостей:#!/bin/sh # entrypoint.sh set -e echo "Ожидание готовности базы данных..." until nc -z -w5 ${DB_HOST} ${DB_PORT}; do echo "База данных недоступна, ждём..." sleep 2 done echo "База данных готова!" # Запуск миграций python manage.py migrate --no-input # Запуск приложения exec "$@" COPY entrypoint.sh /entrypoint.sh RUN chmod +x /entrypoint.sh ENTRYPOINT ["/entrypoint.sh"] CMD ["gunicorn", "app:application"] Docker в CI/CD (GitHub Actions)# .github/workflows/docker.yml name: Build and Deploy on: push: tags: ['v*.*.*'] jobs: build-push: runs-on: ubuntu-latest permissions: contents: read packages: write steps: - uses: actions/checkout@v4 - name: Set up Docker Buildx uses: docker/setup-buildx-action@v3 - name: Login to GitHub Container Registry uses: docker/login-action@v3 with: registry: ghcr.io username: ${{ github.actor }} password: ${{ secrets.GITHUB_TOKEN }} - name: Build and push uses: docker/build-push-action@v5 with: context: . platforms: linux/amd64,linux/arm64 # Multi-arch! push: true tags: | ghcr.io/${{ github.repository }}:${{ github.ref_name }} ghcr.io/${{ github.repository }}:latest cache-from: type=gha cache-to: type=gha,mode=max build-args: | GIT_COMMIT=${{ github.sha }} BUILD_DATE=${{ github.event.head_commit.timestamp }} deploy: needs: build-push runs-on: ubuntu-latest environment: production steps: - name: Deploy to server uses: appleboy/ssh-action@v1 with: host: ${{ secrets.SERVER_HOST }} username: deploy key: ${{ secrets.SERVER_SSH_KEY }} script: | cd /opt/iot-platform # Обновляем образ docker compose pull gateway # Обновляем с нулевым downtime docker compose up -d --no-deps gateway # Ждём healthcheck sleep 15 docker compose ps gateway | grep -q "healthy" || exit 1 echo "Деплой успешен!" Заключение: когда Docker, когда нетИспользуйте Docker: Приложения с множеством зависимостей Многосервисные приложения (backend + БД + брокер + мониторинг) CI/CD с гарантированной воспроизводимостью Несколько приложений на одном сервере Нужна возможность быстрого масштабирования Не обязательно Docker: Простые скрипты без зависимостей Приложения с прямым доступом к оборудованию (хотя --device помогает) Жёсткое реальное время (latency контейнера ~1 мкс, но это не ноль) Команда незнакома с Docker — сначала обучение, потом внедрение Docker — это не серебряная пуля, но инвестиция в него окупается быстро. Начните с docker-compose.yml для локальной разработки — уже это даст ощутимый результат: одна команда docker compose up поднимает весь стек вместо часа настройки. -
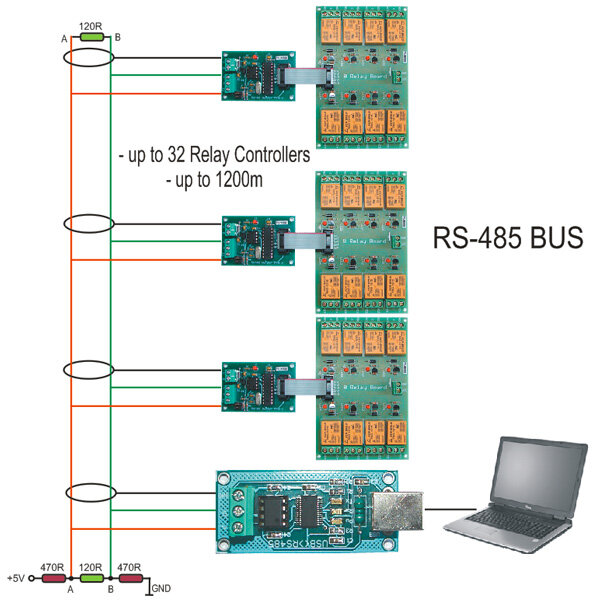 Почему RS-485, а не что-то современноеКаждый год появляются новые промышленные протоколы: EtherCAT, PROFINET, IO-Link, TSN. Но RS-485 не умирает. По данным IHS Markit, ежегодно продаётся более 1 миллиарда чипов RS-485. Новые установки продолжают использовать этот интерфейс. Причины живучести просты: Дешевизна: кабель — витая пара $0.1/м, трансивер MAX485 — $0.3 Надёжность: дифференциальный сигнал устойчив к помехам, работает на расстояниях до 1200 м Простота: понять и реализовать RS-485 можно за один день Совместимость: поддерживается абсолютно всеми промышленными устройствами Modbus RTU, BACnet MS/TP, DMX512, DALI — всё это работает поверх RS-485. Если вы занимаетесь промышленной автоматизацией, знание RS-485 обязательно. Сравнение: RS-232 vs RS-485Параметр RS-232 RS-485 Тип сигнала Однополярный, ±3–15В Дифференциальный, ±200мВ–5В Количество устройств 1:1 (точка-точка) 1:32 без репитеров (до 247 с) Максимальное расстояние 15 м 1200 м Скорость До 115 200 бод (практически) До 10 Мбит/с (при короткой линии) Устойчивость к помехам Низкая Высокая Дуплекс Полный (отдельные TX/RX) Полу (одна пара) или полный (2 пары) Применение Отладка, локальные устройства Промышленные сети, длинные линии Физический уровень: как работает дифференциальный сигналRS-485 использует дифференциальную пару проводников A и B: Состояние MARK (логическая 1, рецессивное): A > B: разность (A-B) = +200мВ...+5В Состояние SPACE (логическая 0, доминантное): B > A: разность (B-A) = +200мВ...+5В, то есть (A-B) = -200мВ...-5В Типичное напряжение при передаче: A ≈ +3.5В, B ≈ -3.5В → разность = +7В (гарантированная "1") A ≈ -3.5В, B ≈ +3.5В → разность = -7В (гарантированная "0") Устойчивость к синфазным помехам: Помеха +5В добавляется на ОБА провода: A = +3.5 + 5 = +8.5В, B = -3.5 + 5 = +1.5В Разность = +8.5 - 1.5 = +7В — сигнал не изменился! Пороги приёмника: если разность (A-B) > +200мВ — принимает "1"; если (A-B) < -200мВ — принимает "0". Диапазон ±200мВ — мёртвая зона (неопределённость). Выбор трансивера RS-485Бюджетные (для начала):MAX485 / MAX485E (Maxim) Самый популярный, $0.3–0.5 Полудуплекс, 2.5 Мбит/с Нет защиты от ESD (добавьте TVS-диоды!) Нет защиты от перегрева Питание 5В SP3485 (Sipex/Exar) Клон MAX485, питание 3.3В Совместимость с STM32, ESP32 напрямую (5В-tolerant входы) Профессиональные (для промышленности):MAX3485 / MAX3488 Расширенный диапазон ESD: ±15 кВ (HBM) Работает от 3.3В SN65HVD1780 (Texas Instruments) Встроенная защита от отказа шины (failsafe) ESD: ±16 кВ IEC 61000-4-2 Для жёстких промышленных условий ADM2587E (Analog Devices) Встроенная гальваническая изоляция 2500 VRMS Изолированный DC-DC для питания изолированной стороны Для применений с разным заземлением узлов Схема подключения: правильно и неправильноМинимальная схема (Arduino + MAX485):Arduino MAX485 RS-485 шина TX ─────────── DI RX ─────────── RO D2 ────┬────── DE A ──── Шина A └────── RE_ B ──── Шина B GND ─────────── GND GND ── Общий провод (обязательно!) 5V ──────────── Vcc Резисторы на шине: A ──[120 Ом]── B ← Терминатор на каждом конце шины Pullup/Pulldown для определённого состояния в паузах: +5В ──[560 Ом]── A ← Pull-up B ──[560 Ом]── GND ← Pull-down Ключевые правила:✅ ПРАВИЛЬНО: [Устройство A]──────[Устройство B]──────[Устройство C] [Term 120Ом] [Term 120Ом] Строго линейная шина, терминаторы только на концах ❌ НЕПРАВИЛЬНО — "звезда": [Устройство A] │ [Уст.B]──[Hub]──[Уст.C] │ [Устройство D] Отражения на каждом разветвлении разрушат сигнал! ❌ НЕПРАВИЛЬНО — терминаторы не там: [Term]──[Уст.A]──[Уст.B]──[Term]──[Уст.C] Терминатор посередине создаёт проблемы! Допустимые ответвления (stub):Короткие отводы от основной шины допустимы при условии: Длина stub < λ/10, где λ — длина волны на рабочей скорости При 9600 бод: λ ≈ 12 км → stub до 1200 м (практически неограничен) При 115200 бод: stub не более 1 м При 1 Мбит/с: stub не более 15 см! Управление направлением передачиRS-485 в полудуплексном режиме требует переключения между передачей и приёмом через сигнал DE/RE: // Arduino: управление направлением через GPIO #define RS485_DE_RE_PIN 2 #define RS485_BAUDRATE 9600 void rs485_init() { Serial.begin(RS485_BAUDRATE); pinMode(RS485_DE_RE_PIN, OUTPUT); rs485_receive_mode(); // По умолчанию — приём } void rs485_receive_mode() { digitalWrite(RS485_DE_RE_PIN, LOW); // DE=0, RE=0 → приём } void rs485_transmit_mode() { digitalWrite(RS485_DE_RE_PIN, HIGH); // DE=1, RE=1 → передача } void rs485_send(uint8_t *data, uint8_t len) { rs485_transmit_mode(); Serial.write(data, len); Serial.flush(); // ЖДЁМ пока все байты уйдут в UART TX буфер! // После flush() данные ещё в UART, нужно дождаться физической передачи // Расчёт времени: N_байт × 10_бит / baudrate uint32_t delay_us = (uint32_t)len * 10 * 1000000UL / RS485_BAUDRATE + 100; delayMicroseconds(delay_us); rs485_receive_mode(); } Аппаратное управление DE/RE (лучше!):На STM32 USART имеет аппаратный сигнал DE для RS-485. Переключение происходит автоматически — с точностью до такта, без программных задержек: // STM32 HAL: аппаратное управление DE через USART // В CubeMX: USART → Mode = Asynchronous, Hardware Flow Control = RS-485 Driver Enable // CubeMX настроит: // huart2.AdvancedInit.AdvFeatureInit = UART_ADVFEATURE_DE_INIT; // huart2.AdvancedInit.DEPolarity = UART_DE_POLARITY_HIGH; // huart2.AdvancedInit.DEAssertionTime = 16; // тактов предвключения // huart2.AdvancedInit.DEDeassertionTime = 16; // тактов послевыключения // После этого просто передаём — DE управляется автоматически! HAL_UART_Transmit(&huart2, data, len, 100); // STM32 сам поднял DE перед передачей и снял после! Расчёт нагрузки на шинуRS-485 трансивер создаёт нагрузку на шину. Стандарт RS-485 определяет "единицу нагрузки" (Unit Load, UL) = 12 кОм. Драйвер должен обеспечить минимум 32 UL. Это значит: максимум 32 "классических" устройства на шине. Современные трансиверы с низким потреблением имеют 1/8 UL или 1/4 UL: Тип трансивера Нагрузка Устройств на шине Стандартный (MAX485) 1 UL 32 1/2 UL (MAX3430) 0.5 UL 64 1/4 UL (MAX3471) 0.25 UL 128 1/8 UL (MAX3491) 0.125 UL 256 Также нагрузку создают терминирующие резисторы: 2 × 120 Ом = 60 Ом = 200 UL (!) — это доминирующая нагрузка Учитывайте это при расчёте суммарной нагрузки Кабель: выбор и прокладкаТребования к кабелю RS-485:Обязательно: Витая пара (не просто два провода!) Волновое сопротивление 120 Ом (терминируется парными резисторами 120 Ом) Рекомендуемые типы кабелей: КВВГЭ 1×2×0.75 — отечественный, экранированная витая пара Belden 9842 — американский стандарт, 120 Ом, двойной экран LiYCY 2×0.5 мм² — гибкий, для подвижных установок Cat5e / Cat6 — работает! (120 Ом, но без промышленной изоляции) Сечение проводника:Падение напряжения на кабеле: ΔU = 2 × R_кабеля × I_нагрузка R = ρ × L / S = 0.0175 (Ом·мм²/м) × 1000 м / 0.5 мм² = 35 Ом При токе утечки 100 мА: ΔU = 2 × 35 × 0.1 = 7В — это уже критично! Для длинных линий выбирайте кабель 1.0 мм² и более. Экранирование:Правила заземления экрана: ✅ Заземлять в ОДНОЙ точке — предотвращает контурные токи Обычно: на стороне мастера/ПЛК ❌ Заземлять с ОБОИХ концов — контурный ток протекает по экрану! При разных потенциалах земли создаёт синфазные помехи. Исключение: при частотах > 100 кГц экран заземляют с обоих концов (через конденсатор 10 нФ с одной стороны). Практика: полный пример Modbus RTU на Pythonimport serial import struct import time from typing import Optional class RS485Master: """ Мастер RS-485 с ручным управлением DE/RE через GPIO (для Raspberry Pi). Или с автоматическим через RTS (для USB-RS485 адаптеров). """ def __init__(self, port: str, baudrate: int = 9600, use_rts: bool = True, rts_level: bool = True): """ port: '/dev/ttyUSB0', 'COM3' и т.д. use_rts: использовать RTS для управления DE/RE (USB-адаптеры) rts_level: уровень RTS при передаче (True = HIGH) """ self.ser = serial.Serial( port = port, baudrate = baudrate, bytesize = serial.EIGHTBITS, parity = serial.PARITY_NONE, stopbits = serial.STOPBITS_ONE, timeout = 0.1 ) if use_rts: self.ser.rts = not rts_level # Начальное состояние — приём self.use_rts = use_rts self.rts_level = rts_level # Время передачи одного символа (для задержки после отправки) self.char_time = 10.0 / baudrate # 10 бит на символ def _tx_enable(self): if self.use_rts: self.ser.rts = self.rts_level time.sleep(0.0001) # 100 мкс предвключение def _rx_enable(self): if self.use_rts: # Ждём физической передачи последнего байта time.sleep(self.char_time) self.ser.rts = not self.rts_level def _crc16(self, data: bytes) -> int: crc = 0xFFFF for byte in data: crc ^= byte for _ in range(8): crc = (crc >> 1) ^ 0xA001 if crc & 1 else crc >> 1 return crc def send_raw(self, data: bytes): """Отправка сырых данных""" self.ser.reset_input_buffer() # Очищаем входной буфер перед отправкой self._tx_enable() self.ser.write(data) self.ser.flush() self._rx_enable() def recv_raw(self, expected_len: int, timeout: float = 0.5) -> Optional[bytes]: """Приём данных с таймаутом""" deadline = time.time() + timeout buf = b'' while time.time() < deadline: chunk = self.ser.read(expected_len - len(buf)) buf += chunk if len(buf) >= expected_len: break time.sleep(0.001) return buf if len(buf) == expected_len else None def modbus_read_registers(self, slave: int, func: int, start_addr: int, count: int) -> Optional[list]: """ Чтение Holding (FC=3) или Input (FC=4) регистров. Возвращает список значений или None при ошибке. """ # Формируем запрос request = struct.pack('>BBHH', slave, func, start_addr, count) crc = self._crc16(request) request += struct.pack('<H', crc) # CRC little-endian! self.send_raw(request) # Ожидаемый размер ответа: addr(1)+fc(1)+byte_count(1)+data(count×2)+crc(2) expected = 5 + count * 2 response = self.recv_raw(expected) if response is None: return None # Таймаут # Проверка CRC recv_crc = struct.unpack('<H', response[-2:])[0] calc_crc = self._crc16(response[:-2]) if recv_crc != calc_crc: return None # CRC ошибка # Проверка Exception if response[1] & 0x80: exc_code = response[2] print(f"Modbus Exception: slave={slave}, code={exc_code}") return None # Распаковываем данные byte_count = response[2] values = list(struct.unpack(f'>{count}H', response[3:3+byte_count])) return values def modbus_write_register(self, slave: int, addr: int, value: int) -> bool: """Запись одного Holding регистра (FC=6)""" request = struct.pack('>BBHH', slave, 6, addr, value) crc = self._crc16(request) request += struct.pack('<H', crc) self.send_raw(request) # Ответ = эхо запроса (8 байт) response = self.recv_raw(8) if response is None: return False recv_crc = struct.unpack('<H', response[-2:])[0] return recv_crc == self._crc16(response[:-2]) def close(self): self.ser.close() # ===== ПРИМЕР ИСПОЛЬЗОВАНИЯ ===== def demo_poll_vfd(): """Опрос частотника по Modbus RTU через RS-485""" master = RS485Master('/dev/ttyUSB0', baudrate=9600, use_rts=True) try: print("Опрос частотника (адрес 1)...") while True: # Читаем 6 Input регистров: статус, частота, ток, напряжение, мощность, fault regs = master.modbus_read_registers(slave=1, func=4, start_addr=0, count=6) if regs is None: print("Нет ответа от устройства") else: status = regs[0] freq_hz = regs[1] / 100.0 curr_a = regs[2] / 10.0 volts = regs[3] power_kw = regs[4] / 10.0 fault = regs[5] running = bool(status & 0x0001) faulted = bool(status & 0x0008) print(f"{'▶ ' if running else '⏹'} " f"f={freq_hz:.1f}Гц " f"I={curr_a:.1f}А " f"U={volts}В " f"P={power_kw:.1f}кВт " f"{'🔴АВАРИЯ' if faulted else ''}") if faulted: print(f"Код аварии: {fault}") time.sleep(1.0) except KeyboardInterrupt: print("Остановлено") finally: master.close() demo_poll_vfd() Диагностика: осциллограф и мультиметрИзмерения мультиметром:Линия A-B без сигнала (все устройства молчат): Должно быть: A > B на 200мВ+ (если есть pull-up/down) Плохо: A = B (неопределённое состояние — нужны резисторы смещения) Во время передачи: Осциллограф: чёткие уровни ±3..4В, без выбросов Плохо: размытые фронты → слишком длинная линия или нет терминаторов Плохо: выбросы >±7В → нет снаббера или плохое заземление Измерение дифференциального сигнала: Щуп A → канал 1, Щуп B → канал 2 Включить Math: CH1 - CH2 Должен быть чёткий прямоугольник ±(3..5)В Типичные осциллограммы проблем:Нет терминаторов: ┌──────┐ │ │ ← Нормальный фронт │ │╲ ← Отражение (заброс) ────┘ └─╲────── └── ← Повторное отражение Слишком длинный stub: ┌──────┐ │ ╲___/ ← Паразитное колебание после фронта ────┘ ──── Хорошая линия: ┌──────────┐ ────┘ └──── ← Чёткие фронты без выбросов Гальваническая развязка: когда обязательнаВ промышленных установках "земля" в разных точках может иметь разный потенциал — десятки и даже сотни вольт. Без развязки: Контурный ток по GND-проводу шины RS-485 разрушает трансиверы Помехи от силового оборудования проникают в логику Один неисправный узел выводит из строя всю сеть Когда нужна обязательно: Устройства питаются от разных источников Расстояние между устройствами > 50 м Рядом с шиной есть мощные электродвигатели или сварочное оборудование Разные здания или разные распределительные щиты Варианты реализации: Вариант 1: Изолированный трансивер (ADM2587E, ISO3082) UART ──[Изолированный трансивер]── RS-485 шина Встроенная изоляция 2500 VRMS, нет внешних компонентов Вариант 2: Оптопара + отдельный трансивер UART_TX ──[HCPL2630]── MAX485 ── RS-485 шина UART_RX ──[HCPL2630]──┘ Дешевле, но нужен изолированный DC-DC конвертер питания Вариант 3: Цифровой изолятор + трансивер UART ──[ISO7720]── MAX485 ── RS-485 шина ISO7720: 5 кВ изоляция, 100 Мбит/с, без светодиодов (долговечнее оптопар) Число устройств больше 32: репитеры и конвертерыЕсли нужно более 32 устройств или протяжённость линии превышает допустимую: Репитер RS-485: [Сегмент 1: 32 уст., 600 м]──[Репитер]──[Сегмент 2: 32 уст., 600 м] Репитер переусиливает и переформирует сигнал. Каждый сегмент — отдельная нагрузка. Популярные репитеры: - ADAM-4510 (Advantech): изолированный, DIN-рейка - Moxa MB-9000: с диагностикой - Homemade: MAX487 + MAX487 с DE/RE управлением Защита от грозовых разрядов и ESDПри длинных линиях между зданиями — молниезащита обязательна: Схема защиты RS-485 линии: RS-485 Шина ──[Предохранитель]──[GDT или MOV]──[TVS-диод]──[Трансивер] A P6KE6.8CA Уровни защиты: 1. GDT (газоразрядник) или MOV: ограничивают до 100..500В за наносекунды 2. TVS-диод P6KE6.8CA: ограничивает до ±6.8В, рассеивает 600 Вт импульсно 3. Последовательный резистор 10..22 Ом: ограничивает ток через TVS Готовые модули молниезащиты RS-485: - MTL5000: промышленный барьер - Phoenix Contact TRABTECH: DIN-рейка - УЗИП-485 (отечественный): Microsemi/аналоги Частые вопросы и ответыQ: Можно ли использовать обычный кабель UTP Cat5e вместо специального? A: Можно, и это работает на практике. Cat5e имеет волновое сопротивление 100 Ом (термinator нужен 100 Ом), паразитные ёмкости немного хуже. До 300м/115200 бод — без проблем. Но в промышленной среде с помехами — лучше экранированный кабель. Q: Нужен ли третий провод GND? A: Для корректной работы трансивера входная синфазная помеха не должна выходить за пределы -7В...+12В (Vcm). При длинных линиях и разных заземлениях это нарушается. GND-провод удерживает синфазное напряжение в пределах допустимого. Включайте GND во все промышленные установки. Q: У устройства нет RS-485, только UART. Как подключить? A: Добавить внешний трансивер MAX485/SP3485 + резистор 300 Ом на DE/RE от GPIO. Q: Что делать если устройства разных производителей не видят друг друга? A: Проверить: 1) Скорость/parity/stopbits совпадают. 2) Полярность A/B (иногда производители маркируют наоборот). 3) Адреса устройств уникальны. 4) Нет конфликта адресов. ЗаключениеRS-485 — это не устаревший протокол, а надёжный, проверенный инструмент для промышленных приложений. Правильная линейная топология с терминаторами, экранированная витая пара, правильное управление DE/RE и гальваническая развязка там, где нужно — всё это обеспечит годы надёжной работы. Вложите время в понимание физического уровня: осциллограф + хорошая книга по физике передачи сигналов. Большинство проблем RS-485 решаются на физическом уровне, а не в программе.
Почему RS-485, а не что-то современноеКаждый год появляются новые промышленные протоколы: EtherCAT, PROFINET, IO-Link, TSN. Но RS-485 не умирает. По данным IHS Markit, ежегодно продаётся более 1 миллиарда чипов RS-485. Новые установки продолжают использовать этот интерфейс. Причины живучести просты: Дешевизна: кабель — витая пара $0.1/м, трансивер MAX485 — $0.3 Надёжность: дифференциальный сигнал устойчив к помехам, работает на расстояниях до 1200 м Простота: понять и реализовать RS-485 можно за один день Совместимость: поддерживается абсолютно всеми промышленными устройствами Modbus RTU, BACnet MS/TP, DMX512, DALI — всё это работает поверх RS-485. Если вы занимаетесь промышленной автоматизацией, знание RS-485 обязательно. Сравнение: RS-232 vs RS-485Параметр RS-232 RS-485 Тип сигнала Однополярный, ±3–15В Дифференциальный, ±200мВ–5В Количество устройств 1:1 (точка-точка) 1:32 без репитеров (до 247 с) Максимальное расстояние 15 м 1200 м Скорость До 115 200 бод (практически) До 10 Мбит/с (при короткой линии) Устойчивость к помехам Низкая Высокая Дуплекс Полный (отдельные TX/RX) Полу (одна пара) или полный (2 пары) Применение Отладка, локальные устройства Промышленные сети, длинные линии Физический уровень: как работает дифференциальный сигналRS-485 использует дифференциальную пару проводников A и B: Состояние MARK (логическая 1, рецессивное): A > B: разность (A-B) = +200мВ...+5В Состояние SPACE (логическая 0, доминантное): B > A: разность (B-A) = +200мВ...+5В, то есть (A-B) = -200мВ...-5В Типичное напряжение при передаче: A ≈ +3.5В, B ≈ -3.5В → разность = +7В (гарантированная "1") A ≈ -3.5В, B ≈ +3.5В → разность = -7В (гарантированная "0") Устойчивость к синфазным помехам: Помеха +5В добавляется на ОБА провода: A = +3.5 + 5 = +8.5В, B = -3.5 + 5 = +1.5В Разность = +8.5 - 1.5 = +7В — сигнал не изменился! Пороги приёмника: если разность (A-B) > +200мВ — принимает "1"; если (A-B) < -200мВ — принимает "0". Диапазон ±200мВ — мёртвая зона (неопределённость). Выбор трансивера RS-485Бюджетные (для начала):MAX485 / MAX485E (Maxim) Самый популярный, $0.3–0.5 Полудуплекс, 2.5 Мбит/с Нет защиты от ESD (добавьте TVS-диоды!) Нет защиты от перегрева Питание 5В SP3485 (Sipex/Exar) Клон MAX485, питание 3.3В Совместимость с STM32, ESP32 напрямую (5В-tolerant входы) Профессиональные (для промышленности):MAX3485 / MAX3488 Расширенный диапазон ESD: ±15 кВ (HBM) Работает от 3.3В SN65HVD1780 (Texas Instruments) Встроенная защита от отказа шины (failsafe) ESD: ±16 кВ IEC 61000-4-2 Для жёстких промышленных условий ADM2587E (Analog Devices) Встроенная гальваническая изоляция 2500 VRMS Изолированный DC-DC для питания изолированной стороны Для применений с разным заземлением узлов Схема подключения: правильно и неправильноМинимальная схема (Arduino + MAX485):Arduino MAX485 RS-485 шина TX ─────────── DI RX ─────────── RO D2 ────┬────── DE A ──── Шина A └────── RE_ B ──── Шина B GND ─────────── GND GND ── Общий провод (обязательно!) 5V ──────────── Vcc Резисторы на шине: A ──[120 Ом]── B ← Терминатор на каждом конце шины Pullup/Pulldown для определённого состояния в паузах: +5В ──[560 Ом]── A ← Pull-up B ──[560 Ом]── GND ← Pull-down Ключевые правила:✅ ПРАВИЛЬНО: [Устройство A]──────[Устройство B]──────[Устройство C] [Term 120Ом] [Term 120Ом] Строго линейная шина, терминаторы только на концах ❌ НЕПРАВИЛЬНО — "звезда": [Устройство A] │ [Уст.B]──[Hub]──[Уст.C] │ [Устройство D] Отражения на каждом разветвлении разрушат сигнал! ❌ НЕПРАВИЛЬНО — терминаторы не там: [Term]──[Уст.A]──[Уст.B]──[Term]──[Уст.C] Терминатор посередине создаёт проблемы! Допустимые ответвления (stub):Короткие отводы от основной шины допустимы при условии: Длина stub < λ/10, где λ — длина волны на рабочей скорости При 9600 бод: λ ≈ 12 км → stub до 1200 м (практически неограничен) При 115200 бод: stub не более 1 м При 1 Мбит/с: stub не более 15 см! Управление направлением передачиRS-485 в полудуплексном режиме требует переключения между передачей и приёмом через сигнал DE/RE: // Arduino: управление направлением через GPIO #define RS485_DE_RE_PIN 2 #define RS485_BAUDRATE 9600 void rs485_init() { Serial.begin(RS485_BAUDRATE); pinMode(RS485_DE_RE_PIN, OUTPUT); rs485_receive_mode(); // По умолчанию — приём } void rs485_receive_mode() { digitalWrite(RS485_DE_RE_PIN, LOW); // DE=0, RE=0 → приём } void rs485_transmit_mode() { digitalWrite(RS485_DE_RE_PIN, HIGH); // DE=1, RE=1 → передача } void rs485_send(uint8_t *data, uint8_t len) { rs485_transmit_mode(); Serial.write(data, len); Serial.flush(); // ЖДЁМ пока все байты уйдут в UART TX буфер! // После flush() данные ещё в UART, нужно дождаться физической передачи // Расчёт времени: N_байт × 10_бит / baudrate uint32_t delay_us = (uint32_t)len * 10 * 1000000UL / RS485_BAUDRATE + 100; delayMicroseconds(delay_us); rs485_receive_mode(); } Аппаратное управление DE/RE (лучше!):На STM32 USART имеет аппаратный сигнал DE для RS-485. Переключение происходит автоматически — с точностью до такта, без программных задержек: // STM32 HAL: аппаратное управление DE через USART // В CubeMX: USART → Mode = Asynchronous, Hardware Flow Control = RS-485 Driver Enable // CubeMX настроит: // huart2.AdvancedInit.AdvFeatureInit = UART_ADVFEATURE_DE_INIT; // huart2.AdvancedInit.DEPolarity = UART_DE_POLARITY_HIGH; // huart2.AdvancedInit.DEAssertionTime = 16; // тактов предвключения // huart2.AdvancedInit.DEDeassertionTime = 16; // тактов послевыключения // После этого просто передаём — DE управляется автоматически! HAL_UART_Transmit(&huart2, data, len, 100); // STM32 сам поднял DE перед передачей и снял после! Расчёт нагрузки на шинуRS-485 трансивер создаёт нагрузку на шину. Стандарт RS-485 определяет "единицу нагрузки" (Unit Load, UL) = 12 кОм. Драйвер должен обеспечить минимум 32 UL. Это значит: максимум 32 "классических" устройства на шине. Современные трансиверы с низким потреблением имеют 1/8 UL или 1/4 UL: Тип трансивера Нагрузка Устройств на шине Стандартный (MAX485) 1 UL 32 1/2 UL (MAX3430) 0.5 UL 64 1/4 UL (MAX3471) 0.25 UL 128 1/8 UL (MAX3491) 0.125 UL 256 Также нагрузку создают терминирующие резисторы: 2 × 120 Ом = 60 Ом = 200 UL (!) — это доминирующая нагрузка Учитывайте это при расчёте суммарной нагрузки Кабель: выбор и прокладкаТребования к кабелю RS-485:Обязательно: Витая пара (не просто два провода!) Волновое сопротивление 120 Ом (терминируется парными резисторами 120 Ом) Рекомендуемые типы кабелей: КВВГЭ 1×2×0.75 — отечественный, экранированная витая пара Belden 9842 — американский стандарт, 120 Ом, двойной экран LiYCY 2×0.5 мм² — гибкий, для подвижных установок Cat5e / Cat6 — работает! (120 Ом, но без промышленной изоляции) Сечение проводника:Падение напряжения на кабеле: ΔU = 2 × R_кабеля × I_нагрузка R = ρ × L / S = 0.0175 (Ом·мм²/м) × 1000 м / 0.5 мм² = 35 Ом При токе утечки 100 мА: ΔU = 2 × 35 × 0.1 = 7В — это уже критично! Для длинных линий выбирайте кабель 1.0 мм² и более. Экранирование:Правила заземления экрана: ✅ Заземлять в ОДНОЙ точке — предотвращает контурные токи Обычно: на стороне мастера/ПЛК ❌ Заземлять с ОБОИХ концов — контурный ток протекает по экрану! При разных потенциалах земли создаёт синфазные помехи. Исключение: при частотах > 100 кГц экран заземляют с обоих концов (через конденсатор 10 нФ с одной стороны). Практика: полный пример Modbus RTU на Pythonimport serial import struct import time from typing import Optional class RS485Master: """ Мастер RS-485 с ручным управлением DE/RE через GPIO (для Raspberry Pi). Или с автоматическим через RTS (для USB-RS485 адаптеров). """ def __init__(self, port: str, baudrate: int = 9600, use_rts: bool = True, rts_level: bool = True): """ port: '/dev/ttyUSB0', 'COM3' и т.д. use_rts: использовать RTS для управления DE/RE (USB-адаптеры) rts_level: уровень RTS при передаче (True = HIGH) """ self.ser = serial.Serial( port = port, baudrate = baudrate, bytesize = serial.EIGHTBITS, parity = serial.PARITY_NONE, stopbits = serial.STOPBITS_ONE, timeout = 0.1 ) if use_rts: self.ser.rts = not rts_level # Начальное состояние — приём self.use_rts = use_rts self.rts_level = rts_level # Время передачи одного символа (для задержки после отправки) self.char_time = 10.0 / baudrate # 10 бит на символ def _tx_enable(self): if self.use_rts: self.ser.rts = self.rts_level time.sleep(0.0001) # 100 мкс предвключение def _rx_enable(self): if self.use_rts: # Ждём физической передачи последнего байта time.sleep(self.char_time) self.ser.rts = not self.rts_level def _crc16(self, data: bytes) -> int: crc = 0xFFFF for byte in data: crc ^= byte for _ in range(8): crc = (crc >> 1) ^ 0xA001 if crc & 1 else crc >> 1 return crc def send_raw(self, data: bytes): """Отправка сырых данных""" self.ser.reset_input_buffer() # Очищаем входной буфер перед отправкой self._tx_enable() self.ser.write(data) self.ser.flush() self._rx_enable() def recv_raw(self, expected_len: int, timeout: float = 0.5) -> Optional[bytes]: """Приём данных с таймаутом""" deadline = time.time() + timeout buf = b'' while time.time() < deadline: chunk = self.ser.read(expected_len - len(buf)) buf += chunk if len(buf) >= expected_len: break time.sleep(0.001) return buf if len(buf) == expected_len else None def modbus_read_registers(self, slave: int, func: int, start_addr: int, count: int) -> Optional[list]: """ Чтение Holding (FC=3) или Input (FC=4) регистров. Возвращает список значений или None при ошибке. """ # Формируем запрос request = struct.pack('>BBHH', slave, func, start_addr, count) crc = self._crc16(request) request += struct.pack('<H', crc) # CRC little-endian! self.send_raw(request) # Ожидаемый размер ответа: addr(1)+fc(1)+byte_count(1)+data(count×2)+crc(2) expected = 5 + count * 2 response = self.recv_raw(expected) if response is None: return None # Таймаут # Проверка CRC recv_crc = struct.unpack('<H', response[-2:])[0] calc_crc = self._crc16(response[:-2]) if recv_crc != calc_crc: return None # CRC ошибка # Проверка Exception if response[1] & 0x80: exc_code = response[2] print(f"Modbus Exception: slave={slave}, code={exc_code}") return None # Распаковываем данные byte_count = response[2] values = list(struct.unpack(f'>{count}H', response[3:3+byte_count])) return values def modbus_write_register(self, slave: int, addr: int, value: int) -> bool: """Запись одного Holding регистра (FC=6)""" request = struct.pack('>BBHH', slave, 6, addr, value) crc = self._crc16(request) request += struct.pack('<H', crc) self.send_raw(request) # Ответ = эхо запроса (8 байт) response = self.recv_raw(8) if response is None: return False recv_crc = struct.unpack('<H', response[-2:])[0] return recv_crc == self._crc16(response[:-2]) def close(self): self.ser.close() # ===== ПРИМЕР ИСПОЛЬЗОВАНИЯ ===== def demo_poll_vfd(): """Опрос частотника по Modbus RTU через RS-485""" master = RS485Master('/dev/ttyUSB0', baudrate=9600, use_rts=True) try: print("Опрос частотника (адрес 1)...") while True: # Читаем 6 Input регистров: статус, частота, ток, напряжение, мощность, fault regs = master.modbus_read_registers(slave=1, func=4, start_addr=0, count=6) if regs is None: print("Нет ответа от устройства") else: status = regs[0] freq_hz = regs[1] / 100.0 curr_a = regs[2] / 10.0 volts = regs[3] power_kw = regs[4] / 10.0 fault = regs[5] running = bool(status & 0x0001) faulted = bool(status & 0x0008) print(f"{'▶ ' if running else '⏹'} " f"f={freq_hz:.1f}Гц " f"I={curr_a:.1f}А " f"U={volts}В " f"P={power_kw:.1f}кВт " f"{'🔴АВАРИЯ' if faulted else ''}") if faulted: print(f"Код аварии: {fault}") time.sleep(1.0) except KeyboardInterrupt: print("Остановлено") finally: master.close() demo_poll_vfd() Диагностика: осциллограф и мультиметрИзмерения мультиметром:Линия A-B без сигнала (все устройства молчат): Должно быть: A > B на 200мВ+ (если есть pull-up/down) Плохо: A = B (неопределённое состояние — нужны резисторы смещения) Во время передачи: Осциллограф: чёткие уровни ±3..4В, без выбросов Плохо: размытые фронты → слишком длинная линия или нет терминаторов Плохо: выбросы >±7В → нет снаббера или плохое заземление Измерение дифференциального сигнала: Щуп A → канал 1, Щуп B → канал 2 Включить Math: CH1 - CH2 Должен быть чёткий прямоугольник ±(3..5)В Типичные осциллограммы проблем:Нет терминаторов: ┌──────┐ │ │ ← Нормальный фронт │ │╲ ← Отражение (заброс) ────┘ └─╲────── └── ← Повторное отражение Слишком длинный stub: ┌──────┐ │ ╲___/ ← Паразитное колебание после фронта ────┘ ──── Хорошая линия: ┌──────────┐ ────┘ └──── ← Чёткие фронты без выбросов Гальваническая развязка: когда обязательнаВ промышленных установках "земля" в разных точках может иметь разный потенциал — десятки и даже сотни вольт. Без развязки: Контурный ток по GND-проводу шины RS-485 разрушает трансиверы Помехи от силового оборудования проникают в логику Один неисправный узел выводит из строя всю сеть Когда нужна обязательно: Устройства питаются от разных источников Расстояние между устройствами > 50 м Рядом с шиной есть мощные электродвигатели или сварочное оборудование Разные здания или разные распределительные щиты Варианты реализации: Вариант 1: Изолированный трансивер (ADM2587E, ISO3082) UART ──[Изолированный трансивер]── RS-485 шина Встроенная изоляция 2500 VRMS, нет внешних компонентов Вариант 2: Оптопара + отдельный трансивер UART_TX ──[HCPL2630]── MAX485 ── RS-485 шина UART_RX ──[HCPL2630]──┘ Дешевле, но нужен изолированный DC-DC конвертер питания Вариант 3: Цифровой изолятор + трансивер UART ──[ISO7720]── MAX485 ── RS-485 шина ISO7720: 5 кВ изоляция, 100 Мбит/с, без светодиодов (долговечнее оптопар) Число устройств больше 32: репитеры и конвертерыЕсли нужно более 32 устройств или протяжённость линии превышает допустимую: Репитер RS-485: [Сегмент 1: 32 уст., 600 м]──[Репитер]──[Сегмент 2: 32 уст., 600 м] Репитер переусиливает и переформирует сигнал. Каждый сегмент — отдельная нагрузка. Популярные репитеры: - ADAM-4510 (Advantech): изолированный, DIN-рейка - Moxa MB-9000: с диагностикой - Homemade: MAX487 + MAX487 с DE/RE управлением Защита от грозовых разрядов и ESDПри длинных линиях между зданиями — молниезащита обязательна: Схема защиты RS-485 линии: RS-485 Шина ──[Предохранитель]──[GDT или MOV]──[TVS-диод]──[Трансивер] A P6KE6.8CA Уровни защиты: 1. GDT (газоразрядник) или MOV: ограничивают до 100..500В за наносекунды 2. TVS-диод P6KE6.8CA: ограничивает до ±6.8В, рассеивает 600 Вт импульсно 3. Последовательный резистор 10..22 Ом: ограничивает ток через TVS Готовые модули молниезащиты RS-485: - MTL5000: промышленный барьер - Phoenix Contact TRABTECH: DIN-рейка - УЗИП-485 (отечественный): Microsemi/аналоги Частые вопросы и ответыQ: Можно ли использовать обычный кабель UTP Cat5e вместо специального? A: Можно, и это работает на практике. Cat5e имеет волновое сопротивление 100 Ом (термinator нужен 100 Ом), паразитные ёмкости немного хуже. До 300м/115200 бод — без проблем. Но в промышленной среде с помехами — лучше экранированный кабель. Q: Нужен ли третий провод GND? A: Для корректной работы трансивера входная синфазная помеха не должна выходить за пределы -7В...+12В (Vcm). При длинных линиях и разных заземлениях это нарушается. GND-провод удерживает синфазное напряжение в пределах допустимого. Включайте GND во все промышленные установки. Q: У устройства нет RS-485, только UART. Как подключить? A: Добавить внешний трансивер MAX485/SP3485 + резистор 300 Ом на DE/RE от GPIO. Q: Что делать если устройства разных производителей не видят друг друга? A: Проверить: 1) Скорость/parity/stopbits совпадают. 2) Полярность A/B (иногда производители маркируют наоборот). 3) Адреса устройств уникальны. 4) Нет конфликта адресов. ЗаключениеRS-485 — это не устаревший протокол, а надёжный, проверенный инструмент для промышленных приложений. Правильная линейная топология с терминаторами, экранированная витая пара, правильное управление DE/RE и гальваническая развязка там, где нужно — всё это обеспечит годы надёжной работы. Вложите время в понимание физического уровня: осциллограф + хорошая книга по физике передачи сигналов. Большинство проблем RS-485 решаются на физическом уровне, а не в программе. -
Зовёшь коллегу показать проблему. Объясняешь. Показываешь. И… всё работает. Кажется, баги просто стесняются свидетелей.
-
Сидишь 3 часа — не понимаешь. Находишь — и думаешь: «ну это же очевидно». Через неделю: опять такой же баг. И снова «не очевидно».
-
Встретил в коде: // не трогать, всё сломается Конечно же, первое желание — проверить. Сломалось. Автор комментария: — я же говорил.
-
Исправил одну проблему. Появились три новые. Судя по динамике, если продолжать — можно создать новую вселенную. Кто-нибудь доводил это до конца?
-
Раньше говорили: «хороший разработчик — тот, кто умеет гуглить». Теперь: «тот, кто умеет правильно задать вопрос ИИ». Следующий этап: синьор — это тот, кто понимает, где ИИ врёт.
-
Замечал странную закономерность: пока смотришь на код — всё работает. Стоит отойти за кофе — падает. Есть гипотеза, что баги боятся зрительного контакта. Кто-нибудь пробовал фиксить прод просто пристальным взглядом?
-
Один язык везде — звучит идеально. Но event loop, блокировки, память… Подходит ли Node для серьёзных систем? Или это инструмент «для стартапов»?
-
Раньше HTML+CSS+JS. Теперь сборщики, фреймворки, стейт-менеджмент. Фронт превратился в отдельную инженерную дисциплину. Это оправдано или перегруз?
-
ORM экономит время. Но потом начинаются странные SQL-запросы и проблемы с производительностью. Стоит ли сразу писать «чистый SQL»? Или ORM — это нормальный компромисс?
-
Все хотят микросервисы. Но у маленьких команд это превращается в хаос. Сеть, деплой, логирование — всё усложняется. Может, старый добрый монолит недооценён?
-
Контейнеры — стандарт индустрии. Но теперь вместо «у меня не работает» → «у меня не работает в контейнере». Сложность только растёт. Docker — необходимость или оверинжиниринг?
-
Асинхронность упростили, но стало ли реально проще? Ошибки «проглатываются», порядок выполнения неочевиден. Особенно в Python и JS. Стоит ли возвращаться к более явным моделям?
-
Фронт, бэк, мобильные приложения — всё на JS. Но сколько боли: npm, зависимости, ломающееся окружение. Почему язык, который задумывался как скриптовый, стал основой всего? Это эволюция или архитектурная ошибка?
-
Всегда любил Python за простоту. Но в последние годы ощущение, что он стал слишком «тяжёлым». Типизация, async, куча фреймворков — и вот уже проект сложнее, чем на Java. В какой момент Python перестаёт быть удобным инструментом? Или проблема в нас, а не в языке?